之前用scrapy爬取了知乎用户数据,由于数据量很大,便考虑采取分布式提升爬取效率,便有的此文。爬虫源码为https://pan.baidu.com/s/1mCK8mosshkkb1Vx9sVDEGg,读者自行下载,接下来进入主题:
前期准备:我们分别需要在主机和从机上配置好环境和所需要的软件及安装包,具体如下:
一、在主机上我们需要安装好python,redis,mongodb,VMware,Xshell。
1、其中VMware与Xshell是为搭建虚拟机服务的.
2、python需要安装好scrapy,scrapy_redis,pymongo,scrapy_client,尽量安装最新版本的。
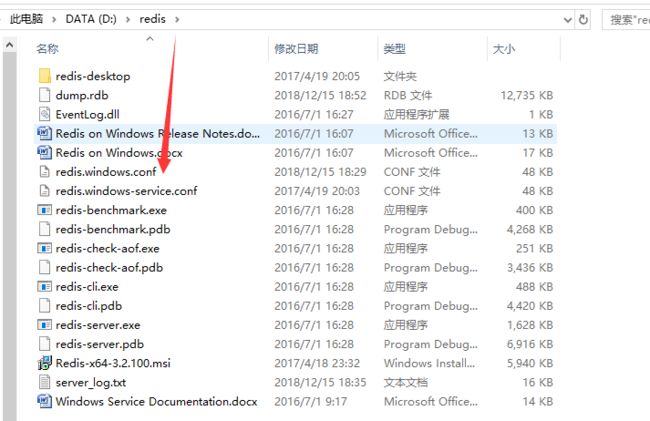
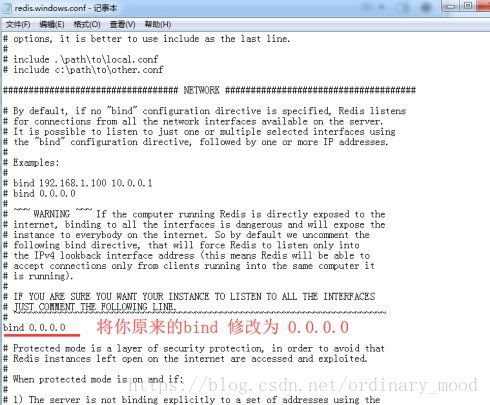
3、为了远程连接redis和mongodb,需要对redis和mongodb分别进行设置,由于在源码中我把MongoPipeline关掉了,用不到mgogodb数据库了,这里就以redis为例:找到redis安装目录下的redis.windows.conf 配置文件(如图1),选择相应的工具打开,redis默认bind localhost,找到bind 并修改为0.0.0.0(如图2)。
当你的电脑作为主机时需要时刻开着redis服务,下面是打开redis服务的配置
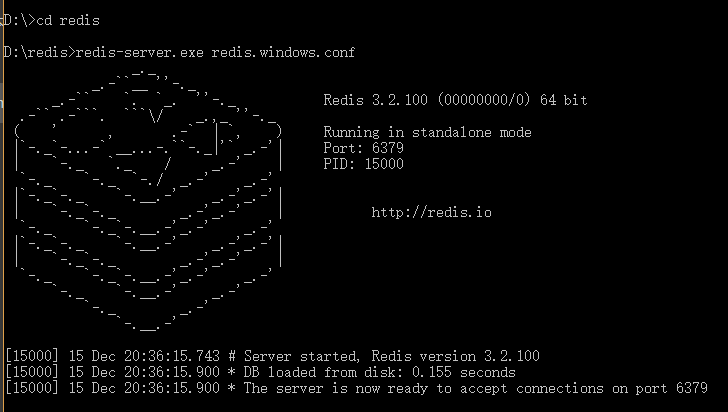
4、打开cmd命令行 进入redis的安装目录,输入redis-server.exe redis.windows.conf 回车。
如果出现bind:no error (在redis目录下输入redis-cli 回车 输入shutdown 回车 输入 exit退出)然后再重新输入输入redis-server.exe redis.windows.conf运行服务,出现图3即证明运行成功。
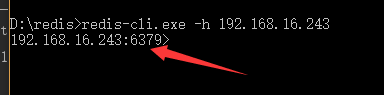
5、主机开启redis服务之后,不要断开,切记!!! 进入redis安装目录,输入:redis-cli.exe -h 主机(或者别人的)ip地址(-p 端口号6379(可以不用写))用来测试是否可以远程连接redis(如果回车之后没有出现如图4效果,检查自己的bind是否修改以及redis服务是否被自己关闭)出现如下表示可以远程连接redis。注意这里需要另开一个cmd命令窗口。
mongdb的配置可以自行百度,至此主机的配置算是初步完成。
二、虚拟机即从机,我们需要安装好python3,scrapy,scrapyd
1、借助VMware软件我在D盘建立了一个linux系统,linux系统默认安装了python2,不满足我的要求,于是手动安装python3,这里需要注意不要动python2,避免引起不必要的麻烦。linux系统下安装python3具体步骤如下:
(1) 安装依赖环境
#yum install -y gcc
#yum install -y zlib*
#yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
(2)下载Python3
# wget https://www.python.org/ftp/python/3.6.3/Python-3.6.3.tgz
注意这一步需要先安装wget工具,命令如下 yum -y install wget
