题目:
将下面xml格式文件,按树状结构进行输出,格式如书本目录,条件是不能用第三方库,比如什么dom,sax,pull解析方式,一句话,把里面的节点自己慢点抠出来吧。
(纯属自娱自乐,有问题的地方或者有更好的想法,欢迎交流,谢谢,qq:413686520)
XY1
22
XY2
22
100
28
对于这个题目,最开始我对出题人的要求搞错了,以为只要节点名字,节点深度,最后输出成目录结构就行。所以,我就悲剧了,我最开始是用in.read()一个一个读到内存中,按字符来解析的,可以想象一下最后是多么艰难的写出来的,花了4个小时,可能时间更长,早上没有吃饭,写完的时候,已经饿的肚子疼了。一个字符一个字符的解析,竟然让我搞出来了。最开始的想法决定了算法最终的难度。下面给出这两天重新写过后的结果:

其中,我们拿grade节点说明一下,它的节点深度为3,它有孩子节点mat,h,english,music,其他的节点可能还存在key:value键值对等等(直接看图吧)。
思路:
首先,一次读取一行,并且从读取的内容中找到第一个右括号‘>’,这样我们最后需要处理的内容都会变为如下几种形式:
(1).***<******>
(2).***<******/>
(3).***
注意:先规定下本文节点的格式
例如

对于上面的三种状态,对于‘<’左边的只可能是节点的text文本值,然后对于“<>”,里面只可能是节点名字,键值对,节点结束标志。
首先构建我们的节点,如下所示:
package com.lifestudy.stdy.lifestudy.readxml;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Created by lj on 2017/6/16.
*/
public class LjXMLNode {
int id;//唯一标识
String name;//节点的名字
List children = new ArrayList();//当前节点的孩子节点
int parent = -1;//默认父节点,用id表示
Map mapKeyValue = new HashMap();//当前节点的key:value
String text="";//当前节点的文本值
int level;//当前节点的深度
}
然后,开始开始遍历我们的xml文件:
public void readXMLFile(InputStream inputStream){
try {
InputStreamReader inputStreamReader = new InputStreamReader(putStream);
BufferedReader in = new BufferedReader(inputStreamReader);
System.out.println("开始输入:");
StringBuffer sb = new StringBuffer();
String s;
String rest = "";
while( ( s = in.readLine() ) != null ){
s = s.trim();
s = rest + s;
int start = 0;
for( int i = 0; i < s.length(); i++ ){
if( s.charAt(i) == '>'){
process(s.substring(start,i+1));
start = i + 1;
}
}
if( start >= s.length() ){//說明處理到最後一個字符了
//do nothing
}else{
rest = s.substring(start,s.length());
}
}
// System.out.println( sb.toString() );
} catch (Exception e) {
e.printStackTrace();
}
}
然后,在process()方法中处理最开始的三种情况:
说明:对于'<'左边的字符都是节点的text值,对于‘<’右边的第一个单词肯定是节点的name,当我们读取完name时,我们创建一个LjXMLNode节点node,赋值node.name,最后,入栈的并将其父节点node.parent指向栈顶元素,同时让栈顶元素的孩子节点加1。然后是读取节点的key:value(这个可以根据是否有等号来判断),并且更新node的值。最后当前节点只可能以右括号'>'或者'/>'两种形式结尾,当我们读取到“/”时,将当前节点出栈(同时,如果想对节点做操作,也是在出栈时,因为出栈的节点元素是完整的,它肯定是遍历完成了,本文是将出栈的元素保存到一个map中了,其中key是id,value是LjXMLNode)。
/**
* 處理
* 主要是對stack的操作
*/
private void process(String s){
String nodeName = "";
String text = "";
for( int i = 0; i < s.length();i++ ){
if( s.charAt(i) == '<'){
text = s.substring(0,i);
if( mStack.size() > 0){
LjXMLNode topNode = mStack.peek();
topNode.text = text;
}
if( s.charAt(i+1) != '/'){
nodeName = findNodeName(s.substring(i+1));
//push
LjXMLNode node = new LjXMLNode();
node.id = ID_0++;
node.name = nodeName;
if( mStack.size() > 0){
LjXMLNode parentNode = mStack.peek();
node.parent = parentNode.id;
parentNode.children.add(node.id);
}
mStack.push(node);
for( int j = i+1; j < s.length();j++ ){
if( s.charAt(j) == '='){//key:value
String key = findFirstLeftWord(s,j);
String value = findFirstRightWord(s,j);
if( key != ""){
LjXMLNode curNode = mStack.peek();
curNode.mapKeyValue.put(key,value);
}
}
}
for( int j = i+2; j < s.length();j++ ){
if( s.charAt(j) == '/'){
LjXMLNode shuchuNode = mStack.pop();
shuchuNode.level = mStack.size() + 1;
mFinalNodes.put(shuchuNode.id,shuchuNode);
