对于集合的可视化,第一时间想到的都是韦恩图(venn diagram),一般集合不超过5个的时候,可视化效果还是不错的

但是一旦数据集增加,比如说五个的时候,你就很难从图中解读出想要的信息了。
即便你把它画的很美观,如下图那样,还是还是很难直观找到自己需要的信息。可视化的目的不是炫技,而是快速理解数据。
还好R语言里新增了一个集合可视化神包--UpSetR。它可视化的结果的基础版本长下面这个样子:
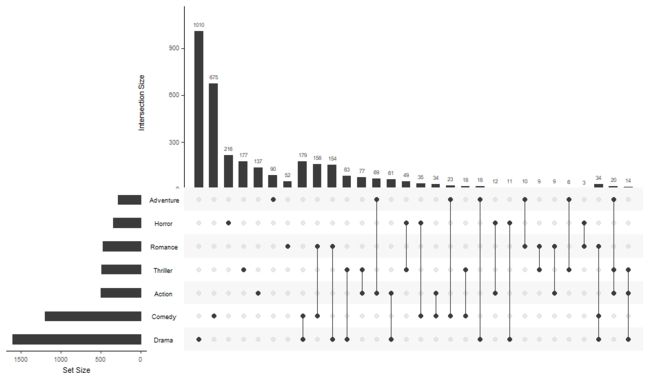
上述是分析了不同电影的所属类型得到的结果。在我不告诉你任何图示信息的情况下,请思考下那种电影类型拍的最多,然后哪两种电影电影类型拍的最少。
基本上我不用过多和你解释图示,你也能很快的找到答案。图中黑色表示该位置有数据,灰色的点表示没有。不同点连线表示存在交集。具体数据可以看上面的条形图。不同类型的数据的总量看左边的条形图。
如何画图
UpSetR是一个R包,这意味着你可以简单通过一行命令就能安装
install.packages(UpSetR)
UpsetR接受三种类型的数据输入:
- 表格形式,在R语言里就是数据框了。行表示元素,列表示数据集分配和额外信息。
- 元素名的集合(没见过,不知道。。)
fromList - venneuler包引入的用于描述集合交集的向量
fromExpression。
光看文字肯定是不懂的,所以直接实战把
输入方式一: table
我们用UpSetR提供的测试数据作为演示
require(ggplot2); require(plyr); require(gridExtra); require(grid);
movies <- read.csv(system.file("extdata","movies.csv",package = "UpSetR"), header = TRUE, sep=";")
看下数据长什么样子
View(movies)

Name是不同的电影,然后不同发布时间,后面接着电影跟随的类型。
绘图用的upset函数:
upset(movies, nsets = 7, nintersects = 30, mb.ratio = c(0.5, 0.5),
order.by = c("freq", "degree"), decreasing = c(TRUE,FALSE))
稍微解释一下参数
nsets: 最多展示多少个集合数据。毕竟原来有20多种电影类型,放不完的
nintersects: 展示多少交集。
mb.ratio: 点点图和条形图的比例。
order.by: 交集如何排序。这里先根据freq,然后根据degree
decreasing: 变量如何排序。这里表示freq降序,degree升序
更有意思的是,我们还能在图中描述出1970-1980年恐怖片和剧情片的情况
# 用于query的函数
between <- function(row, min, max){
newData <- (row["ReleaseDate"] < max) & (row["ReleaseDate"] > min)
}
upset(movies, sets=c("Drama","Comedy","Action","Thriller","Western","Documentary"),
queries = list(list(query = intersects, params = list("Drama", "Thriller")),
