原文地址:http://chenzhijun.me/2017/12/12/elasticsearch-logstash-kibana-part/,欢迎大家留言交流
基于ELK+Filebeat搭建日志中心
实验环境
- ubuntu 16
- jdk 1.8
- elasticesearch 6.0, kibana 6.0, logstash 6.0, filebeat 6.0
我也在windows10下安装过,win10下只需要修改filebeat的文件路径配置就可以了。
概念介绍
elastic提供了非常多的工具,官方称为Elastic Stack。它提供了一些解决方案。我们用到的就是其中Stack中的部分工具
- Elasticsearch
Elasticsearch 是一个分布式、可扩展开源全文搜索和分析引擎。它能够进行存储,并且能以很快的速度(接近实时)来进行搜索和分析大量的数据。它使用Java编写,底层基于Apache Lucene。
- Logstash
Logstash 是一个开源的,服务端数据处理管道。 它可同时从多个源来搜集数据,对数据进行过滤等操作,并且将数据传送到你想要传送的地方进行存储。
- Kibana
Kibana 被设计成一个和Elasticsearch共同使用的开源分析和可视化平台,它支持将ES中存储的数据生成多种维度的图等。
- Filebeat
Filebeat 是一个轻量级的日志采集器,用于将源数据采集后发送给Logstash,并且Filebeat使用背压敏感协议,以考虑更多的数据量。如果Logstash正在忙于处理数据,则可以让Filebeat知道减慢读取速度。还有很多Beat可以提供选择,有监控网络的Packbeat,指标Metricbeat。各种beat详情:https://www.elastic.co/cn/products/beats
系统架构简图如下:
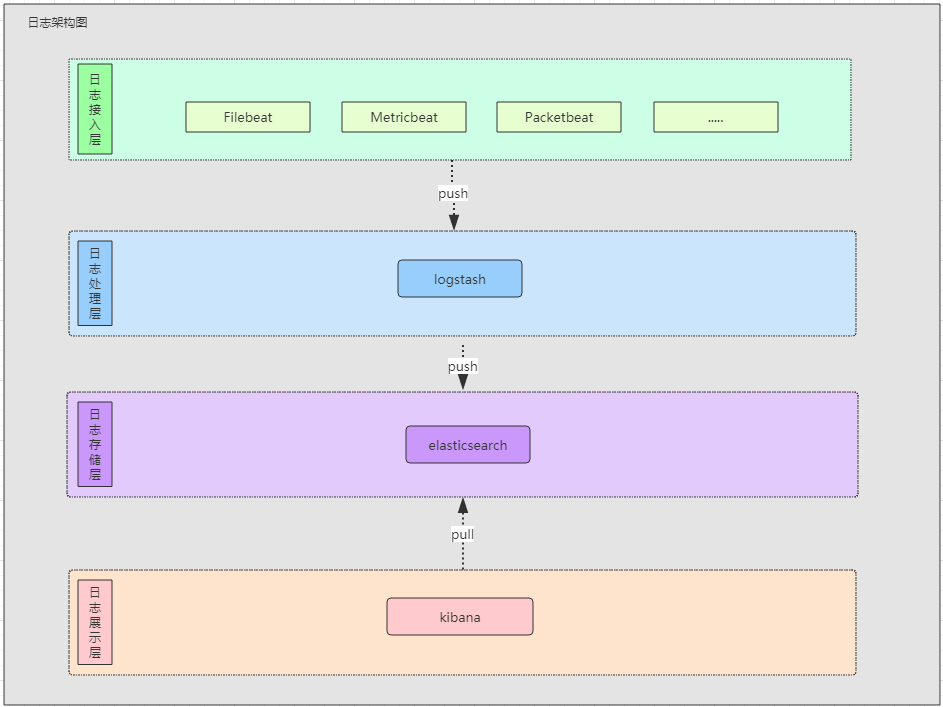
环境搭建
将ELK和filebeat下载后解压到一个目录下,四个产品都是开箱即用的。
Logstash安装与配置
Logstash的作用主要是用来处理数据,当然它也可以直接从日志文件读取记录然后进行处理。在Logstash的根目录,我们需要建立一个新文件logstash.conf:
# 配置logstash输入源
input {
beats {
host => "localhost"
port => "5043" #注意要和filebeat的输出端口一致
}
}
# 配置输出的地方
output {
# 控制台
stdout { codec => rubydebug }
# es
elasticsearch {
hosts => [ "localhost:9200" ]
}
}
Filebeat安装与配置
Filebeat作为日志搜集器,肯定是需要指定输入源和输出地,所以我们需要先配置它。在Filebeat的根目录下我们需要在filebeat.yml中:
# 输入源
filebeat.prospectors:
- type: log
paths:
- /var/log/*.log # 日志文件以log结尾并且需要放在/var/log目录下
# 如果是windows,如下
# - C:\Users\chen\Desktop\elastic\elkjava\log\*.log
# 输出地
output.logstash:
# The Logstash hosts
hosts: ["localhost:5043"]
Elasticsearch和Kibana安装与配置
这次演示我们对es和kibana不做特别的配置,就默认就好了。
启动顺序
其实没有特别的顺序,我一般的启动顺序是elasticsearch->logsatsh->kibana->filebeat。其实差别都不大,特别注意一个就是,如果你想要测试的话,logstash支持配置自动更新,如果是日志文件更新,想让filebeat重新再搜索一次,删除掉filebeat根目录下data/registry文件。其实类推,如果要删除其它的软件(elk)的的数据,删掉data目录,很直接很暴力,但不建议在正式场景直接这样弄。
启动es:
./bin/elasticsearch
启动logstash:
# 测试conf文件是否正确配置
./bin/logstash -f logstash.conf --config.test_and_exit
# 启动logstash,如果有修改conf会自动加载
./bin/logstash -f logstash.conf --config.reload.automatic
启动kibana:
./bin/kibana
启动filebeat:
./filebeat -e -c filebeat.yml -d "publish"
现在在浏览器中输入:http://localhost:5601打开kibana,
看到下面的图:

