本章内容
1.数学和统计函数
2.字符处理函数
3.循环和条件执行
4.自编函数
5.数据整合与重塑
第一部分,我们将快速浏览R中的多种数学、统计和字符处理函数。为了让这一部分的内容相互关联,我们先引入一个能够使用这些函数解决的数据处理问题。在讲解过这些函数以后,再为这个数据处理问题提供一个可能的解决方案。
第二部分,我们将讲解如何自己编写函数来完成数据处理和分析任务。首先,我们将探索控制程序流程的多种方式,包括循环和条件执行语句。然后,我们将研究用户自编函数的结构,以及在编写完成后如何调用它们。
第三部分,我们将了解数据的整合和概述方法,以及数据集的重塑和重构方法。在整合数据时,你可以使用任何内建或自编函数来获取数据的概述,所以你在本章前两部分中学习的内容将会派上用场。
5.1 利用R中的数值和字符处理函数处理解决实际问题
5.2 数值和字符处理函数
R中数据处理函数,它们可分为数值(数学、统计、概率)函数和字符处理函数。
本例将展示如何将函数应用到矩阵和数据框的列(变量)和行(观测)上。
01 数学函数
参考书籍表5-2,表中列出了常用的数学函数和简短的用例。表中共计13类常用的数学函数,主要作用是对数据进行变换和运算。表中函数被应用于数值向量、矩阵或数据框时,它们会作用于每一个独立的值。例如,
sqrt(c(4, 16, 25)) 的返回值为 c(2,4, 5)。
02 统计函数
常用的统计函数参考书籍表5-3,表中许多函数参数都是可选的,参数不同,结果亦不同,比如求平均数、中位数、标准差、方差等。

#实战应用如下。均值和标准差计算如下,上面的代码是简洁方式,下面的冗长方式。
> x <- c(1,2,3,4,5,6,7,8)
> mean(x) #直接用函数求平均数
[1] 4.5
> sd(x) #直接用函数求标准差
[1] 2.449490
> n <- length(x) #x中的数量
> meanx <- sum(x)/n #先求和,在算平均数
> css <- sum((x - meanx)^2) # (x – meanx)^2从 x 的每个元素中减去了4.5,然后每个元素求平方,最后计算出平方的和
> sdx <- sqrt(css / (n-1)) #平方和除以数量减1,等于42/7=6,然后求出6的平方根,即为标准差
> meanx
[1] 4.5
> sdx
[1] 2.449490
数据标准化具体使用scale()函数,默认对矩阵或数据框的指定列进行均值为0、标准差为1的标准化。
03 概率函数
概率函数通常用来生成特征已知的模拟数据,以及在用户编写的统计函数中计算概率值。
在R中,概率函数形如 :
[dpqr]distribution_abbreviation()
其中第一个字母表示其所指分布的某一方面:
d = 密度函数(density)
p = 分布函数(distribution function)
q = 分位数函数(quantile function)
r = 生成随机数(随机偏差)
常用的概率函数列于表5-4中。
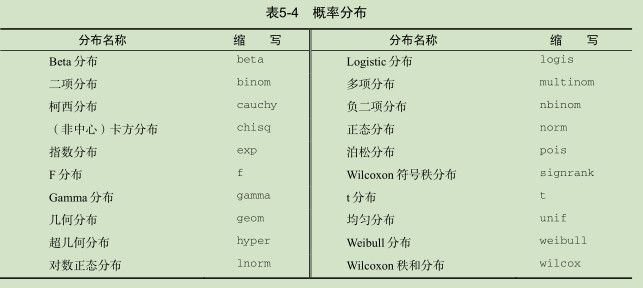
x <- pretty(c(-3,3), 30)
y <- dnorm(x)
plot(x, y,
type = "l",
xlab = "Normal Deviate",
ylab = "Density",
yaxs = "i"
) #绘制正态曲线
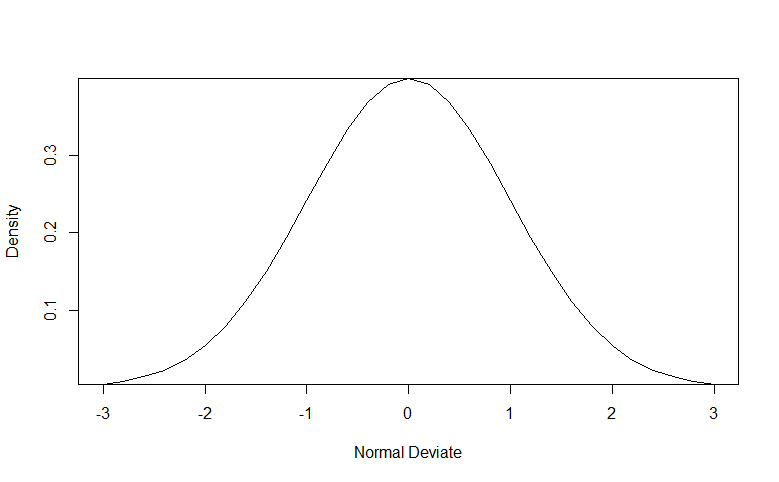
x <- pretty(c(-3,3), 30)
z<-pnorm(x)
plot(x, z,
type = "l",
xlab = "Normal Deviate",
ylab = "Distribution",
yaxs = "i"
) #绘制分布函数
> pnorm(1.96) #位于z=1.96左侧的标准正态曲线下方面积是多少?
