内存管理与数据存储

索引(index):Lucene的索引由许多个文件组成,这些文件放在同一个目录下
段(segment):一个Lucene的索引由多个段组成,段与段之间是独立的。添加新的文档时可以生成新的段,达到阈值(段的个数,段中包含的文件数等)时,不同的段可以合并。在文件夹下,具有相同前缀的文件属于同一个段segments.gen 和 segments_N(N表示一个具体数字,eg:segments_5)是段的元数据文件,他们保存了段的属性信息。
文档(document):文档时建索引的基本单位,一个段中可以包含多篇文档。新添加的文档时单独保存在一个新生成的段中,随着段的合并,不同的文档会合并到至相同的段中。
域(Field):一个文档有可由多个域(Field)组成,比如一篇新闻,有 标题,作者,正文等多个属性,这些属性可以看作是文档的域。不同的域可以指定不同的索引方式,比如指定不同的分词方式,是否构建索引,是否存储等
词(Term):词 是索引的最小单位,是经过词法分词和语言处理后的字符串。
Lucene的索引结构中,即保存了正向信息,也保存了反向信息。
正向信息:
按层次保存了从索引,一直到词的包含关系:索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)
也即此索引包含了那些段,每个段包含了那些文档,每个文档包含了那些域,每个域包含了那些词。
既然是层次结构,则每个层次都保存了本层次的信息以及下一层次的元信息,也即属性信息,比如一本介绍中国地理的书,应该首先介绍中国地理的概况,以及中国包含多少个省,每个省介绍本省的基本概况及包含多少个市,每个市介绍本市的基本概况及包含多少个县,每个县具体介绍每个县的具体情况。
如上图,包含正向信息的文件有:
segments_N保存了此索引包含多少个段,每个段包含多少篇文档。
XXX.fnm保存了此段包含了多少个域,每个域的名称及索引方式。
XXX.fdx,XXX.fdt保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
XXX.tvx,XXX.tvd,XXX.tvf保存了此段包含多少文档,每篇文档包含了多少域,每个域包含了多少词,每个词的字符串,位置等信息。
反向信息:
保存了词典到倒排表的映射:词(Term) –> 文档(Document)
如上图,包含反向信息的文件有:
XXX.tis,XXX.tii保存了词典(Term Dictionary),也即此段包含的所有的词按字典顺序的排序。
XXX.frq保存了倒排表,也即包含每个词的文档ID列表。
XXX.prx保存了倒排表中每个词在包含此词的文档中的位置。
倒排
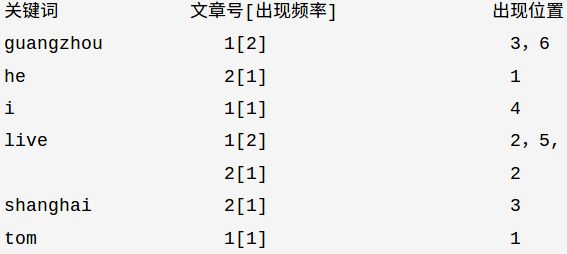
倒排存储示例
文章1的所有关键词为:[tom] [live] [guangzhou] [i] [live] [guangzhou] 文章2的所有关键词为:[he] [live] [shanghai]
通常有两种位置:
a.字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
b.关键词位置,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种位置。
lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
倒排信息
参考链接:Lucene索引过程中的内存管理与数据存储
在Lucene的设计里,IntBlockPool和ByteBlockPool的作用域是IndexChain,即每个IndexChain都会生成独立的ByteBlockPool和IntBlockPool ,这样就不会出现多线程间可变数据共享的问题,这种做法实际上是一种约定方式的线程封闭,即ByteBlockPool本身并不是线程安全的,不像ThreadLocal或者栈封闭。由于每个IndexChain都需要处理多个Field,所以IntBlockPool和ByteBlockPool是Field所共享的。需要注意的是ParallelPostingsArray的作用域是Field,即每个Field都有一个postingsArray。
ParallelPostingsArray的三个成员变量:
textStarts存储的是每一个term在ByteBlockPool里面的起始位置,通过textStarts[termID]可以快速找到termID对应的term 。
byteStarts存储的是term在ByteBlockPool的结束位置的下一个位置。
IntStarts存储的是term在IntBlockPool的地址信息,而IntBlockPool则存储着term在ByteBlockPool中的Slice位置信息。
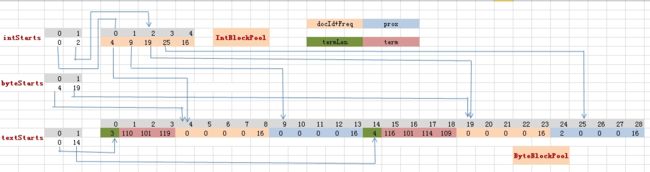
DOCID;Freq;Positions这三种信息都是随着Term存储在ByteBlockPool中,其存储过程如下:
第一步:把term.length存储到ByteBlockPool.buffer中。这会占用1或者2个byte,由term的大小决定。由于term的最大长度为32766,所以term.length最多会占用两个byte。
第二步:把term的byte数组形式存储到ByteBlockPool.buffer中。
第三步:紧接着term开辟5个byte大小的slice,用来存储term在每个doc中的freq信息。
第四步:再开辟一块Slice用来存储positions信息。
Lucene存储在索引中的并非真正的docId,而是docDelta,即两个docId的差值.这样存储能够起到节约空间的作用。
索引实现
参考链接:Lucene底层实现原理,它的索引结构
Lucene3.0之前使用的也是跳跃表结构,后换成了FST,但跳跃表在Lucene其他地方还有应用如倒排表合并和文档号索引。
FST
理论基础:《Direct constructionofminimal acyclic subsequential transducers》,通过输入有序字符串构建最小有向无环图。
优点:内存占用率低,压缩率一般在3倍~20倍之间、模糊查询支持好、查询快
缺点:结构复杂、输入要求有序、更新不易
Lucene里有个FST的实现,从对外接口上看,它跟Map结构很相似,有查找,有迭代。

