视频技术
视频技术是指将动态影像以电信号的方式加以捕捉、记录、处理、存储、复现相关的一系列技术。
模拟技术和数字技术
在模拟技术中,波是以原始形式记录或使用的。例如,模拟磁带录音机会直接从麦克风获取信号并记录在磁带上。麦克风中的波是模拟波,因此磁带上的波也是模拟波。可以对磁带上的波进行读取、放大并送到扬声器,从而发出声音。
在数字技术中,模拟波是按一定的间隔进行采样的,然后转换为存储在数字设备上的数字。在光盘上,其采样频率为每秒44,000个样本。因此,在光盘上,每秒钟的音乐对应44,000个数字。若要听到音乐,需要将数字转换为与原始波相似的电压波。
数字视频技术技术
真实的动态影像在时间和空间上都是连续的。要能以数字信号的方式进行处理就必须对动态影像进行时间采样和空间采样,如下图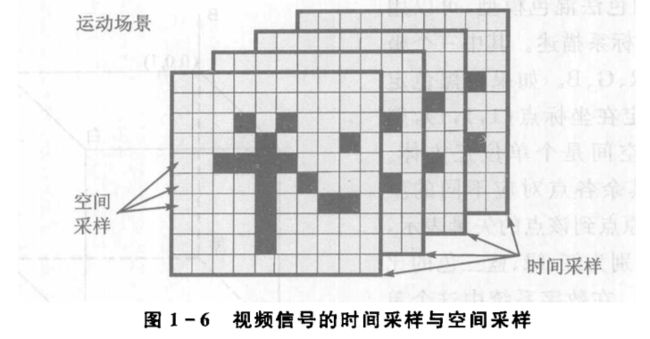
在时间上,对于模拟信号的采样时间间隔会影响人眼对运动的感受。帧率越高,运动场景表现得越平滑。帧率低于每秒10帧,会感觉明显的不连贯。帧率在每秒10-20帧时,低速运动效果不错,但高速运动会有不连连贯。帧率在每秒25帧-30帧时,运动感觉很流畅,当帧率在每秒50-60帧时,运动感觉非常流畅。
在空间上,对于黑白视频图像,每一个样本点只需要用单值表示其亮度信息。对于彩色视频图像,每一个样本点则需要多个数值进行表示。常用一维、二维、三维甚至四维模型来表示某一色彩,它所能定义的色彩范围被成为色彩空间。不同的数字图像系统会使用不同的颜色模型。例如在计算机系统常用RGB色彩模型,在彩色电视系统中使用YUV色彩模型,彩色印刷机则用CMYK色彩模型。
RGB色彩模型是根据人类视觉系统特征,任何一种人眼能感知的颜色都可以用红、绿、蓝三种基色光按照不同的比例混合得到。
YUV色彩模型利用了人类视觉系统对亮度的敏感度比色度的敏感度高的特点,将亮度信息从色度信息中分离了出来,并且对同一帧图像的亮度和色度采用了不同的采样率。这样可以保证视觉质量的前提下显著地减低采样的数据率,实现视频压缩。而且也解决了黑白电视和彩色电视的兼容问题。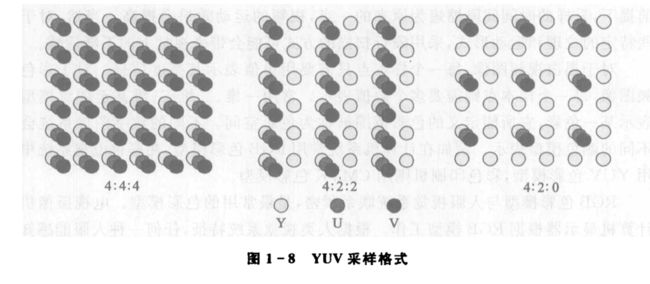
上图给出了三种常见的YUV采用格式,YUV格式一共有3个分量,在4*2个采样点中,第一个分量代表亮度信息每行采样数量,第二分量代表了色度信息在第一行的采样数量,第三个分量代表了色度信息在第二行的采用数量。
RGB色彩模型和YUV色彩模型之间存在简单的转换关系。转换关系如下:
Y = 0.299R + 0.587G + 0.114B