(3)解压下载好的Python-3.x.x.tgz包
# tar -zxvf Python-3.6.3.tgz
(4)进入解压后的目录,配置文件
# cd Python-3.6.3
# ./configure --prefix=/usr/local/python36 这里指定安装目录
(5)编译与安装
#make && make install
(6)创建新版本的软连接。
修改旧版本 #mv /usr/bin/python /usr/bin/python_bak
创建新的软连接 # ln -s /usr/local/python36/bin/python3 /usr/bin/python
创建一下pip3的软链接 # ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
注意这里要注意自己安装python的路径,可以which python查看
至此linux下python3安装完毕,可以输入python看看效果

2、接着安装scrapy与scrapyd
完成以上安装python3的步骤之后,就可以直接通过pip安装scrapy与scrapyd,
命令如下:pip3 install scrapy,pip3 install scrapyd
命令行输入scrapyd,查看效果,scrapyd默认开启127.0.0.1端口,我们需要修改配置,首先找到启动配置文件:
vi /usr/local/python36/lib/python3.6/site-packages/scrapyd/default_scrapyd.conf
这里的路径不是绝对的,具体的是看你把scrapyd安装在哪里了,你用虚拟环境安装的就在虚拟虚拟环境的python下面,不知道的which python可以查看,搞就完了!
修改目的:
修改该启动配置文件的目的是可以远程访问,scrapyd框架分为server端和client端,两个的ip地址必须对的上才能通信;
(1)client端需要将代码上传到server端
(2)可以浏览器访问server端的gui管理界面,世界各地没毛病,前提是具有公网ip;
配置:
默认scrapyd启动bind绑定的ip地址是127.0.0.1端口是:6800,
将ip地址设置为0.0.0.0
打开配置文件不需要翻页就能够找到bind_address
bind_address = 0.0.0.0
修改完成之后再次执行scrapyd,会出现下图所示
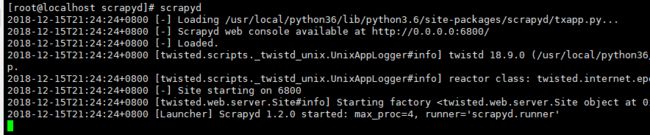
至此准备工作完毕,接下来进入爬虫的配置和部署工作。
三、知乎爬虫的配置与部署
1、首先是scrapy分布式爬虫原理的介绍
(1)关于Scrapy工作流程
scrapy单机架构
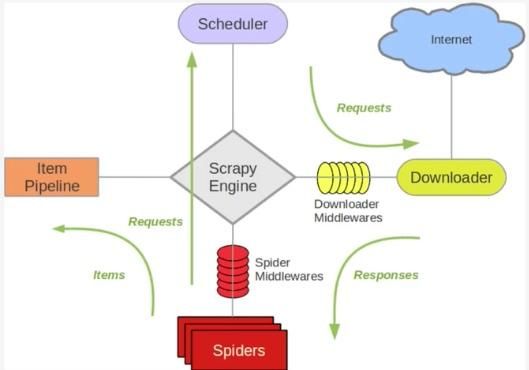
上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列。

分布式架构
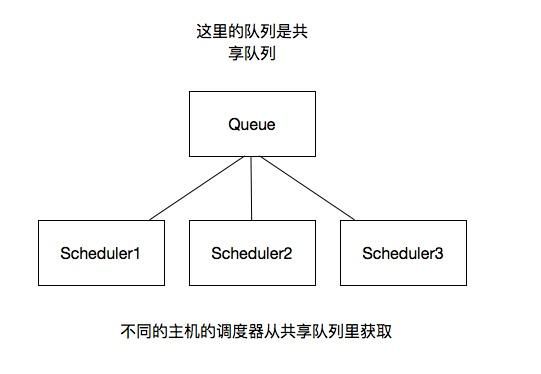
我将上图进行再次更改
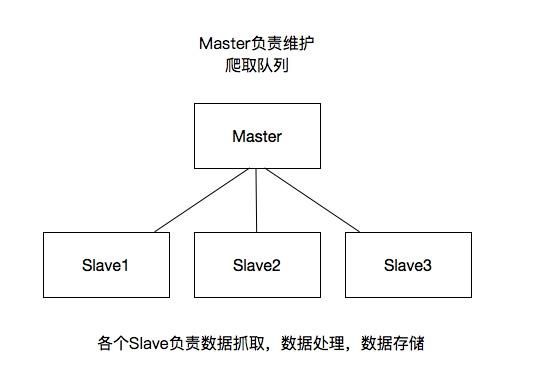
(2)这里重要的就是我的队列通过什么维护?
