今天完成了《第二周第二节练习项目:爬取手机号》的作业,写作业的时候,还是出现了很多问题,还好最后都圆满的解决了。
这次作业分为两个步骤:
第一是,获取手机号类目下所有的标题和链接,并储存在数据库中。这一步问题不大,很简单的就完成了。完成的效果图如下:
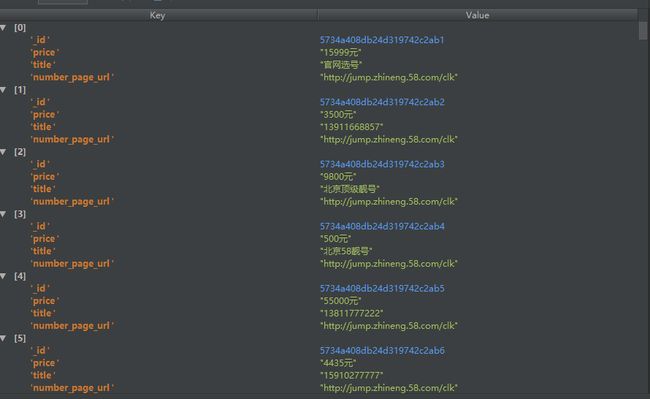
代码如下:
from bs4 import BeautifulSoup
import requests,time,pymongo
#--------------------- 调取数据库,生成数据库列表------------#
client = pymongo.MongoClient('localhost',27017)
telephone_numbers_info = client['Telephone_Numbers']
item_info_urls = telephone_numbers_info['item_info_urls']
item_info = telephone_numbers_info['Item Info']
item_info_urls.remove()
# -------------------- 获取电话号码帖子的标题、价格、链接--------------------#
def get_url(page):
for get_page in range(1,page):
url = 'http://bj.58.com/shoujihao/pn{}/'.format(get_page)
wb_site = requests.get(url)
soup = BeautifulSoup(wb_site.text,'lxml')
# time.sleep(2)
if int(soup.select('#infocont > span > b')[0].text)>0:
for titles,number_page_urls,prices in zip(soup.select('strong.number'),soup.select('div.boxlist a.t'),soup.select('b.price')):
title = titles.text
number_page_url = number_page_urls.get('href').split('?')[0]
price = prices.text
item_info_urls.insert_one({'title':title,'number_page_url':number_page_url,"price":price})
print(get_page)
else:
break
get_url(200000)
值得说的一点是,全部列表页加起来总共才116页,我给的参数是200000,远大于116页,其实116页后就已经没有数据了。最开始的代码,在116页后就会报错。为了避免出现这个问题,我观察到在('#infocont > span > b')的路径,有数据的页会返回 <6*****>的一个6位数的数字,而没有数据的页会返回0。

所以我加了一个条件判断句:
if int(soup.select('#infocont > span > b')[0].text)>0:
for titles,number_page_urls,prices in zip(soup.select('strong.number'),soup.select('div.boxlist a.t'),soup.select('b.price')):
title = titles.text
number_page_url = number_page_urls.get('href').split('?')[0]
price = prices.text
item_info_urls.insert_one({'title':title,'number_page_url':number_page_url,"price":price})
print(get_page)
else:
break
这样就实现了在爬到有数据的列表页时,就执行爬取数据的进程,而没有数据时,就完全停止进程,避免了出现报错的情况。
第二步是获取每个详情页中的具体数据。这一步出现了一些不小的问题,但还好最终还是完成了。
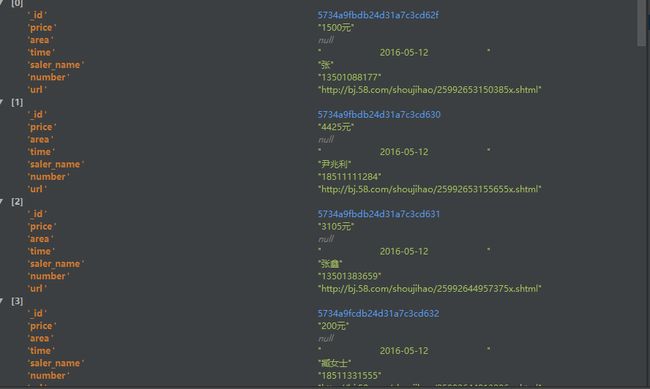
代码如下:
from bs4 import BeautifulSoup
import requests,time,pymongo
client = pymongo.MongoClient('localhost',27017)
telephone_numbers_info = client['Telephone_Numbers']
item_info_urls = telephone_numbers_info['item_info_urls']
item_info = telephone_numbers_info['Item Info']
item_info.remove()
# ------------------获取详情页的信息---------------------------#
for urls in item_info_urls.find():
url = urls[u'number_page_url']
if 'shtml'in str(url):
wb_data = requests.get(url)
info_soup = BeautifulSoup(wb_data.text,'lxml')
saler_name = info_soup.select('ul.vcard a.tx')[0].text if info_soup.find('a','tx') else None
time = info_soup.select('li.time')[0].text
for su_tits in info_soup.select('div.su_tit'):
su_tits_datas = {su_tits.text}
# print(su_tits_datas)
if '区域:' in su_tits_datas:
area = list(info_soup.select('div.su_con ')[1].stripped_strings)
else:
area = None
# print(area)
data={
'number' : urls[u'title'],
'price' : urls[u'price'],
'saler_name' : saler_name,
'time' : time,
'area' : area,
'url' : url
}
print(data)
item_info.insert_one(data)
else:
pass
第一个出现的问题,在获取区域的信息时,定位区域的上一级

折腾了半天,最终发现在

这样就可以通过for循环,建立列表判断“区域”是否在列表中,以判断当前页面是否有“区域”这一项。而且区域的信息,都在第二个
for su_tits in info_soup.select('div.su_tit'):
su_tits_datas = {su_tits.text}
# print(su_tits_datas)
if '区域:' in su_tits_datas:
area = list(info_soup.select('div.su_con ')[1].stripped_strings)
else:
area = None
运行了一次,发现还是报错,观察发现,在列表页中获取的链接中,有两个链接
'http://jump.zhineng.58.com/clk' 和 'http://short.58.com/zd_p/16905f99-7b82-4d7d-bcbf-9e3ff56a97bb'
这两种链接是没有详情页的,而有详情页的都是像“http://bj.58.com/shoujihao/25992653150385x.shtml” 这样有shtml这一串字符串的。
这样,我就又写了一个条件判断句
if 'shtml'in str(url):
这样就实现了只对有“shtml”字符串的网址进行解析,而其他网址直接pass掉的想法。
再次运行,终于不再报错了,并且得到了自己想要的数据并存储在数据库中了。
总结下来,其实实现爬虫的代码并不难,难点在于如何观察网页中的元素,以便获得自己想要的数据。要多尝试几个定位的方法,最终会得到满意的结果的。