点击create,之后再点击左侧导航栏Discover:

就能看到值了。
不管怎么样,一定要动手实验才知道能不能行。
进阶实战:收集Java日志
上面搭建的elk是可以用的,但是在实际中我发现一些需要处理的地方,比如Java的日志文件经常将堆栈打印出来,这个时候如果还是按照上面的配置,我们无法正确的显示在kibana中,因为我们上面实际配置的是按行读取的。但是堆栈信息应该是一条。所以我们需要对日志进行一些多行处理。
可以在filebeat中处理,也可以在logstash中处理。
我们今天直接在filebeat中处理,让logstash只做日志的过滤。
首先准备一份Java的日志文件,大致的日志文件都会像下面这样格式:date log-level log-message=》时间 日志级别 日志内容,下面是一个抛出空指针的文件(有删减):
2017-12-06 16:59:38,927 WARN ExceptionHandlerExceptionResolver:391 Failed to invoke @ExceptionHandler method: public com.framework.common.model.ResultData com.elasticsearch.exception.IntegralExceptionHandler.exceptionHandler(java.lang.Exception)
java.lang.NullPointerException
at com.framework.common.util.SpringUtils.getMessage(SpringUtils.java:152) ~[classes/:?]
at com.framework.common.util.SpringUtils.getMessage(SpringUtils.java:138) ~[classes/:?]
at com.framework.common.util.SpringUtils.getMessage(SpringUtils.java:57) ~[classes/:?]
at com.elasticsearch.exception.IntegralExceptionHandler.exceptionHandler(IntegralExceptionHandler.java:33) ~[classes/:?]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_121]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_121]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_121]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_121]
在filebeat中主要是将堆栈信息的内容合并到一行中,也就是说发送给logstash的时候将下面的异常堆栈当作log-message,让filebeat读取到堆栈的时候将空行转义成字符串然后将这行的信息补充到第一行后面。我们可以使用filebeat的multiline配置,详情:https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html
filebeat.yml:
filebeat.prospectors:
- type: log
paths:
- /var/log/*.log # 日志文件以log结尾并且需要放在/var/log目录下
# 如果是windows,如下
# - C:\Users\chen\Desktop\elastic\elkjava\log\*.log
multiline: # 多行处理,正则表示如果前面几个数字不是4个数字开头,那么就会合并到一行
pattern: ^\d{4}
negate: true # 正则是否开启,默认false不开启
match: after # 不匹配的正则的行是放在上面一行的前面还是后面
output.logstash:
# The Logstash hosts
hosts: ["localhost:5043"]
同样的这次我们对Java日志做一些信息提炼,也就是使用过滤规则,将date,log-level,log-message等提取出来:
logstash.conf:
input {
beats {
host => "localhost"
port => "5043"
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:level} %{JAVALOGMESSAGE:msg}" }
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => [ "localhost:9200" ]
}
}
值得注意的就是我们使用filter插件,在其中我们使用了grok(基于正则表达式)过滤我们的日志内容。grok可以将无规则的日志数据通过正则匹配将之转换成有结构的数据,以此我们能够根据相应结构进行查询。grok的使用方式是:%{规则:自定义字段名称}
grok详情
Logstash提供了很多grok表达式,详情可以看:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
为了效果,我们可以删除filebeat,es,logstash,kibana等根目录的data文件,然后按照之前的步骤重启这些工具,
现在可以在kibana中看到相应的结果了:
先看到我们自定义的字段:
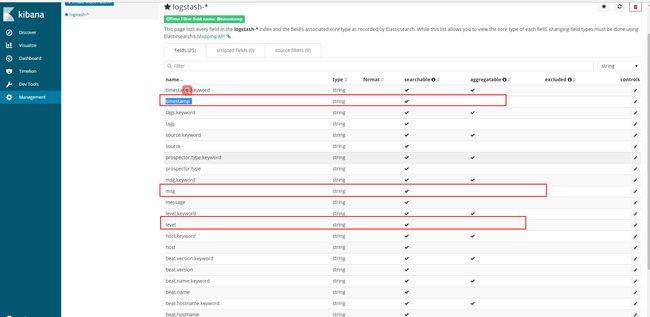
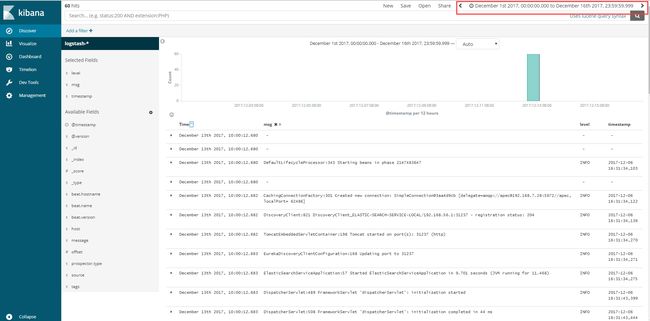
在Discover中过滤字段:

结果:
目前就告一段落了,最主要的是自己动手时间。接下准备做的事情是将这些能一个Dockerfile,然后只需要自己配置下filebeat的收集目录和logstash的过滤规则,我们就能使用了。
不管怎样只有自己动手去做了,才会知道有很多坑需要填。我也在google搜了很多资料,本来想在文后加个参考链接的,后来发现太多了。算了,还是不贴链接了。总之,谢谢哪些我在网上搜资料给了我灵感,帮我跨过一些坑的人。谢谢。
纸上得来终觉浅,绝知此事要躬行。