list(query = between, params=list(1970,1980), color="red", active=TRUE)))
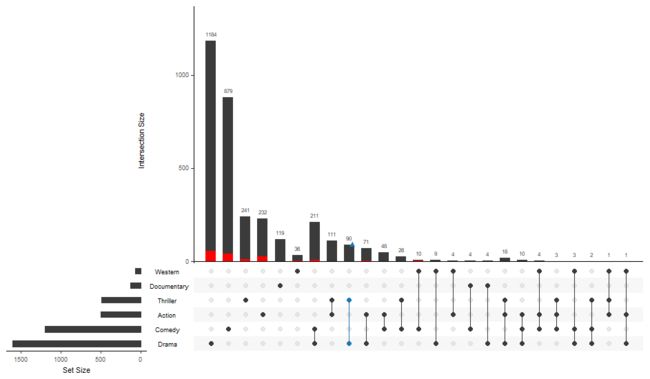
这里必须介绍一个神奇的参数queries:
queries接受query所组成的list。然后不同query也是一个list,这个list由查询函数,和参数组成,参数也是一个list。查询函数可以用系统自带的,也可以自己写一个。比如说这里的between
此外还有一个参数叫做attribute.plots能够添加在upset的结果图中加入属性图。
upset(movies,attribute.plots=list(gridrows=60,plots=list(list(plot=scatter_plot, x="ReleaseDate", y="AvgRating"),
list(plot=scatter_plot, x="ReleaseDate", y="Watches"),list(plot=scatter_plot, x="Watches", y="AvgRating"),
list(plot=histogram, x="ReleaseDate")), ncols = 2))
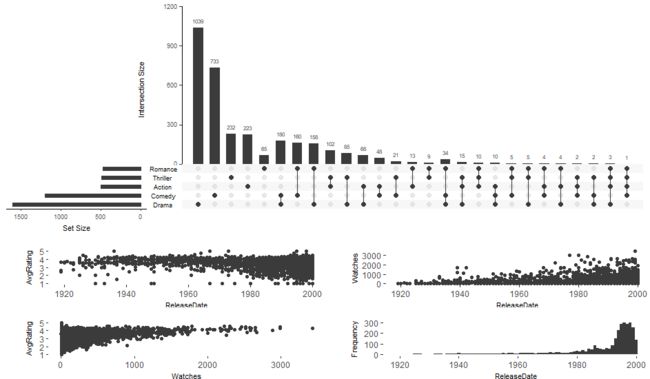
这个attribute.plots接受各个plot函数组成的作图函数,可以用自带的,也可以自己写,只要保证里面的参数设置正确了。
其他参数就不继续演示了,因为我懒。
输入方式二:集合交集向量
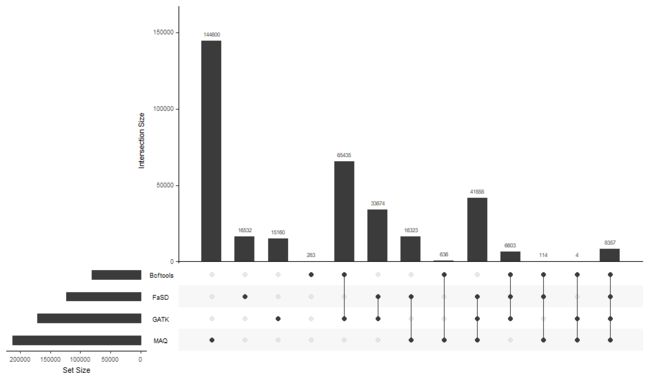
集合交集向量长下面这个样子
input <- c(
"MAQ"=144600,
"FaSD"=16532,
"Bcftools"=283,
"GATK"=15160,
"MAQ&FaSD"=16323,
"MAQ&Bcftools"=636,
"Bcftools&GATK"=65435,
"FaSD&GATK"=33874,
"MAQ&FaSD&Bcftools"=114,
"MAQ&FaSD&GATK"=41858,
"MAQ&Bcftools&GATK"=4,
"FaSD&Bcftools&GATK"=6603,
"MAQ&FaSD&Bcftools&GATK"=8357
)
输入格式一目了然,然后数据可以用fromExpression进行转换
data <- fromExperssion(input)
转换后的数据就可以拿去用upset作图了
upset(data)
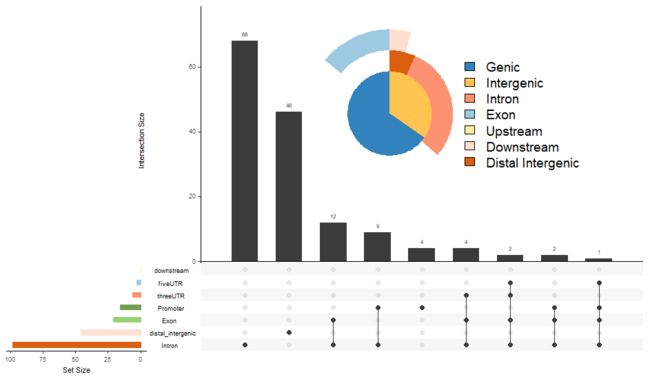
福利:Y叔的upsetplot()
我们可以对ChIP-Seq分析得到的peak进行注释
require(TxDb.Hsapiens.UCSC.hg19.knownGene)
txdb <- TxDb.Hsapiens.UCSC.hg19.knownGene
peakfile <- system.file("extdata", "sample_peaks.txt", package="ChIPseeker")
peakAnno <- annotatePeak(peakfile, tssRegion=c(-3000, 3000), TxDb=txdb)
peakAnno
然后就可以用upsetplot画画了,太简单了。
upsetplot(peakAnno, vennpie=TRUE)
下一期写一篇Y叔的upsetplot是如何写的。