System.out.println("shuchuNode:" + "id:"+shuchuNode.id + " name:"+shuchuNode.name
+ " key_count:"+shuchuNode.mapKeyValue.size()
+ " text:" + shuchuNode.text
+" parent:"+ shuchuNode.parent);
}
}
}else {
//pop
LjXMLNode shuchuNode = mStack.pop();
shuchuNode.level = mStack.size() + 1;
mFinalNodes.put(shuchuNode.id,shuchuNode);
System.out.println("shuchuNode:" + "id:"+shuchuNode.id + " name:"+shuchuNode.name
+ " key_count:"+shuchuNode.mapKeyValue.size()
+ " text:" + shuchuNode.text
+" parent:"+ shuchuNode.parent);
}
break;
}
}
}
最后是对节点的遍历,因为处理后的节点,最后会存储为成森林的树状结构,如下所示:
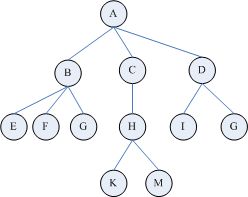
所以,这块采用树的深度优先遍历算法。思想很简单,构建一个栈结构,首先将根节点入栈,也就是图中的A节点,然后开始遍历,先将根节点A出栈,同时访问根节点A,并且将其孩子节点入栈(注意此时的入栈顺序是从最右边的孩子开始往左遍历,也就是说越在左边的孩子应该越早访问到)。后面仿照根节点A出栈的同时访问,并且将其孩子节点入栈,代码如下所示:
public void depthLjFirst(){
Stack depthStack = new Stack();
LjXMLNode head = mFinalNodes.get(0);
depthStack.push(head);
while ( depthStack.size()> 0 ){
LjXMLNode cur = depthStack.pop();
visit(cur);
for( int i = cur.children.size(); i > 0;i-- ){
int childId = cur.children.get(i-1);
depthStack.push( mFinalNodes.get(childId) );
}
}
}
最后完整的代码如下所示:
package com.lifestudy.stdy.lifestudy.readxml;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.Stack;
/**
* Created by lj on 2017/6/16.
*/
public class LjXMLParser {
private Stack mStack = new Stack();
Map mFinalNodes = new HashMap();
private int ID_0 = 0;
public void readXMLFile(InputStream in1){
try {
InputStreamReader inputStreamReader = new InputStreamReader(in1);
BufferedReader in = new BufferedReader(inputStreamReader);
System.out.println("开始输入:");
StringBuffer sb = new StringBuffer();
String s;
String rest = "";
while( ( s = in.readLine() ) != null ){
s = s.trim();
s = rest + s;
int start = 0;
for( int i = 0; i < s.length(); i++ ){
if( s.charAt(i) == '>'){
process(s.substring(start,i+1));
start = i + 1;
}
}
if( start >= s.length() ){//說明處理到最後一個字符了
//do nothing
}else{
rest = s.substring(start,s.length());
}
}
// System.out.println( sb.toString() );
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 處理
* 主要是對stack的操作
*/
private void process(String s){
String nodeName = "";
String text = "";
for( int i = 0; i < s.length();i++ ){
if( s.charAt(i) == '<'){
text = s.substring(0,i);
if( mStack.size() > 0){
LjXMLNode topNode = mStack.peek();
topNode.text = text;
}
if( s.charAt(i+1) != '/'){
nodeName = findNodeName(s.substring(i+1));
//push
LjXMLNode node = new LjXMLNode();
node.id = ID_0++;
node.name = nodeName;
if( mStack.size() > 0){
LjXMLNode parentNode = mStack.peek();
node.parent = parentNode.id;
parentNode.children.add(node.id);
}
mStack.push(node);
for( int j = i+1; j < s.length();j++ ){
if( s.charAt(j) == '='){//key:value
String key = findFirstLeftWord(s,j);
String value = findFirstRightWord(s,j);
if( key != ""){
LjXMLNode curNode = mStack.peek();
curNode.mapKeyValue.put(key,value);
}
}
}
for( int j = i+2; j < s.length();j++ ){
if( s.charAt(j) == '/'){
LjXMLNode shuchuNode = mStack.pop();
shuchuNode.level = mStack.size() + 1;
mFinalNodes.put(shuchuNode.id,shuchuNode);
System.out.println("shuchuNode:" + "id:"+shuchuNode.id + " name:"+shuchuNode.name
