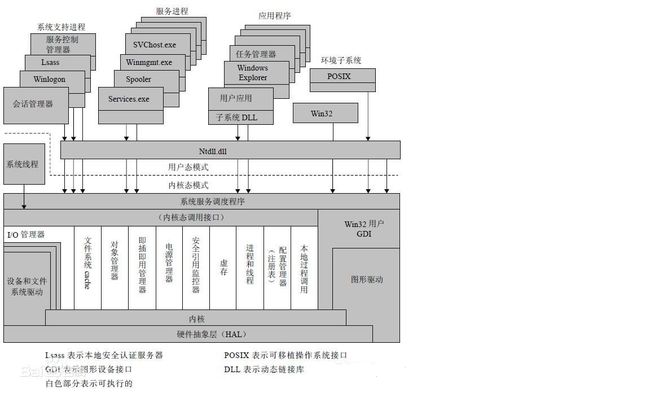
计算机启动的过程
系统启动的经过可以汇整成底下的流程的:
1、加载 BIOS 的硬件资讯与进行自我测试,并依据配置取得第一个可启动的装置;
2、读取并运行第一个启动装置内 MBR 的 boot Loader (亦即是 grub, spfdisk 等程序);
3、依据 boot loader 的配置加载 Kernel ,Kernel 会开始侦测硬件与加载驱动程序;
4、在硬件驱动成功后,Kernel 会主动呼叫 init 程序,而 init 会取得 run-level 资讯;
5、init 运行 /etc/rc.d/rc.sysinit 文件来准备软件运行的作业环境 (如网络、时区等);
6、init 运行 run-level 的各个服务之启动 (script 方式);
7、init 运行 /etc/rc.d/rc.local 文件;
8、init 运行终端机模拟程序 mingetty 来启动 login 程序,最后就等待使用者登陆啦;
进程0和进程1

内核是一个大的程序,可以控制硬件,也可以创建、运行、终止、控制所有的进程。当内核被加载到内存后,首先就会有完成内核初始化的函数start_kernel()从无到有的创建一个内核线程swap,并设置其PID为0,即进程0;它也叫闲逛进程;进程0![Uploading 捕获_653996.PNG . . .]
执行的是cpu_idle()函数,该函数仅有一条hlt汇编指令,就是在系统闲置时用来降低电力的使用和减少热的产生。同时进程0的PCB叫做init_task,在很多链表中起了表头的作用。
sysproc进程。管理换入与换出的进程,对系统中运行的进程进行合理地调度。 将进程从硬盘交换区调入内存的过程称为换入;将进程从内存调到硬盘交换 区的过程称为换出。该进程是unix核心创建的第一个进程,有多个LWPs。
进程0kernel启动时创建的第一个进程,时进程1的父进程,负责其他进程的调度
进程调度init函数,负责系统初始化
整个linux系统的所有进程也是一个树形结构。树根是系统自动构造的,即在内核态下执行的0号进程,它是所有进程的祖先。由0号进程创建1号进程(内核态),1号负责执行内核的部分初始化工作及进行系统配置,并创建若干个用于高速缓存和虚拟主存管理的内核线程。随后,1号进程调用execve()运行可执行程序init,并演变成用户态1号进程,即init进程。它按照配置文件/etc/initab的要求,完成系统启动工作,创建编号为1号、2号...的若干终端注册进程getty。
在多处理器系统中,每个CPU都有一个进程0,主要打开机器电源,计算机的BIOS就启动一个CPU,同时禁用其他CPU。运行的CPU 上的swapper进程初初始化内核数据结构,然后激活其他的并且使用copy_process()函数创建另外的swapper进程,把0 传递给新创建的swapper进程作为他们进程的PID.
fork()
进程在内存里有三部分的数据——代码段、堆栈段和数据段。这三个部分是构成一个完整的执行序列的必要的部分。
代码段——存放了程序代码的内存空间。这个最容易理解,不就是程序在机器内的表示而已嘛。注意假如机器中有数个进程运行相同的一个程序,那么它们就可以使用相同的代码段。也就是说如果fork()出来了一个子进程,子进程和父进程实际上使用的是相同的代码段。
堆栈段——存放的就是子程序的返回地址、子程序的参数以及程序的局部变量。
数据段——全局变量和静态变量
父子进程使用相同的代码段,但是会拥有各自的数据段和堆栈段。
void main()
{
pid_t pid;
pid=fork();
if(pid==0)
{
//子进程任务
}
else if(pid>0)
{
//父进程任务
}
}
执行过程是这样的:
1.操作系统分配内存给父进程,包括上面提到的三个段,就是会在堆栈段里有一块空间是用来存放pid变量的。
2.接着内核调度父进程执行fork()函数(这个函数里实际上使用了系统调用),这时候子进程才会出现,内核会将父进程的数据段和堆栈段作一个拷贝给子进程,注意这时子进程的堆栈段里一定会有一个空间用来存放pid变量!然后系统调用成功,内核给父进程堆栈段里的pid变量赋上子进程的pid号,而给子进程堆栈段里的pid变量赋上0。
3.接下来还是交给内核调度决定执行的是子进程还是父进程(一般内核会先给子进程执行)。如果是父进程,它的下一句代码就是判断pid变量的大小,它会去它的堆栈段里存放pid变量的地方取出pid来进行比较,它会发现pid>0,所以接下来它就去执行——父进程任务;如果是子进程,由于同样的代码段,它也会去比较它自己的pid变量,发现pid=0,所以接下来它会去执行——子进程任务。
没有一个函数可以使父进程获取起所有子进程
一个进程只会有一个父进程