倒排索引

往索引库里插入四个单词abd、abe、acf、acg,看看它的索引文件内容如下:
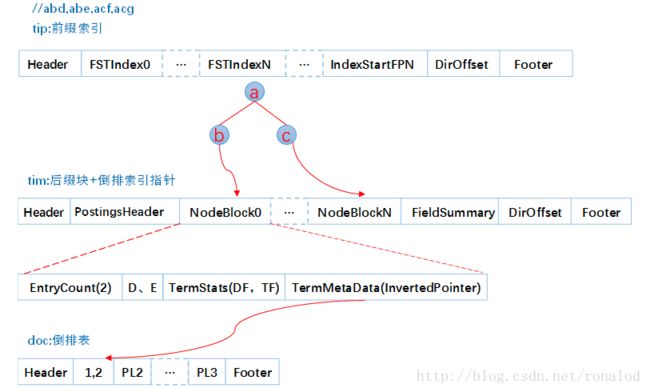
构建过程如下:

Lucene的FST实现的主要优化策略有:
1. 最小后缀数。Lucene对写入tip的前缀有个最小后缀数要求,默认25,这时为了进一步减少内存使用。如果按照25的后缀数,那么就不存在ab、ac前缀,将只有一个跟节点,abd、abe、acf、acg将都作为后缀存在tim文件中。我们的10g的一个索引库,索引内存消耗只占20M左右。
2.前缀计算基于byte,而不是char,这样可以减少后缀数,防止后缀数太多,影响性能。如对宇(e9 b8 a2)、守(e9 b8 a3)、安(e9 b8 a4)这三个汉字,FST构建出来,不是只有根节点,三个汉字为后缀,而是从unicode码出发,以e9、b8为前缀,a2、a3、a4为后缀。
倒排表的docId压缩