+ " key_count:"+shuchuNode.mapKeyValue.size()
+ " text:" + shuchuNode.text
+" parent:"+ shuchuNode.parent);
}
}
}else {
//pop
LjXMLNode shuchuNode = mStack.pop();
shuchuNode.level = mStack.size() + 1;
mFinalNodes.put(shuchuNode.id,shuchuNode);
System.out.println("shuchuNode:" + "id:"+shuchuNode.id + " name:"+shuchuNode.name
+ " key_count:"+shuchuNode.mapKeyValue.size()
+ " text:" + shuchuNode.text
+" parent:"+ shuchuNode.parent);
}
break;
}
}
}
/**
* 找到右邊的第一個單詞,只能以空格或者是右括號“>”結尾
*/
private String findNodeName(String s){
int start,end;
end = -1;
start = -1;
for( int i = 0; i < s.length(); i++){
if( s.charAt(i) != ' '){ //找到左边的第一个字母
start = i;
// System.out.println("nodeName_start:" + start);
break;
}
}
if( start < s.length() && start >= 0){
for( int i = start + 1; i < s.length(); i++ ){
if( s.charAt(i) == ' ' || s.charAt(i) == '>'){
end = i;
break;
}
}
}
if( start <= end && start != -1){
return s.substring(start,end);
}
return "";
}
/**
* 找到下标为loc左边第一个单词
*/
private String findFirstLeftWord(String s,int loc){
// System.out.println("开始解析:" + s + "###loc:" + loc);
String key= "";
int start,end;
end = -1;
start = -1;
for( int i = loc-1; i > 0; i--){
if( s.charAt(i) != ' '){ //找到左边的第一个字母
end = i;
// System.out.println("end:" + end);
break;
}
}
// System.out.println("end解析完成");
if( end < loc && end > 0){
for( int i = end; i > 0; i--){
if( s.charAt(i) == ' '){ //找到左边的第一个空格
start = i+1;
// System.out.println("start:" + start);
break;
}
}
}
if( start <= end && start != -1){
return s.substring(start,end+1);
}
return "";
}
/**
* 找到loc右边第一个双引号包括的单词
*/
private String findFirstRightWord(String s,int loc){
// System.out.println("s:" + s);
String value= "";
int start,end;
end = -1;
start = -1;
for( int i = loc + 1; i < s.length(); i++){
if( s.charAt(i) == '"'){ //找到右边的第一个双引号
start = i;
// System.out.println("start:" + start);
break;
}
}
if( start > loc && start < s.length()){
for( int i = start+1; i < s.length(); i++){
if( s.charAt(i) == '"'){ //找到右边的第一个双引号
end = i+1;
// System.out.println("end:" + end);
break;
}
}
}
if( start <= end && start != -1){
return s.substring(start,end);
}
return "";
}
public void depthLjFirst(){
Stack depthStack = new Stack();
LjXMLNode head = mFinalNodes.get(0);
depthStack.push(head);
while ( depthStack.size()> 0 ){
LjXMLNode cur = depthStack.pop();
visit(cur);
for( int i = cur.children.size(); i > 0;i-- ){
int childId = cur.children.get(i-1);
depthStack.push( mFinalNodes.get(childId) );
}
}
}
private void visit(LjXMLNode node){
StringBuffer sb = new StringBuffer();
for( int i = 0; i < node.level; i++){
sb.append(" ");//三个空格
}
sb.append("" + node.level);
sb.append(" "+ node.name);
Set> set2=node.mapKeyValue.entrySet();
for (Iterator> iterator = set2.iterator(); iterator.hasNext();) {
Map.Entry entry = (Map.Entry) iterator.next();
String key=entry.getKey();
String valueString=entry.getValue();
sb.append(" "+ key + "=" + valueString );
}
// TODO: 2017/6/16 此处用“!=”来判断text是否为空会出错 (why?)
if( node.text != null&& !node.text.equals("") ){
sb.append(" text:" + node.text);
}
System.out.println( sb.toString());
}
}