[1] 0.9750021
> qnorm(.9,mean = 500,sd=100)# 均值为 500,标准差为 100的正态分布的0.9分位点值为多少?
[1] 628.1552
> rnorm(50,mean = 50,sd=10) #生成 50个均值为 50,标准差为 10的正态随机数
[1] 51.87839 45.35005 59.93238 55.93086 60.02875 45.77850
[7] 40.00659 43.05473 66.34199 53.04694 55.62084 60.13278
[13] 39.26552 44.50102 65.56196 67.33899 44.08626 50.22214
[19] 41.26078 40.60966 54.02655 53.23637 49.32678 42.60044
[25] 66.34560 61.51955 51.37980 56.66308 56.71551 53.26159
[31] 50.68065 52.63917 38.80761 51.67646 50.47654 73.45159
[37] 49.58523 57.85701 40.33247 49.27015 48.60540 52.38546
[43] 42.89752 67.62153 45.24686 44.32443 42.24713 41.93737
[49] 46.12039 48.04349
#生成0~1区间上服从正态分布的伪随机数:
> runif(5)
[1] 0.8923759 0.2876101 0.2292473 0.7666098 0.8240967
> runif(5)
[1] 0.29292497 0.04201844 0.96997523 0.21433377 0.41058722
> set.seed(1234)#显示并指定函数使用的种子
> runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
> set.seed(1234)#目的为让重复上次的结果
> runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
>
#生成多元正态数据,使用MASS 包中的 mvrnorm() 函数,其格式为mvrnorm(n, mean, sigma),
其中 n 是你想要的样本大小, mean 为均值向量,而 sigma 是方差—协方差矩阵(或相关矩阵)
#生成服从多元正态分布的数据
library(MASS)
options(digits = 3)
set.seed(1234)#设定随机数种子
mean<-c(230.7,146.7,3.6)#均值向量
sigma<-matrix(c(15360.8, 6721.2, -47.1, 6721.2,
4700.9, -16.5, -47.1, -16.5, 0.3),
nrow = 3,ncol = 3)#协方差阵
mydata<-mvrnorm(500,mean,sigma)#生成多元正态数据
mydata<-as.data.frame(mydata)#矩阵转换为数据框
names(mydata)<-c("y","x1","x2")#对变量进行重命名
dim(mydata)#确认观测的结果
head(mydata,n=10)#输出前十个观测结果
dim(mydata)
[1] 500 3
> head(mydata,n=10)
y x1 x2
1 98.8 41.3 3.43
2 244.5 205.2 3.80
3 375.7 186.7 2.51
4 -59.2 11.2 4.71
5 313.0 111.0 3.45
6 288.8 185.1 2.72
7 134.8 165.0 4.39
8 171.7 97.4 3.64
9 167.2 101.0 3.50
10 121.1 94.5 4.10
04. 字符处理函数
数学和统计函数是用来处理数值型数据的,而字符处理函数可以从文本型数据中抽取信息,设定随机数种子指定均值向量、协方差阵生成数据查看结果或者为打印输出和生成报告重设文本的格式。
一些最有用的字符处理函数见表5-6。

05.其他实用函数

06.将函数应用于矩阵和数据框
举例如下:
> a<-5
> sqrt(a)
[1] 2.236068
> b<-c(1.243,5.654,2.99)
> round(b)
[1] 1 6 3
> c<-matrix(runif(12),nrow = 3)
> c
[,1] [,2] [,3] [,4]
[1,] 0.96359936 0.2160280 0.2890082 0.9128172
[2,] 0.20676238 0.2396466 0.8041144 0.3533918
[3,] 0.08619744 0.1971609 0.3782496 0.9314871
> log(c)
[,1] [,2] [,3] [,4]
[1,] -0.03707967 -1.532347 -1.2413001 -0.09121962
[2,] -1.57618505 -1.428590 -0.2180137 -1.04017797
[3,] -2.45111479 -1.623735 -0.9722009 -0.07097292
> mean(c) #对c中12个元素进行求均值
[1] 0.4648719