跳跃表加速合并,因为布尔查询时,and 和or 操作都需要合并倒排表,这时就需要快速定位相同文档号,所以利用跳跃表来进行相同文档号查找。
正排:
正向信息在Lucene中只有docId-document的映射,由CompressingStoredFieldsWriter类来完成。
Lucene的正向信息存储比较简单,按Field依次把内容写入到bufferedDocs中,然后把偏移量写入到endOffsets中就OK了。
当满足flush条件或者执行了IndexWriter.commit()方法,则会进行一次flush操作,把内存中缓存的document及倒排信息flush到硬盘中。
正向索引
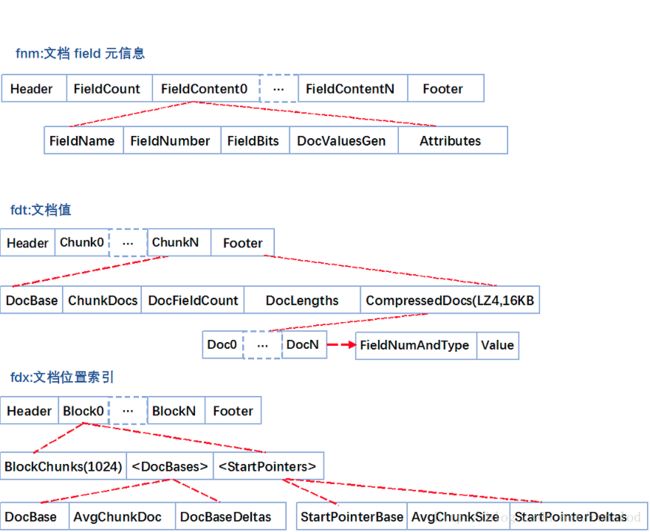
fnm中为元信息存放了各列类型、列名、存储方式等信息。

fdt为文档值,里面一个chunk就是一个块,Lucene索引文档时,先缓存文档,缓存大于16KB时,就会把文档压缩存储。一个chunk包含了该chunk起始文档、多少个文档、压缩后的文档内容。
fdx为文档号索引,倒排表存放的时文档号,通过fdx才能快速定位到文档位置即chunk位置,它的索引结构比较简单,就是跳跃表结构,首先它会把1024个chunk归为一个block,每个block记载了起始文档值,block就相当于一级跳表。

所以查找文档,就分为三步:
第一步二分查找block,定位属于哪个block。
第二步就是根据从block里根据每个chunk的起始文档号,找到属于哪个chunk和chunk位置。
第三步就是去加载fdt的chunk,找到文档。这里还有一个细节就是存放chunk起始文档值和chunk位置不是简单的数组,而是采用了平均值压缩法。所以第N个chunk的起始文档值由DocBase + AvgChunkDocs * n + DocBaseDeltas[n]恢复而来,而第N个chunk再fdt中的位置由StartPointerBase + AvgChunkSize * n + StartPointerDeltas[n]恢复而来。
从上面分析可以看出,lucene对原始文件的存放是行式存储,并且为了提高空间利用率,是多文档一起压缩,因此取文档时需要读入和解压额外文档,因此取文档过程非常依赖随机IO,以及lucene虽然提供了取特定列,但从存储结构可以看出,并不会减少取文档时间。
列式存储

词向量 信息是从索引(index)到文档(document)到域(field)到词(term)的正向信息,有了词向量信息,就可以得到一篇文档包含哪些词的信息。
Lucene目前有五种类型的DocValues:NUMERIC、BINARY、SORTED、SORTED_SET、SORTED_NUMERIC,针对每种类型Lucene都有特定的压缩方法。
如对NUMERIC类型即数字类型,数字类型压缩方法很多,如:增量、表压缩、最大公约数,根据数据特征选取不同压缩方法。
SORTED类型即字符串类型,压缩方法就是表压缩:预先对字符串字典排序分配数字ID,存储时只需存储字符串映射表,和数字数组即可,而这数字数组又可以采用NUMERIC压缩方法再压缩。

对DocValues的应用,ElasticSearch功能实现地更系统、更完整,即ElasticSearch的Aggregations——聚合功能,它的聚合功能分为三类: Metric -> 统计 、 Bucket ->分组 、 Pipline -> 基于聚合再聚合 。

相关链接:Lucene原理与代码分析完整版