U = - 0.14R - 0.289G + 0.436B
V = 0.615R - 0.515G - 0.100B
当转换的目标是YUV4:4:4格式时,只需要对应的变换公式进行格式转换,不会带来信息损失。如果是4:2:2或4:2:0格式时,则先需要按照样本的位置进行抽样,这样会损失一部分色差信息,但对视觉效果影响不大。转换关系如下:
R = 1.000Y + 0.000U + 1.140V
G = 1.000Y - 0.395U - 0.581V
B = 1.000Y + 2.032U + 0.001V
同理,当从YUV4:4:4格式转到RGB时只需要对应公式进行格式转换。但如果是从4:2:2或4:2:0格式转换时,需要先对U、V两个分量使用插值方法补齐缺少的像素值。
视频编解码需求
必要性
720P的视频,1秒未压缩的数据量为3 * 1080 * 720 * 25 = 58,320,000约为58M
- 没压缩的视频数据所需要的存储空间是普通设备没法承受的。
- 目前的数据传输系统中数据传输的带宽,远远不能满足传输未经压缩过的数字视频的需要。
可行性
视频数据主要包括两部分内容:信息和冗余数据。信息是有用的数据,而冗余数据是无用的内容,可以压缩掉。冗余的具体体现是相同或相似信息的重复。视频数据的冗余主要有:
- 空间冗余 同一物体表面上采样点的颜色之间往往存在着空间连贯性
- 时间冗余 一组连续的画面之间往往存在着时间和空间的相关性
- 结构冗余 某些场景中,存在明显的图像分布模式
- 知识冗余 有些图像的理解与某些知识有相当大的相关性
- 视觉冗余 人类的视觉系统对图像场的敏感性是非均匀和非线性的。
视频编解码基础
视频编解码主要使用四种编解码方法:预测编码、变换编码、量化编码、熵编码
预测编码
所谓预测就是利用已知信息猜测位置信息,预测编码的思路简单来说就是指编码实际值与预测值之间的差别。考虑到图像的特点,预测通常是以块为单位进行的,这需要先按照约定的规则将图像分割成规则大小的块,并按照约定的顺序对各个块进行预测编码。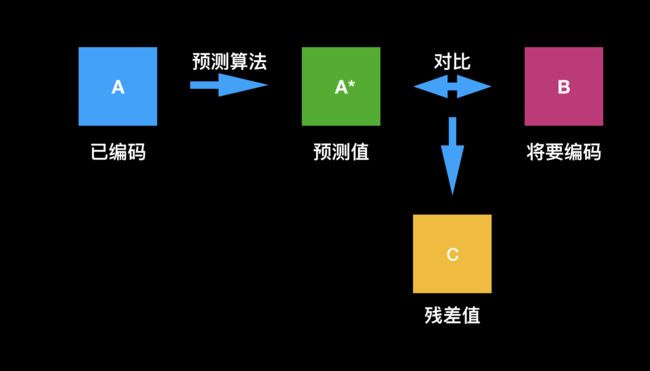
预测编码一般分为帧间预测编码和帧内预测编码。帧间预测编码利用了视频时间冗余。帧内预测编码利用了视频的空间冗余。视频的时间冗余一般都大于空间冗余,所以帧间预测的压缩率会大于帧内预测。
帧间预测编码
帧间预测旨在消除时域的冗余信息,就是利用之前编码过的图像来预测现在要编码的图像。
这里说的编码过的图像,并不是指原始图像,而是指原始图像编码后再经过解码而得到的图像