R中提供了一个apply()函数,可将一个任意函数“应用”到矩阵、数组、数据框的任何维度上。 apply() 函数的使用格式为:apply(x, MARGIN, FUN, ...) 其中, x为数据对象, MARGIN是维度的下标, FUN是由你指定的函数,而...则包括了任何想传
递给FUN的参数。在矩阵或数据框中,MARGIN=1表示行,MARGIN=2表示列。
举例如下:将一个函数应用到矩阵的所有行(列)
> mean(c)
[1] 0.4648719
> mydata<-matrix(rnorm(30),nrow = 6)
> mydata
[,1] [,2] [,3] [,4] [,5]
[1,] 0.4585260 1.2031271 1.2338845 0.5905186 -0.2806204
[2,] -1.2611491 0.7688732 -1.8913847 -0.4351408 0.8120776
[3,] -0.5274652 0.2383510 -0.2226513 -0.2507699 -0.2077037
[4,] -0.5568142 -1.4150281 0.7681275 -0.9262694 1.4507573
[5,] -0.3744387 2.9337744 0.3879537 1.0874358 0.8414932
[6,] -0.6044000 0.9350258 0.6091330 -1.9439592 -0.8657378
> apply(mydata,1,mean)
[1] 0.6410872 -0.4013448 -0.1940478 -0.1358454 0.9752437 -0.3739876
> apply(mydata,2,mean)#对每列进行求均值
[1] -0.4776235 0.7773539 0.1475105 -0.3130308 0.2917110
> apply(mydata,2,mean,trim=0.2)#求每列的截尾均值,最低和最高的20%均值被忽略
[1] -0.5157795 0.7863443 0.3856407 -0.2554154 0.2913117
>
5.3 数据处理难题的一套解决方案
代码清单5-6针对本章开始提出的问题给出了的解决方案。
> options(digits = 2)#限定小数点后两位
> Student<-c("John Davis","Angela Williams","Bullwinkle Moose",
+ "David Jones","Janice Markhamer","Cheryl Cushing",
+ "Reuven Ytzrhak","Greg Knox","Joel England","Mary Rayburn")
> Math<-c(502,600,412,358,495,512,410,625,573,522)
> Science<-c(95,99,80,82,75,85,80,95,89,86)
> English<-c(25,22,18,15,20,28,15,30,27,18)
> roster<-data.frame(Student,Math,Science,English,
+ stringsAsFactors = FALSE)#生成花名册
> roster#输出花名册
Student Math Science English
1 John Davis 502 95 25
2 Angela Williams 600 99 22
3 Bullwinkle Moose 412 80 18
4 David Jones 358 82 15
5 Janice Markhamer 495 75 20
6 Cheryl Cushing 512 85 28
7 Reuven Ytzrhak 410 80 15
8 Greg Knox 625 95 30
9 Joel England 573 89 27
10 Mary Rayburn 522 86 18
> z<-scale(roster[,2:4])#用scale函数把成绩全部用单位的标准差来表示
> z
Math Science English
[1,] 0.013 1.078 0.587
[2,] 1.143 1.591 0.037
[3,] -1.026 -0.847 -0.697
[4,] -1.649 -0.590 -1.247
[5,] -0.068 -1.489 -0.330
[6,] 0.128 -0.205 1.137
[7,] -1.049 -0.847 -1.247
[8,] 1.432 1.078 1.504
[9,] 0.832 0.308 0.954
[10,] 0.243 -0.077 -0.697
attr(,"scaled:center")
Math Science English
501 87 22
attr(,"scaled:scale")
Math Science English
86.7 7.8 5.5
> score<-apply(z,1,mean)#计算list各行的均值
> roster<-cbind(roster,score)#把各行均值score添加到roster中
> roster
Student Math Science English score
1 John Davis 502 95 25 0.56
2 Angela Williams 600 99 22 0.92
3 Bullwinkle Moose 412 80 18 -0.86
4 David Jones 358 82 15 -1.16
5 Janice Markhamer 495 75 20 -0.63