这里一般我们通过Redis为维护,Redis是非关系型数据库,Key-Value形式存储,结构灵活。并且redis是内存中的数据结构存储系统,处理速度快,提供队列集合等多种存储结构,方便队列维护
(3)如何去重?
这里借助redis的集合,redis提供集合数据结构,在redis集合中存储每个request的指纹,在向request队列中加入Request前先验证这个Request的指纹是否已经加入集合中。如果已经存在则不添加到request队列中,如果不存在,则将request加入到队列并将指纹加入集合
(4)如何防止中断?如果某个slave因为特殊原因宕机,如何解决?
这里是做了启动判断,在每台slave的Scrapy启动的时候都会判断当前redis request队列是否为空,如果不为空,则从队列中获取下一个request执行爬取。如果为空则重新开始爬取,第一台丛集执行爬取向队列中添加request
(5)如何实现上述这种架构?
这里有一个scrapy-redis的库,为我们提供了上述的这些功能,scrapy-redis改写了Scrapy的调度器,队列等组件,利用他可以方便的实现Scrapy分布式架构。关于scrapy-redis的地址:https://github.com/rmax/scrapy-redis。
2、搭建分布式爬虫
参考官网地址:https://scrapy-redis.readthedocs.io/en/stable/
前提是要安装scrapy_redis模块:pip install scrapy_redis
这里的爬虫代码是用的之前写过的爬取知乎用户信息的爬虫
(1)修改该settings中的配置信息:
替换scrapy调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
添加pipeline
如果添加这行配置,每次爬取的数据也都会入到redis数据库中,所以一般这里不做这个配置
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 300}
共享的爬取队列,这里用需要redis的连接信息,这里的user:pass表示用户名和密码,如果没有则为空就可以 #REDIS_URL = 'redis://user:pass@hostname:6379',我由于没设置用户名与账号,就采取如下设置REDIS_HOST='192.168.16.243',REDIS_PORT=6379
SCHEDULER_PERSIST = True设置为为True则不会清空redis里的dupefilter和requests队列,这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置
SCHEDULER_FLUSH_ON_START=True设置重启爬虫时是否清空爬取队列,这样每次重启爬虫都会清空指纹和请求队列,一般设置为False
(2)Scrapy分布式部署
这个scrapyd的github地址:https://github.com/scrapy/scrapyd
当在远程主机上安装了scrapyd并启动之后,就会再远程主机上启动一个web服务,默认是6800端口,这样我们就可以通过http请求的方式,通过接口的方式管理我们scrapy项目,这样就不需要在一个一个电脑连接拷贝过着通过git,关于scrapyd官方文档地址http://scrapyd.readthedocs.io/en/stable/
这里我在linux虚拟机中已经安装scrapy以及scrapyd等包,保证所要运行的爬虫需要的包都完成安装。
在这里有个小问题需要注意,默认scrapyd启动是通过scrapyd就可以直接启动,这里bind绑定的ip地址是127.0.0.1端口是:6800,这里为了其他虚拟机访问讲ip地址设置为0.0.0.0
scrapyd的配置文件:/usr/local/python36/lib/python3.6/sitepackages/scrapyd/default_scrapyd.conf
这样我们就可以通过浏览器访问:
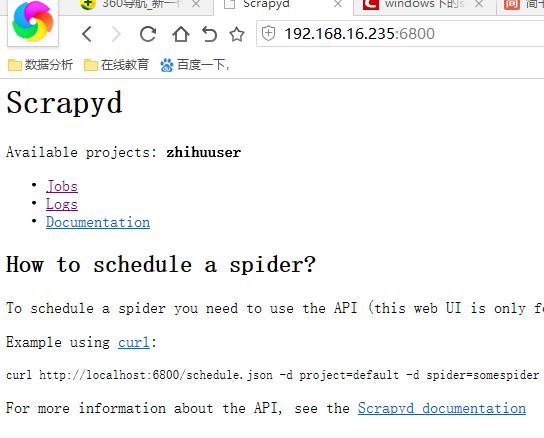
3、关于部署
如何通过scrapyd部署项目,这里官方文档提供一个地址:https://github.com/scrapy/scrapyd-client,即通过scrapyd-client进行操作
这里的scrapyd-client主要实现以下内容:
把我们本地代码打包生成egg文件
根据我们配置的url上传到远程服务器上
我们将我们本地的scrapy项目中scrapy.cfg配置文件进行配置:
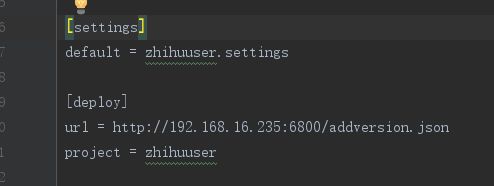
我们其实还可以设置用户名和密码,不过这里没什么必要,只设置了url
这里设置url一定要注意:url = http://192.168.1.9:6800/addversion.json
最后的addversion.json不能少
已经本地安装好scrapy_client,直接执行:scrapyd-deploy,得到如下表示即表明打包成功。

windows用户需要注意,在windows上,pip install scrapyd-client 后。在cmd中运行部署命令,scrapyd-deploy 如果提示:'scrapyd-deploy' 不是内部或外部命令,也不是可运行的程序或批处理文件。可以通过如下步骤解决:
(1)进到python安装目录下Scripts 文件里,创建两个新文件:scrapy.bat、scrapyd-deploy.bat,这里我的文件目录为D:/python3.5.2/Scripts
(2)编辑两个文件:
scrapy.bat文件中输入以下内容 :
@echo off
D:\Python3.5.2\python D:\Python3.5.2\Scripts\scrapy %*
scrapyd-deploy.bat 文件中输入以下内容:
@echo off
D:\Python33.5.2\python D:\Python3.5.2\Scripts\scrapyd-deploy %*
(3)保存退出,并确保你的 D:/python3.5.2和D:/python3.5.2/Scripts 都在环境变量。这样就可以正常运行scrapy-deploy命令了。
4、关于常用操作API
完成上述步骤,我们已经虚拟机部署了一个爬虫项目,现在要怎么操作呢?scrapy_client为我们提供了一个web接口用于调度爬虫项目,详情可以查看scrapyd帮助文档https://scrapyd.readthedocs.io/en/latest/api.html#cancel-json,这里简单举个例子,如我们可以直接在pycharm的terminal端口直接执行curl http://localhost:6800/listprojects.jsonlistprojects.json列出上传的项目列表,本人在windows下直接运行curl,出现如下提示:

于是选择在cmd命令端口中执行curl命令,如图所示

远程启动虚拟机上部署的爬虫,可以执行以下命令
$ curl http://192.168.16.235:6800/schedule.json -d project=zhihuuser -d spider=zhihu,其中project是项目名称,spider是爬虫名称,执行完毕返回下图则说明调度成功

我们可以通过查看scrapyd提供的web接口http://192.168.16.235:6800查看项目执行情况
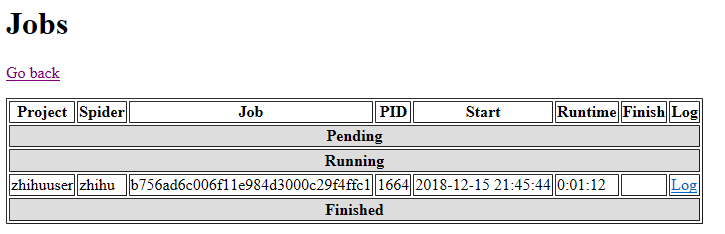
点击上图的log可以查看爬虫爬取情况,再后面我们可以通过下面命令关闭爬虫任务。
curl http://192.168.16.235:6800/cancel.json -d project=zhihuuser -d job=b756ad6c006f11e984d3000c29f4ffc1,这里的job就是图16里调度成功之后返回的jobid
执行成功后同样可以借助http://192.168.16.235:6800查看到任务已经finish。
