机器学习数学原理(6)——最优间隔分类器
这一篇博文主要起一个承上启下的作用,即需要上一篇博文所说的泛化拉格朗日定理方面的知识(建议读者先阅读上一篇博文《机器学习数学原理(5)——广泛拉格朗日乘子法》),同时为下一篇关于SVM支持向量机的博文作铺垫。这一篇博文介绍最优间隔分类器。
需要注意的是,本篇所介绍的最优间隔分类器都是建立在线性可分的二分类样本基础上的,对于非线性可分的样本笔者会在下一篇博文SVM支持向量机的核函数法(Kernel)的章节中仔细介绍,这里便先不再赘述。
另外老规矩,由于笔者水平有限,如果文章中出现不妥或者错误的地方,欢迎大家批评指出。
1 间隔
最优间隔分类器(the Optimal Margin Classifier)的核心便是间隔(Margins),整个算法便是围绕这个概念展开。所谓间隔指的是特征点到分割超平面(Separating Hyperplane)的距离。
为了方便以后的叙述,将间隔分为两类:
函数间隔
几何间隔
接下来笔者便先来介绍这两种间隔。
在我们介绍间隔前笔者认为有必要先确定一下符号:
xi:样本空间中第i个样本,有n维。
yi:第i个样本的标签,取值为1和-1两种。
ω,b:ω为特征空间的超平面中x前面的系数,为向量;b为偏置项,也可以看做截距,为常数项。
则由符号我们可以定义出分割超平面在特征空间的表达式为:
注意:这里的ω和b并不唯一,可以等比例放大缩小,表示的任然是同一个超平面,这一点很重要,后面算法的导出需要用到这一点。
1.1 函数间隔
函数间隔(Functional Margins),Xi样本到分割超平面的函数间隔的表达式为
γ的正负表明在超平面分割出的不同空间,若γ=0.则表明在超平面上。
注意:由于超平面的ω和b可以任意等比例变化,导致γ的值不唯一。这既会增加麻烦,但同时也增加了灵活性,使得问题后面能够变为凸优化问题。
从上我们可知,如果要使得函数间隔唯一,则我们需要对超平面的参数进行一个规范化,即需要一个f(ω,b)=0来约束超平面参数使之唯一,从而使得函数间隔唯一。
其实下面讲的几何间隔就是在规范化方程|ω|-1=0下的函数间隔。
1.2 几何间隔
几何间隔(Geometric Margins),Xi样本到分割超平面的几何间隔的表达式为

这里的ω和b没有任何规范化约束,因为约束条件已经通过除以ω的模展现了出来,使得几何间隔不再随着ω和b的等比例放大缩小而改变,变得唯一。这个也是在实际立体图像中点到平面距离的表达式。
当然也可以写成上面函数间隔的形式,即在|ω|-1=0下的函数间隔。
2 最优间隔分类器主要思想
为了方便叙述,我们先假设一个样本空间在特征空间的分布形式如图,样本为二分类,同时样本是线性可分的,换句话说,可以通过一个超平面(图中为一条直线)将两类样本完全分开。
这里先给读者道个歉,因为画图有些麻烦(实际是因为笔者太懒…),下面的散点图均摘自360图片搜索“最优间隔分类器”的搜索结果。
我们先看如何用一个超平面(二维的是直线)分开两类样本
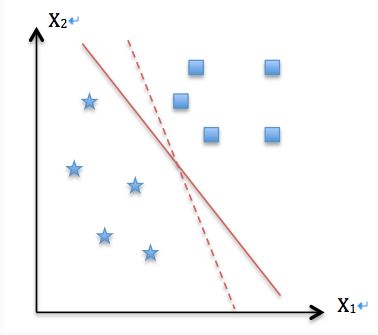
可以看出,通过一定角度的旋转,这样的超平面有无数个,均可以将两类样本分开。既然有这么多个,那么我们如何选择呢?这个选择的策略便是最优间隔分类器的主要思想。
我们先通过自己的直觉来思考这个问题,怎样的超平面才能更好的,更加准确的分割这个样本空间呢?通过直觉不难发现(至少笔者的直觉是这样的^_^),如果我们能够使得样本边界到达分割超平面的距离最大即为最好的分割超平面,换句话说我们需要使得距离分割超平面最近的样本点到分割超平面的距离取极大值(这个有点绕,需要仔细看一下)。
这样的想法是自然的,简洁的,容易理解的,因此,很多人都认为SVM支持向量机是最好的分类算法(当然这说法并不太妥,但确实很多人是这样认为的)。
3 最优间隔分类器参数确定
根据我们的主要思想,现在我们将这个主要思想数学化。假设有m个样本点,每个样本点均有n维的特征。首先再来看一下这个选取超平面的策略:
改变ω,b,使得距离分割超平面最近的样本点到分割超平面的距离取极大值。
这里我们先确定标签的取值以及间隔的绝对值表示:
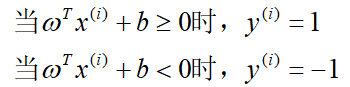
这样一来,间隔的绝对值则可以表示为