6 Cheryl Cushing 512 85 28 0.35
7 Reuven Ytzrhak 410 80 15 -1.05
8 Greg Knox 625 95 30 1.34
9 Joel England 573 89 27 0.70
10 Mary Rayburn 522 86 18 -0.18
> y<-quantile(score,c(.8,.6,.4,.2)) #使用分位数函数求学生的综合得分的百位分数
> y
80% 60% 40% 20%
0.74 0.44 -0.36 -0.89
#花名册中添加grade级别
> roster$grade[score>=y[1]]<-"A"
> roster$grade[score=y[2]]<-"B"
> roster$grade[score=y[3]]<-"C"
> roster$grade[score=y[4]]<-"D"
> roster$grade[score roster
Student Math Science English score grade
1 John Davis 502 95 25 0.56 B
2 Angela Williams 600 99 22 0.92 A
3 Bullwinkle Moose 412 80 18 -0.86 D
4 David Jones 358 82 15 -1.16 F
5 Janice Markhamer 495 75 20 -0.63 D
6 Cheryl Cushing 512 85 28 0.35 C
7 Reuven Ytzrhak 410 80 15 -1.05 F
8 Greg Knox 625 95 30 1.34 A
9 Joel England 573 89 27 0.70 B
10 Mary Rayburn 522 86 18 -0.18 C
> roster#加入级别变量后的花名册,并根据y的值进行排序
Student Math Science English score grade
1 John Davis 502 95 25 0.56 B
2 Angela Williams 600 99 22 0.92 A
3 Bullwinkle Moose 412 80 18 -0.86 D
4 David Jones 358 82 15 -1.16 F
5 Janice Markhamer 495 75 20 -0.63 D
6 Cheryl Cushing 512 85 28 0.35 C
7 Reuven Ytzrhak 410 80 15 -1.05 F
8 Greg Knox 625 95 30 1.34 A
9 Joel England 573 89 27 0.70 B
10 Mary Rayburn 522 86 18 -0.18 C
> name<-strsplit((roster$Student)," ")#进行字符串分割
> name
[[1]]
[1] "John" "Davis"
[[2]]
[1] "Angela" "Williams"
[[3]]
[1] "Bullwinkle" "Moose"
[[4]]
[1] "David" "Jones"
[[5]]
[1] "Janice" "Markhamer"
[[6]]
[1] "Cheryl" "Cushing"
[[7]]
[1] "Reuven" "Ytzrhak"
[[8]]
[1] "Greg" "Knox"
[[9]]
[1] "Joel" "England"
[[10]]
[1] "Mary" "Rayburn"
> Lastname<-sapply(name,"[",2)#提取列表中每个成分的第二个元素,放入一个储存名字
的向量Lastname
> Firstname<-sapply(name,"[",1)#提取列表中每个成分的第一个元素,放入一个储存名字
的向量Firstname
> roster<-cbind(Firstname,Lastname,roster[,-1])#把Firstname,Lastname列添加到花名册
> roster
Firstname Lastname Math Science English score grade
1 John Davis 502 95 25 0.56 B
2 Angela Williams 600 99 22 0.92 A
3 Bullwinkle Moose 412 80 18 -0.86 D
4 David Jones 358 82 15 -1.16 F
5 Janice Markhamer 495 75 20 -0.63 D
6 Cheryl Cushing 512 85 28 0.35 C
7 Reuven Ytzrhak 410 80 15 -1.05 F
8 Greg Knox 625 95 30 1.34 A
9 Joel England 573 89 27 0.70 B
10 Mary Rayburn 522 86 18 -0.18 C
> roster<-roster[order(Lastname,Firstname),]#对数据集按照姓和名进行排序
> roster
Firstname Lastname Math Science English score grade
5 Janice Markhamer 495 75 20 -0.63 D
6 Cheryl Cushing 512 85 28 0.35 C
2 Angela Williams 600 99 22 0.92 A
4 David Jones 358 82 15 -1.16 F
