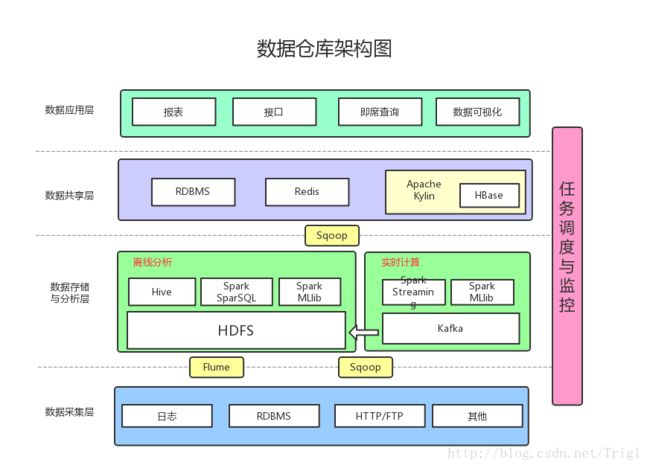
数据采集:采用Flume收集日志,采用Sqoop将RDBMS以及NoSQL中的数据同步到HDFS上
消息系统:可以加入Kafka防止数据丢失
实时计算:实时计算使用Spark Streaming消费Kafka中收集的日志数据,实时计算结果大多保存在Redis中
机器学习:使用了Spark MLlib提供的机器学习算法
多维分析OLAP:使用Kylin作为OLAP引擎
数据可视化:提供可视化前端页面,方便运营等非开发人员直接查询
数据仓库多维数据模型的设计
- 基本概念
主题(Subject)
主题就是指我们所要分析的具体方面。例如:某年某月某地区某机型某款App的安装情况。主题有两个元素:一是各个分析角度(维度),如时间位置;二是要分析的具体量度,该量度一般通过数值体现,如App安装量。
维(Dimension)
维是用于从不同角度描述事物特征的,一般维都会有多层(Level:级别),每个Level都会包含一些共有的或特有的属性(Attribute),可以用下图来展示下维的结构和组成:
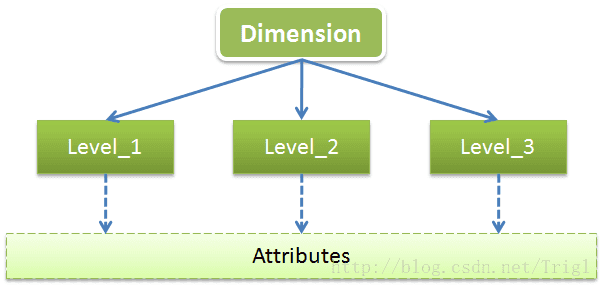
以时间维为例,时间维一般会包含年、季、月、日这几个Level,每个Level一般都会有ID、NAME、DESCRIPTION这几个公共属性,这几个公共属性不仅适用于时间维,也同样表现在其它各种不同类型的维。
分层(Hierarchy)
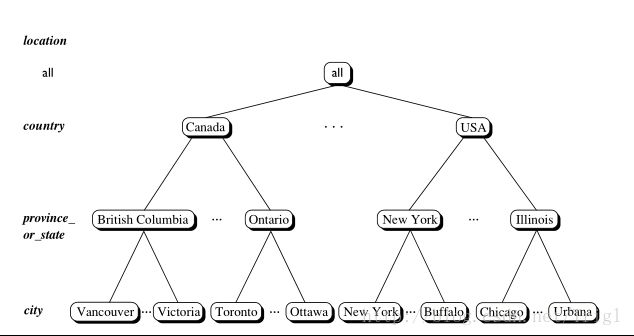
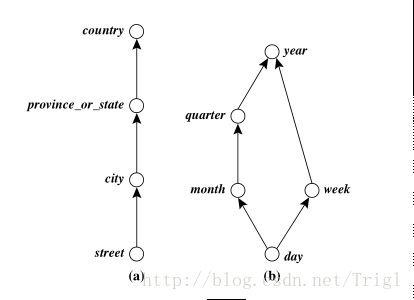
OLAP需要基于有层级的自上而下的钻取,或者自下而上地聚合。所以我们一般会在维的基础上再次进行分层,维、分层、层级的关系如下图:

每一级之间可能是附属关系(如市属于省、省属于国家),也可能是顺序关系(如天周年),如下图所示:
量度
量度就是我们要分析的具体的技术指标,诸如年销售额之类。它们一般为数值型数据。我们或者将该数据汇总,或者将该数据取次数、独立次数或取最大最小值等,这样的数据称为量度。
粒度
数据的细分层度,例如按天分按小时分。
事实表和维表
事实表是用来记录分析的内容的全量信息的,包含了每个事件的具体要素,以及具体发生的事情。事实表中存储数字型ID以及度量信息。
维表则是对事实表中事件的要素的描述信息,就是你观察该事务的角度,是从哪个角度去观察这个内容的。
事实表和维表通过ID相关联,如图所示:

星形/雪花形/事实星座
这三者就是数据仓库多维数据模型建模的模式
上图所示就是一个标准的星形模型。
雪花形就是在维度下面又细分出维度,这样切分是为了使表结构更加规范化。雪花模式可以减少冗余,但是减少的那点空间和事实表的容量相比实在是微不足道,而且多个表联结操作会降低性能,所以一般不用雪花模式设计数据仓库。
事实星座模式就是星形模式的集合,包含星形模式,也就包含多个事实表。
企业级数据仓库/数据集市