父子进程利用共享内存通信
fork与vfork的区别
1.vfork保证子进程先运行,在它调用exec或exit之后父进程才可能被调度运行。如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。
2.fork要拷贝父进程的进程环境;而vfork则不需要完全拷贝父进程的进程环境,在子进程没有调用exec和exit之前,子进程与父进程共享进程环境,相当于线程的概念,此时父进程阻塞等待。
为什么会有vfork呢?
因为以前的fork当它创建一个子进程时,将会创建一个新的地址空间,并且拷贝父进程的资源,然后将会有两种行为:
1.执行从父进程那里拷贝过来的代码段
2.调用一个exec执行一个新的代码段
当进程调用exec函数时,一个新程序替换了当前进程的正文,数据,堆和栈段。这样,前面的拷贝工作就是白费力气了,这种情况下,聪明的人就想出了vfork。vfork并不复制父进程的进程环境,子进程在父进程的地址空间中运行,所以子进程不能进行写操作,并且在儿子“霸占”着老子的房子时候,要委屈老子一下了,让他在外面歇着(阻塞),一旦儿子执行了exec或者exit后,相当于儿子买了自己的房子了,这时候就相当于分家了。
exit和return
1.exit用于结束正在运行的整个程序,它将参数返回给OS,把控制权交给操作系统;而return 是退出当前函数,返回函数值,把控制权交给调用函数。
- exit是系统调用级别,它表示一个进程的结束;而return 是语言级别的,它表示调用堆栈的返回。
- 在main函数结束时,会隐式地调用exit函数,所以一般程序执行到main()结尾时,则结束主进程。exit将删除进程使用的内存空间,同时把错误信息返回给父进程。
- void exit(int status); 一般status为0,表示正常退出,非0表示非正常退出。
exit函数和return函数的主要区别是:
1)exit用于在程序运行的过程中随时结束程序,其参数是返回给OS的。也可以这么讲:exit函数是退出应用程序,并将应用程序的一个状态返回给OS,这个状态标识了应用程序的一些运行信息。
main函数结束时也会隐式地调用exit函数,exit函数运行时首先会执行由atexit()函数登记的函数,然后会做一些自身的清理工作,同时刷新所有输出流、关闭所有打开的流并且关闭通过标准I/O函数tmpfile()创建的临时文件。
exit是系统调用级别的,它表示了一个进程的结束,它将删除进程使用的内存空间,同时把错误信息返回父进程。通常情况:exit(0)表示程序正常, exit(1)和exit(-1)表示程序异常退出,exit(2)表示系统找不到指定的文件。在整个程序中,只要调用exit就结束。
2)return是语言级别的,它表示了调用堆栈的返回;return是返回函数值并退出函数,通常0为正常退出,非0为非正常退出,请注意,如果是在主函数main, 自然也就结束当前进程了(也就是说,在main()里面,你可以用return n,也能够直接用exit(n)来做),如果不是在main函数中,那就是退回上一层调用。在多个进程时,如果有时要检测上个进程是否正常退出,就要用到上个进程的返回值。
exit()与_exit()的区别

_exit 函数的作用是:直接使进程停止运行,清除其使用的内存空间,并清除其在内核的各种数据结构;exit 函数则在这些基础上做了一些小动作,在执行退出之前还加了若干道工序。exit() 函数与 _exit() 函数的最大区别在于exit()函数在调用exit 系统调用前要检查文件的打开情况,把文件缓冲区中的内容写回文件。也就是图中的“清理I/O缓冲”。


实际用户 有效用户 保存的设置用户
文件的访问权限包括读写和执行。判断某个进程对文件有何权限时,内核会将非超级用户进程的有效ID与文件的所有者ID进行比较,当然,也可能需要比较有效组ID,这关系到具体的权限测试方法,先不在这里说明。而超级用户创建的进程是允许访问整个文件系统的。它的有效ID等于0。不过,这里还有一点需要说明的是,仅仅有合适的有效ID,还不一定就能获得所有或者部分权限。你需要得到被访问文件的允许,这就是文件访问权限位(用户读、用户写、组读等)的责任了。
这里又牵涉到一个“ID”,即文件的所有者ID。文件的所有者ID是什么呢?创建文件是由某用户的进程实现的吧?所以在创建新文件的时候,就将该进程的有效ID作为该文件的所有者ID了。APUE里面有时又将文件的所有者ID称为“文件的用户ID”。
一般情况下,进程的有效用户ID就被设成执行该进程的实际用户ID。比如,用户usr01执行了进程process,process的有效用户ID就设成了用户usr01的ID(实际用户ID)。但是有的时候,一个进程可能要去执行其他用户创建的文件。这时,该进程的有效ID和该文件的所有者ID是不同的(记住文件的所有者Id就是最初创建它的进程有效ID)。但是如果文件设置了“设置用户ID位”或者“设置组ID位”,那么该进程在执行该文件的时候,就会将进程的有效ID临时更改为文件的所有者ID。
设置用户ID:设置用户ID是由exec函数复制有效用户ID得来的。所以说设置用户ID是进程有效ID的副本。为什么要保留进程有效ID的副本呢?刚才讲到文件有设置用户ID位时,内核会将执行进程的有效ID临时更改为文件的所有者ID。