10 Mary Rayburn 522 86 18 -0.18 C
8 Greg Knox 625 95 30 1.34 A
9 Joel England 573 89 27 0.70 B
7 Reuven Ytzrhak 410 80 15 -1.05 F
1 John Davis 502 95 25 0.56 B
3 Bullwinkle Moose 412 80 18 -0.86 D
5.4 控制流
请牢记以下概念:
语句( statement )是一条单独的R语句或一组复合语句(包含在花括号 { } 中的一组R语句,使用分号分隔);
条件( cond )是一条最终被解析为真( TRUE )或假( FALSE )的表达式;
表达式( expr )是一条数值或字符串的求值语句;
序列( seq )是一个数值或字符串序列。
01.重复和循环
循环结构重复地执行一个或一系列语句,直到某个条件不为真为止。循环结构包括 for 和while 结构。
- for 结构
for 循环重复地执行一个语句,直到某个变量的值不再包含在序列 seq 中为止。语法为:
for (var in seq) statement
比如:
> for(i in 1:10)
> print("Hello")
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
- while 结构
while 循环重复地执行一个语句,直到条件不为真为止。语法为:
while (cond) statement
比如:
> i<-10
> while(i>0){print("Hello");i<-i-1}
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
[1] "Hello"
值得注意的是确保while括号内的语句在某个时刻不为真,否则循环将永不停止。建议联用R中的内建数值/字符处理函数和 apply 族函数。
2 条件执行
在条件执行结构中,一条或一组语句仅在满足一个指定条件时执行。条件执行结构包括if-else 、 ifelse 和 switch 。
if-else 结构
控制结构 if-else 在某个给定条件为真时执行语句。也可以同时在条件为假时执行另外的语句。语法为:
if (cond) statement
if (cond) statement1 else statement2ifelse 结构
ifelse 结构是 if-else 结构比较紧凑的向量化版本,其语法为:
ifelse(cond, statement1, statement2)
ifelse(score > 0.5, print("Passed"), print("Failed"))
outcome <- ifelse (score > 0.5, "Passed", "Failed")
在程序的行为是二元时,或者希望结构的输入和输出均为向量时,请使用 ifelse。switch 结构
switch 根据一个表达式的值选择语句执行。语法为:
switch(expr, ...)
举例如下:
> feelings<-c("sad","afraid")
> for(i in feelings)
+ print(switch(i,happy="I am glad you are happy",
+ afraid="There is nothing to fear",
+ sad="Cheer up",angary="Calm down now"))
[1] "Cheer up"
[1] "There is nothing to fear"
5.5 用户自编函数
R的最大优点之一就是用户可以自行添加函数。R中的许多函数都是由已有函数构成的。一个函数的结构看起来大致如此:
myfunction <- function(arg1, arg2, ... ){
statements
return(object)
}
函数中的对象只在函数内部使用。返回对象的数据类型是任意的,从标量到列表皆可。
比如:一个使用了 switch 结构的用户自编函数,此函数可让用户选择输出当天日期的格式。
> mydate<-function(type="long"){
+ switch(type,
+ long=format(Sys.time(),"%A %B %d %Y"),
+ short=format(Sys.time(),"%m-%d-%y"),
+ cat(type,"is not a recognized type\n")
+ )
+ }
> mydate("long")
[1] "星期二 三月 14 2017"
> mydate("short")
[1] "03-14-17"
> mydate("medium")
medium is not a recognized type
>
warning:可以使用warning()来生成一条错误信息,用message()来生成一条诊断信息,或者用stop()来停止当前表达式的执行并提示错误。上面的例子中,cat()函数仅会在输入的日期格式类型不匹配时,用一个表达式来捕获用户给出的错误参数值。这是针对自编函数的一个错误捕获和调试的方法。
5.6 整合与重构
R中提供了许多用来整合(aggregate)和重塑(reshape)数据的强大方法。在整合数据时,往往将多组观测替换为根据这些观测计算的描述性统计量。在重塑数据时,则会通过修改数据的结构(行和列)来决定数据的组织方式。