帧内预测有两个重要的概念:运动估计与运动补偿。
运动估计就是寻找当前编码的块在已编码图像(称为参考帧)中的最佳对应块,并计算出对应块的偏移。
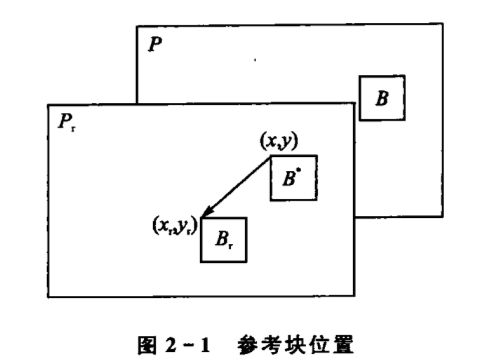
运动补偿技术 运动补偿是根据运动矢量和帧间预测方法,得到当前帧的的估计值的过程。它是对当前图像的描述,旨在说明当前图像的每一块像素如何由其他参考图像的像素块得到。简单的来就是通过运动矢量找到参考块,对参考块使用预测方法得到估计块的一个过程。
由此得出,帧间预测编码最后需要进行网络传输的有3个参数:运动矢量、预测方法、误差值。
由于视频的连贯性,对于运动矢量和预测方法也可以通过预测编码进行编码,进一步提高视频的压缩率。
运动估计
- 根据运动估计方向的选择,可以划分为前向、后向及双向预测
- 运动搜素的块大小。平滑区域的编码倾向于选取较大的分块;纹理复杂的倾向于选取较小的分块类型;运动剧烈倾向于选取较小的分块;运动较少的倾向于选取较大的分块类型。
- 搜索范围
- 运动估计准则,定义一个匹配准则,匹配误差较小的块。
- 运动搜索算法 - 全搜索算法、快速搜索算法
- 亚像素预测与重叠块运动补偿,亚像素预测就是说不已整像素为单位,而是以1/2、1/4像素为基本单位。
重叠块运动补偿,对于当前编码块,可以拥有多个备选运动矢量,包括其自身的运动矢量和周围已编码块的运动矢量,这样每个像素不仅属于一个快,而是属于周边已编码块的一个大块。(不太理解)
帧内预测
基于空域的帧内预测技术、利用当前块的相邻像素直接对每个像素做预测,然后对预测残差进行变换、量化。
变换编码
变换编码的基本原理
变换编码是指对信号的样本值进行某种形式的函数变换,从一种空间变换到另一种空间,然后再根据信号在另一个空间域的特征来对信号进行编码压缩。例如:时域与频域的变换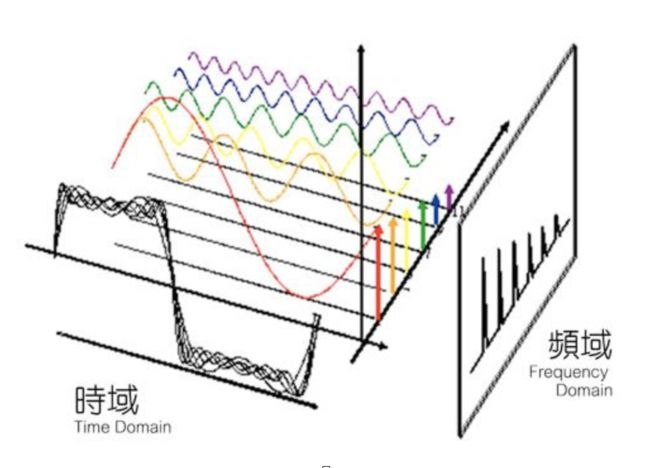
对于空域中,视频信号的幅度随着时间周期性变换,每个幅度出现的概率较为均匀 ,很难进行压缩。对于频域中的图片,低频频谱的幅度分布均匀,高频频谱的幅度通常得到的是低幅度和稀少的高幅度,分布不均匀。由此,可对视频的低频分量和高频分量分别处理,获得高效压缩。
在图像中,图像的频率指的是像素灰度在空间中变换的情况,是灰度在平面空间上的梯度。一般来说,图像的低频部分描述了图像的整体形状,图像的高频部分描述了图像的细节。
变换编码的算法
- K-L变换
- 离散傅里叶变换
- 离散余弦变换
- 离散沃尔变换
- Hadamard变换
- 小波变换
- ...