企业级数据仓库:突出大而全,不论是细致数据和聚合数据它全都有,设计时使用事实星座模式
数据集市:可以看做是企业级数据仓库的一个子集,它是针对某一方面的数据设计的数据仓库,例如为公司的支付业务设计一个单独的数据集市。由于数据集市没有进行企业级的设计和规划,所以长期来看,它本身的集成将会极其复杂。其数据来源有两种,一种是直接从原生数据源得到,另一种是从企业数据仓库得到。设计时使用星形模型
数据仓库设计步骤
1、确定主题
主题与业务密切相关,所以设计数仓之前应当充分了解业务有哪些方面的需求,据此确定主题
2、确定量度
在确定了主题以后,我们将考虑要分析的技术指标,诸如年销售额之类。量度是要统计的指标,必须事先选
择恰当,基于不同的量度将直接产生不同的决策结果。
3、确定数据粒度
考虑到量度的聚合程度不同,我们将采用“最小粒度原则”,即将量度的粒度设置到最小。例如如果知道某些数据细分到天就好了,那么设置其粒度到天;但是如果不确定的话,就将粒度设置为最小,即毫秒级别的。
4、确定维度
设计各个维度的主键、层次、层级,尽量减少冗余。
5、创建事实表
事实表中将存在维度代理键和各量度,而不应该存在描述性信息,即符合“瘦高原则”,即要求事实表数据条数尽量多(粒度最小),而描述性信息尽量少。
多维数据模型是最流行的数据仓库的数据模型,多维数据模型最典型的数据模式包括星型模式、雪花模式和事实星座模式,本文以实例方式展示三者的模式和区别。
二、星型模式(star schema)
星型模式的核心是一个大的中心表(事实表),一组小的附属表(维表)。星型模式示例如下所示:
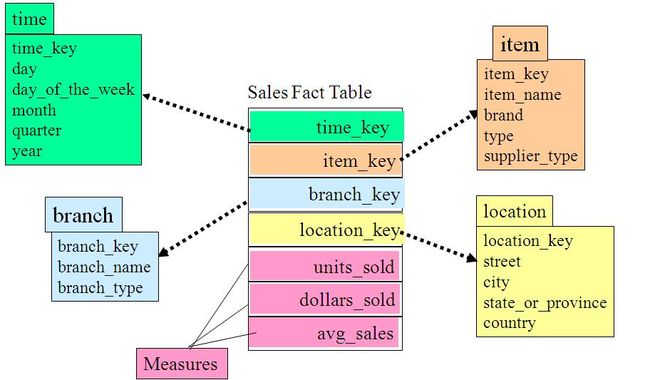
三、雪花模式(snowflake schema)
雪花模式是星型模式的扩展,其中某些维表被规范化,进一步分解到附加表(维表)中。雪花模式示例如下图所示:
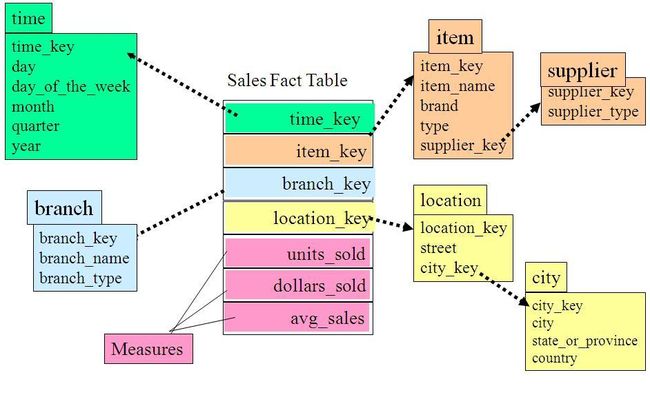
从图中我们可以看到地址表被进一步细分出了城市(city)维。supplier_type表被进一步细分出来supplier维。
四、事实星座模式(Fact Constellation)或星系模式(galaxy schema)
数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,这种模式可以看做星型模式的汇集,因而称作星系模式或者事实星座模式。本模式示例如下图所示:
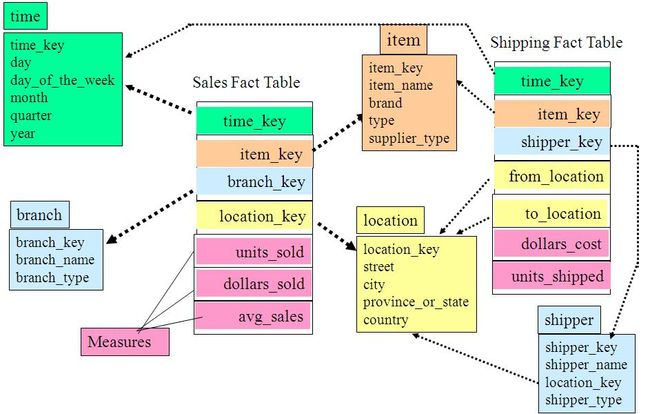
如上图所示,事实星座模式包含两个事实表:sales和shipping,二者共享维表。
五、总结
事实星座模式是数据仓库最长使用的数据模式,尤其是企业级数据仓库(EDW)。这也是数据仓库区别于数据集市的一个典型的特征,从根本上而言,数据仓库数据模型的模式更多是为了避免冗余和数据复用,套用现成的模式,是设计数据仓库最合理的选择。当然大数据技术体系下,数据仓库数据模型的设计,还是一个盲点,探索中。