一 计算
上一篇提到HFRS是个好东西。但是其专业性太高,如果没有一些纠删码的基础知识和相关论文的阅览(关于扇区错误模型,韦伯分布,蒙特卡洛方法,磁盘故障率,磁盘修复,分布式存储等)想要使用它是非常困难的。甚至,都看不懂其结果的含义。
还有一些部分需要删减,比如作者给出的其他方法的计算模型,为了避免混淆应该删去。还有多种erasure codes的可靠性计算。如XOR-based array codes和LDPC,这两块由于之前的讨论我们已经知道,我们不会实际使用他们,而且关于他们的计算要引入许多新的编码内容和数学内容,我于是也就掩盖了。
另外,还需要我们调整代码中的一些数据和判定跳转结果。
而且,作者本人也说了,不保证没有bug。需要修改一些错误。
那么,我在这里做的工作就是修复一些小问题,然后封装HFRS,把需要微调的部分都用通用的,较为合适的参数写到代码中,把最直观的结果呈现出来。另外,强调使用中的注意事项,使其更加友好。
模型默认的是4T的盘,每个扇区大小为4096bytes(性价比突出,可靠性也不错,这里就不说什么牌子了)。AFR(Annualized failure rate)为3.1%附近,从而可以MTBF(Mean time before failure),我这里取281257
unrecoverable read error rate (URE) 取值 10^14(1e10),即每10^14 bits发生一次错误。根据4K扇区大小,可计算得每读3051757812.5个扇区出现一次错误,概率为3.2768e-10
(感兴趣的可以自行计算一下,在raid5中坏掉一块盘时,修复工作中可能出现read error的概率)
其他的分布模型以及加速模拟的原理和参数设定我就不一一介绍了,再说下去就要直接学习HFRS了 :D
计算将只需要五个或0个参数,默认是RS(10,4)的模型。
-C --code_file (保存在codes中) 默认是rs_10_4
code_file的形式:

这里可以理解为RS(13,3) 倘若是RS(10,4) 则type保持不变,k变为10,m变为4,hd变为5,min disk failures变为5
-n --num_disk 默认是14
例如RS(13,3)就是16,RS(10,4)就是10+4=14
或许有人会问了,我的集群里有几万块盘。我在这里只计算10几块,不会出事情吗?
-i --num_iterations 模拟跑多少次 默认是10000
越多越精确,也越来越慢. 最好控制在生产环境下的纠删码集群(至少超过3-disk fault_tolerant,要比三副本强。但一般不超过6-disk fault_tolerant,要节约空间)可以节约宝贵时间
需要注意的是需要非常非常久的时间计算,期间你的电脑将会持续高烧,耗电猛增,请HOLD住
-m --mission_time 模拟时间 默认是35040(4年) 强烈建议是3-5年(26280-43800)
-k --num_data_symbols 默认是10.就是上面code文件中data分成了k块分别存储于k块盘中。比如对于rs_10_4来说k就是10
好了就这么几个参数。是不是非常的简单。
计算的结果也很好识别:
Average bytes lost per usable TB
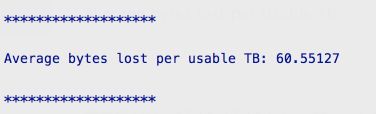
意为每TB有效存储(存储data,非parity)会丢失多少bytes
从上面的结果,可以看出RS(10,4)每TB存储(data)在4年里会丢掉60bytes. 也就是说100PB的data(在4年里)会丢掉5MB左右,占比1/21474836480(200亿)。据说一个鸡蛋里面4个蛋黄的概率是110亿分之一。
我们可以发现data lost的比重和扇区read error的比例是在一个数量级之上的。保护好扇区成了不丢数据的关键。
另外,我需要特别说明的是,模型为了可计算性,做了一些加速处理,一个是引入了错误发生机制,另一个是简化了扇区故障模型。实际上,如果用传统的模拟方法(不做加速),RS(10,4)算下去的结果会是0.00
这也反应了被我剔除的模拟方法的局限性,即结果没有意义。虽然现在的模型存在低估可靠性的可能性(实际上并不一定,丢数据不可避免),但是还是在合理范围内的。
PS:
1. 代码链接 https://github.com/templexxx/abl/
2. 不知道大家还记得我在前文提到的LRC不?LRC的磁盘故障容忍数值有些好玩,它有一定的概率?(至于为什么,我就不多说了)。那么利用abl我们可以分别计算不同min disk failure.然后LRC的可靠性就在这两个值之间了
二 总结
因为物理介质的局限性,我们几乎不可能在一个可以普遍承受的成本下搭建永不丢失的存储集群。太阳底下没有新鲜事,云计算也没有黑魔法。丢一点数据很正常,这个数据量可能比我算出来的高,也可能低,因为中间能够产生影响的因素实在太多了。
