现在很多教科书都还在说java中一个字符是2个字节。可是这个命题从J2SE的5.0版开始就变成了假命题了。我们知道,Java中字符是Unicode字符,Unicode字符有2个字节或4个字节表示。因此,从J2SE的5.0版开始,一个字符可以是2个字节或4个字节。然而,有趣的是,java一个char类型的变量依然是2个字节的空间!!!换言之,java中四字节字符则是需要两个char合起来(即new char[2])才能表示!
内码和外码
简单地理解,内码是指程序运行过程中字符的编码值,例如Jvm中字符的码制。其中,内码也是有格式的,如jvm中字符的内码是UTF-16编码格式的。
从Unicode演进说起
Unicode设计之初,全球化进程还很慢,设计者觉得两个字节(65536)已经足够表示全球已知文化的字符了。后来,全球化不断深入成为地球村,尤其互联网发展更是将世界链接地严密。此时很多小众文化的字符也慢慢冒出来,要求登上历史舞台。于是Unicode的两个字节就不够用了,必须要扩展。后来人们决定扩展到4个字节来表示。那些超出原来的16位限制的字符被称作增补字符。Unicode标准2.0版是第一个包含启用增补字符设计的版本,但是,直到3.1版才收入第一批增补字符集。各中语言为了市场肯定得与时俱进,因而J2SE的5.0版开始必须支持Unicode标准4.0版,因此它必须支持增补字符。在Unicode 3.1中,台湾标准CNS-11643包含的许多字符列为增补字符。香港政府定义了一种针对粤语的字符集,其中的一些字符是Unicode中的增补字符。日本的一些供应商正计划利用增补字符空间中大量的专用空间收入50 000多个日文汉字字符变体,以便从其专有系统迁移至基于Java平台的解决方案。
当Unicode字符表中的字符超过两个字节,新增的字符其实在字符表中仅仅是序号增加1而已。然而当在程序中采用两个或4个字节表示,那么同样会出现多字节方案中的混淆问题:如何判断某两个字节是一个两字节字符的全部字节还是一个四字节字符中的两个字节? 这个问题必须要解决的。
明显,由于这个问题的出现,我们无法再保证utf-16格式能够和Unicode字符表上的序号保持一致了,因此程序中(运行时)的字符内码也不能够和Unicode字符表上的序号保持一致了。其中大部分程序语言的字符内码都按照Utf-16格式。
设计者们是这样解决的:
1) 首先我们要了解两个术语:代码单元和代码点。代码点比较好理解,就是字符表上每个字符的唯一号码。代码单元(Code Unit)则是针对编码方法而言,它指的是编码方法中对一个字符编码以后所占的最小存储单元。例如UTF-8中,代码单元是一个字节,因为所有字符可以被编码为1个,2个或者3个4个字节;在UTF-16中,代码单元变成了两个字节(就是一个char),因为所有字符可以被编码为1个或2个char。因而一个字符,仅仅对应一个代码点,但却可能有多个代码单元(对于不同的编码格式)。
2) 初期Unicode字符的两字节字符,被称为BMP。Unicode字符表空间其实还剩下部分空间为使用。即有部分代码点的一个代码单元未使用。于是,对于增补字符,四个字节的话,人们就:前一个代码单元则用 初期Unicode字符表中未使用的空间,后一个代码单元则作为剩下的部分(U+D800~U+DBFF用于第一个代码单元,U+DC00〜U+DFFF用于第二个代码单元)。两个代码单元合起来也是可以实现唯一序号。于是增补字符的表示就规范统一起来了。
这样的设计其实巧。当我们读取前两个字节(第一个代码单元)是落在U+D800~U+DBFF时,我们可以立马知道还要读入两个字节才能合成一个完整正确的字符。否则就是两字节字符了。
jdk中API
我们知道java中字符是Unicode字符,对于序号在前16位的字符跟Utf-16编码格式方案“长得一样”,序号超出16位的字符则是通过一套算法映射出来。java的内码(运行时的格式)其实是Utf-16格式。
java为String实例提供了length()、charAt(int)方法。可是这两个方法并没有我们想象中那么简单!注意下方高能!!
length():返回的是UTF-16编码表示下的代码单元数量,而非我们所认为的字符的个数;
charAt(int):返回的是指定位置处的代码单元,而非我们所认为的字符。
【我相信很多开发人员平时都是直接用length()以为是获取到字符个数了。不过一般情况不会出错,因为平时我们真的极少遇到增补字符的情况】
那么如果我们要获取其真正的字符个数,即代码点的个数,我们就要如下:
str.codePointCount(0,str.length())
这是jdk提供的API。意思是: 对str中的char数组对应的所有代码单元(2字节)进行整合识别以获取代码点(codePoint)的个数。
跟代码点相关的api还有:
str.offsetByCodePoints(int , int)
str.codePointAt(int)
......等等。
代码演示
正如上面所说的,Java从1.5版本开始,加入了unicode增补字符的支持。相关的API主要在Character和String类里(String类都是基于Character的)。增补字符是用一个长度为2的char数组表示的,分别表示高代理项(High Surrogate)和低代理项(Low Surrogate)。
(1) 以Unicode增补字符0x0001D307为例:
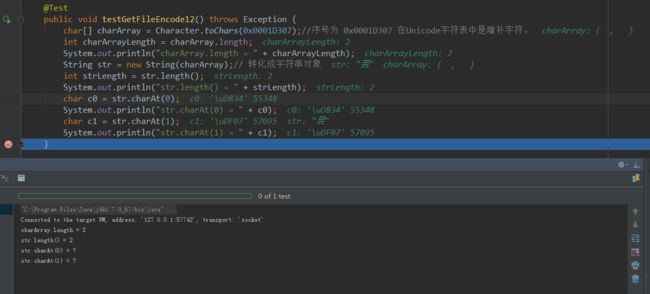
解析:我们可以看到,0x0001D307是一个Unicode字符,可是,它在jvm内码(UTF-16格式)中是需要两个char组成的数组才能表达。这也就证实了文章开头说的:char类型变量是占两个字节空间,可是java中的一个字符并非都是两个字节可以表示。变量c0和c1,由于分别刚好落在U+DC00〜U+DFFF之间,所以没有对应的字符(图形),所以IDE控制台也无法显示只能给个?。
(2) 如上面jvm中字符内码是Utf-16格式的。当我们将char字符直接转化成int ,或者 将int直接转化成char,这个过程中的int在jvm中都被认为是某个Unicode字符的码值。如下图:
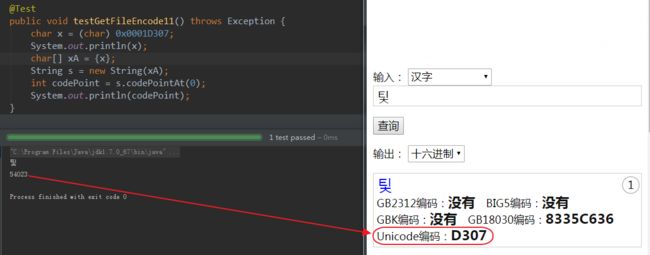
解析:我们可以看到,0x0001D307强制转化的字符是 팇 ,而 팇 在unicode字符表上的序号是0xD307 ,即54023。