在接下来我们将使用已包含在R基本安装中的数据框mtcars 。这个数据集描述了34种车型的设计和性能特点(汽缸数、排量、马力、每加仑汽油行驶的英里数等等)。
01 转置
转置即反转行和列。使用函数** t()** 即可。
数据集的转置如下示例:
> cars<-mtcars[1:5,1:4]
> cars
mpg cyl disp hp
Mazda RX4 21.0 6 160 110
Mazda RX4 Wag 21.0 6 160 110
Datsun 710 22.8 4 108 93
Hornet 4 Drive 21.4 6 258 110
Hornet Sportabout 18.7 8 360 175
> t(cars)#进行转置
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout
mpg 21 21 22.8 21.4 18.7
cyl 6 6 4.0 6.0 8.0
disp 160 160 108.0 258.0 360.0
hp 110 110 93.0 110.0 175.0
>
02 整合数据
在R中使用一个或多个by变量和一个预先定义好的函数来折叠(collapse)数据是比较容易的。
调用格式为:
aggregate(x, by, FUN)
其中 x 是待折叠的数据对象, by 是一个变量名组成的列表,这些变量将被去掉以形成新的观测,而 FUN 则是用来计算描述性统计量的标量函数,它将被用来计算新观测中的值。
示例如下,我们将根据汽缸数和挡位数整合 mtcars 数据,并返回各个数值型变量的均值。
> options(digits = 3)
> attach(mtcars)
> aggdata<-aggregate(mtcars,by=list(cyl,gear),FUN = mean,
+ na.rm=TRUE)
> aggdata
Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb
1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3 1.00
2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3 1.00
3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3 3.08
4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4 1.50
5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4 4.00
6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5 2.00
7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5 6.00
8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5 6.00
>
03 reshape2包
使用install.packages("reshape2")安装reshape2包。
- 融合
数据集的融合是将它重构为这样一种格式:每个测量变量独占一行,行中带有要唯一确定这个测量所需的标识符变量。
举例如下:
> ID<-c(1,1,2,2)
> Time<-c(1,2,1,2)
> X1<-c(5,3,6,2)
> X2<-c(6,5,1,4)
> mydata<-data.frame(ID,Time,X1,X2)
> mydata
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
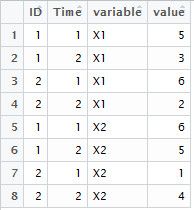
> library(reshape2)
> md<-melt(mydata,id=c("ID","Time")) #融合,每个X1、X2需要各占一行,共计八行
> md
ID Time variable value
1 1 1 X1 5
2 1 2 X1 3
3 2 1 X1 6
4 2 2 X1 2
5 1 1 X2 6
6 1 2 X2 5
7 2 1 X2 1
8 2 2 X2 4
>
- 重铸
dcast() 函数读取已融合的数据,并使用你提供的公式和一个(可选的)用于整合数据的函数将其重塑。调用格式为:
newdata <- dcast(md, formula, fun.aggregate) 其中的 md 为已融合的数据, formula 描述了想要的最后结果,而 fun.aggregate 是(可选的)数据整合函数。
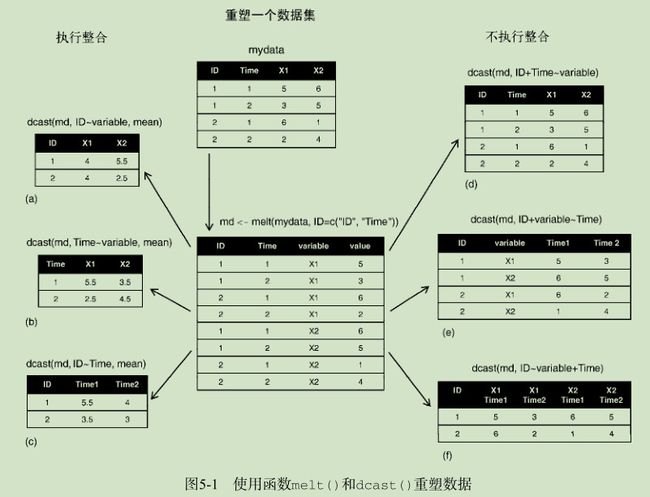
比如:
> my<-dcast(md,ID~variable,mean)# 每个观测所有Time中在X1和X2上的均值
> my
ID X1 X2
1 1 4 5.5
2 2 4 2.5
>
总结一下
本章主要学习了数学和统计函数(数学函数、统计函数、概率函数)、字符处理函数以及其它的使用函数,最后将函数应用于矩阵和数据框,解决了本章前面提出问题。同时学了控制流——循环和条件执行,同时简单介绍了如何进行自编函数,最后学习了折叠、整合以及重铸数据的方法。
以上这些基本具备了进行复杂数据分析的基础,通过一些案列和代码的实践,较好的熟悉了基本工具,但是距离掌握这些工具需要更多的实践练习和深入学习,尤其是相关函数的用法,极为重要。