丢一点点数据没必要觉得可怕,恐龙还灭绝了呢,太阳还有生命周期呢。况且也没人站出来承诺100%不丢数据,只不过没人出来说清楚为什么会丢,怎么样丢的少一点。
一串9的可靠性表达并不是说不能对比不同冗余方案的可靠性,只是这个数据很难让人理解其意义。或者说根本就没有意义,我们能说的只是概率真小。而且不同公司使用的算法和参数也不尽相同,因此跨公司的比较有多少个9也是没有意义的。
现在我们看到的计算模型(Average bytes lost per usable TB)其实只是个关于概率问题的直观表达。它便于比较,结论也比较有意义。但是,这依然只是个模拟的结果,真实会丢多少数据,影响因素实在太多。也就是说在诸多问题上是模糊的,经验性的。
另外,通过计算我们可以发现一个有意思的问题,即大多数厂商一直考虑和强调的磁盘修复问题并不能得到体现(即由于磁盘故障太多,修复不及时导致的data lost)。在模型中,我指定的修复时间是比较长的(小于等于SATA盘的外部传输速率),数据丢失基本上是扇区故障导致的,也就是说修复时间如此长对可靠性并没有带来伤害,极力去缩短修复时间对可靠性带来的帮助也没有想象中那么大。虽然这并不是特别强有力的证据,但我们依然可以得到一个大致的方向,正如前一篇文章对于并行修复的讨论,我认为其并没有太多实际效用。
这一点正是搭建存储集群的一个特点之一,即经验性。尽管我们可以从数据上找到支撑,去促使我们做出选择(比如为何流行的是三副本不是四副本?三副本够了吗?)造成这种经验性选择的还有一个关键原因是数据不充分和样本差异比较大。比如,磁盘故障和扇区故障率的数据我们很难找到一个有效的基准,而且不同厂商不同产品差异非常大。倘若真的选择了故障率特别高的磁盘,那么一些原本优秀的方案就成了豆腐渣工程,只能靠雇佣一名法师来维持可靠性了。
同时我们的选择也是社会性的。比如LDPC和喷泉码有法律上的限制,我们同时也很难找到足够的资料去窥探他人的实践成果和经验。
又回到经验上来。这个行业总是会有先驱者去开拓出一个新的方式,如果他倒下了,人们会吸取他的教训,如果他走得很好,人们会从他身上获得营养。这是个勇敢者和奉献者的游戏。
好了,说了一些“伟大”的话。我得指出存储这块还是特别保守的,尤其对于大型存储系统来说。SATA为主的情况,至少多年内是不会改变的。另外三副本,纠删码的互相配合的方案也会长期保持主流地位。
三 拓展
这里放一些比较好的相关文章和论文,供感兴趣的朋友进一步探究,当然另外还有很多漂亮的论文和文章大家可以自己再找找:
1. backblaze的blog,每个季度其均会发布磁盘故障率统计。并且有完整的磁盘状态数据库可供下载。另外其Reed solomon的源代码也公开在github上
2. 关于erasure codes比较全面的介绍可以看Plank的Erasure Codes for Storage Applications
3. HFRS(High-Fidelity Reliability Simulator)的信息可以关注Greenan的个人网站。上面有他发表的论文的列表以及源代码
4. 关于副本和可靠性的讨论。可以参看Efficient Replica Maintenance for Distributed Storage Systems这篇论文
5. 磁盘生命周期的分析可以看google的论文。有很多有意思的数据,比如温度,工作负载对磁盘生命周期的影响。他们的数据来源于很大的磁盘规模,观测周期也很长。论文的题目是:Failure Trends in a Large Disk Drive Population
6. non-MDS存储集群的可靠性分析有IBM的Notes on Reliability Models for Non-MDS Erasure Codes可供观赏。
7. CMU的Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you? 是一篇值得看看的论文。我记得还是篇获奖论文。其中关于在同一组中的磁盘故障间隔非常有意思,如果上一块磁盘故障的时间越久远,下一块磁盘的故障的到来也的时间也变得更长了。是不是很反直觉?另外,关于分布模型的讨论也很详细。
8. 关于RAID5 RAID6的讨论可以参阅Robin Harris的 Why RAID 6 stop working in 2019以及Why RAID 5 stop working in 2009
9. 扇区故障的讨论不得不提多伦多大学的Understanding latent sector errors and how to protect against them
10. 关于4KB的扇区大小问题,建议看一下希捷的官方文档。可以搞清楚这个变化的来龙去脉
11. http://www.networkcomputing.com/storage/gluster-vs-ceph-open-source-storage-goes-head-to-head/a/d-id/1113581 这是一篇评论比内容精彩的文章。文章本身我觉得没有什么说服力,内容本身我压根没当回事