离散余弦变换
离散余弦变换主要用于数据或图像的压缩,能够将空域信号转换到频域上,并将图像的能量集中到图像的左上角。下图表示了原始图像和经过离散余弦变换(DCT)变换后的图像。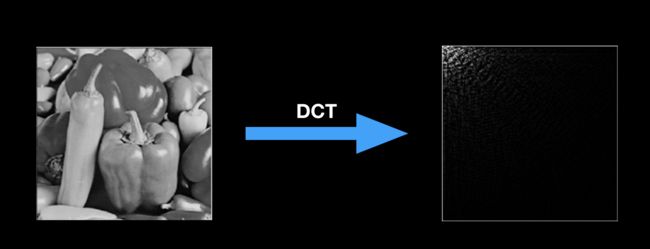
右边的图中,亮的部分表示图像的能量,越亮表示该点的集中的图像能量越高。经过两张图像的对比,很明显的看出,经过DCT变换后,大部分的图像数据都集中到了左上角区域,而右下角区域几乎为黑色的,在传输过程中只要将左上角的数据传输到接收端,接收端就可以通过反离散余弦变换还原出图像的大部分信息。
一般来说。DCT是无损的,但是它无法避免浮点乘法,因此经常会把整数变换成浮点数,导致离散余弦变换无法用在无损压缩中。所以提出了整数余弦变换。
游程编码
游程长度编码,指的是在由信号取值构成的数据流中计算各个样本连续重复出现次数的编码方式。
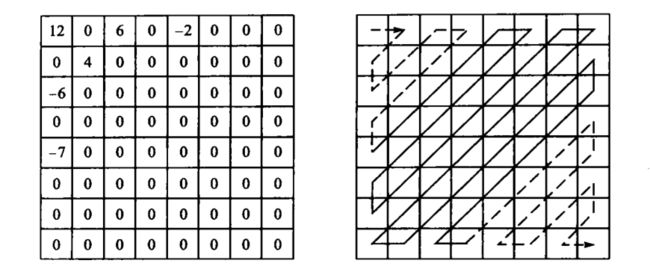
如上图所示,对于一个只有少量非零系数的块,对0系数进行数据传输是很不划算的。所以根据块的数据形式对其进行编码。
首先,对块进行zigzag扫描,排列成串行数据序列:
12,0,0,-6,4,6,0,0,0,0,-7,0,0,0,-2,0,0 …..
然后在进行游程编码,编码结果为:
(0,12,0)(2,-6,0)(0,4,0)(0,6,0)(4,-7,0)(3,-2,1)
元组中的第一个变量表示非零系数前0的个数,即游程。第二个变量表示非零系数,第3个变量为终止标志,常用1表示游程编码接受。
量化编码
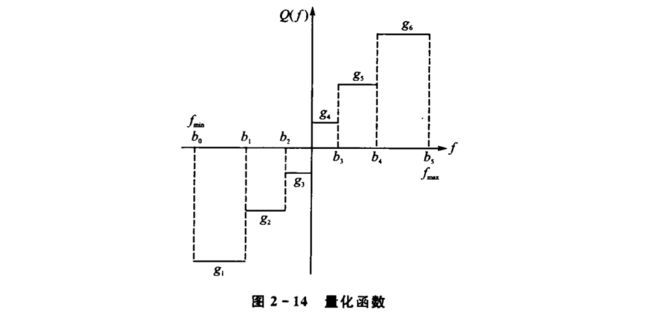
标量量化
标量量化是最基本的有损编码工具,它通过将信源映射成码字表中的码字来达到压缩目的。标量量化又分为均匀量化、非均匀量化和自适应量化。
矢量量化
矢量量化是一次量化多个样本点的量化方法,即将输入数据几个一组地分成许多组,成组的进行量化编码。
熵编码
熵
熵描述了信号源的各事件的平均信号量。
[图片上传失败...(image-589b2c-1510910497136)]
比如现在有一枚硬币,抛出这枚硬币,落地时硬币是正面的概率是1/2,是反面的概率也是1/2。那么抛硬币这个事件的熵为 1bit。 简单的理解就是,落地时,硬币是不是正面,有“是”和“否”2种情况,需要用一个1bit来表示;落地时,硬币是不是反面,也是有
“是”和“否”2种情况,也需要用1bit来表示;所以,总熵值就是 = 正面的概率*正面的熵 + 反面的概率*反面的熵
熵编码的基本原理
数据压缩的基本途径之一是使各字符的编码长度尽量等于字符的信息量。熵作为理论上的平均信息量,即编码一个信源符号所需要的二进制位数。实际的压缩编码中的码率很难达到熵值,不过熵可以作为一个标准,越接近熵值,压缩率越高。
Huffman 编码
对于出现频率高的信息,编码的长度较短;而对于出现频率较低的信息,比那么长度较长。
算法编码
对于CADACDB进行算术编码
[图片上传失败...(image-a40492-1510910497136)]