注意:这里我们均采用函数间隔表示,因为几何间隔可以写成|ω|-1=0约束下的函数间隔。
首先第一步,我们先找到距离分割超平面最近的样本点到分割超平面的距离,用数学表达式表示即为
那么优化问题可以转化为数学表达式:
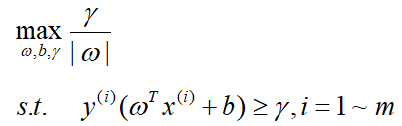
虽然这个优化问题已经用数学表达式表示出来了,但是我们可以发现这样的优化问题并不是凸优化问题,这总是令人不愉快的。那么接下来我们想办法把它转化为一个凸优化问题。
优化问题已经如上确定了,我们如何才能改变,这里我们前面提到的函数间隔的规范式便开始出来起作用了,我们知道在上述的优化问题中ω与b的值可以随意改变,这里我们不妨加上一个规范式从而使得问题转化为凸优化问题。
这里我们选取的规范式为:
这里γ隐含ω和b的。
选取这样的规范式过后,我们的优化问题变成了:
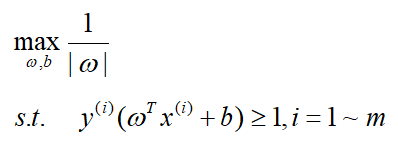
进一步转化为等价的凸优化问题:
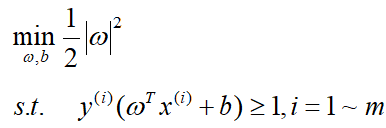
至此我们的问题便转化为了一个相对好解决的凸优化问题了。
接下来便是解决这个凸优化问题了,这里需要用到上一篇博文《机器学习数学原理(5)——广泛拉格朗日乘子法》的内容,这里笔者不再做推导,直接给出结论:

将上面的条件带入拉格朗日函数中我们可以得到对偶优化问题:
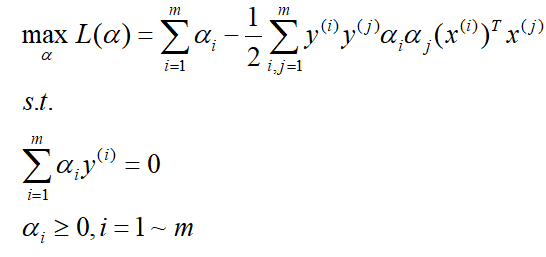
当然同时也要满足KKT条件。
这样,我们就把转化变量变为了α,然后通过上面ω与α的关系便可以求出ω,ω求出来后,b也可以很容易的得到为:

然后接下来就需要解决上面关于α的优化问题了,解决方案将放在下一篇博文中。
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/z_x_1996/article/details/72763904