欢迎大家关注我的专题:爬虫修炼之道
上篇 爬虫修炼之道——编写一个爬取单页面的网络爬虫主要讲解了如何使用python编写一个下载单页面的爬虫,如何下载失败后重试,如何设置用户代理。本篇将编写一个可以爬取多页面的爬虫(以下载 糗事百科 多个网页为例)。涉及到的模块有:
- re - python中和正则表达式相关的库
- urlparse 此模块定义了一个标准接口,用于组合URL字符串,并将“相对URL”转换为给定“基本URL”的绝对URL。
- urllib2 - 此模块对urllib模块进行了增加,增加了将url封装为Request的打开方式。
下载多页面
想要下载多个页面,我们需要找到多个URL,常用的有以下三种方式:
- 使用 sitemap
- 使用 id 遍历
- 跟进链接(follow)
使用sitemap
一个网站的导航导航可以从该网站的 sitemap 中得到,也就是说,从sitemap可以得到该网站的链接入口。sitemap所对应的URL一般可以在robots.txt中找到,但是使用sitemap有以下几个问题:
- 使用sitemap适合爬取该网站全量的网页
- sitemap更新不及时,导致包含的信息不全面
- 很多网站在robots.txt中没有保存sitemap所对应的URL
在 糗事百科 的 robots.txt 文件中并没有发现sitemap。所以这儿没法使用。
使用 id 遍历
以 糗事百科 为例,我们发现每条糗事的URL格式都是 http://www.qiushibaike.com/article/ 前缀加上一个数字id,这样我们就能得到,这样我们就可以假定一个开始的id,然后拼接URL前缀,把拼接后的结果当成最终的URL,但是也有以下几个问题:
- 如何确定id的初始值
- id可能不连续
- 有些网站URL中没有明确的数字id(如)
我们假定起始id为1,也就是说完整URL为 http://www.qiushibaike.com/article/1 ,但是打开后得到一个404错误,说明我们URL有问题。所以这儿也不能用该方法。
但是在这儿如果我们不想下载每篇糗事的详情页,而是下载 文本板块 的每一页,这个规律就可以用的到,我们发现第一页对应的URL为 http://www.qiushibaike.com/text/page/1 就可以用,第二页对应的URL为 http://www.qiushibaike.com/text/page/2 。一共35页,最后一页对应的URL为 http://www.qiushibaike.com/text/page/35 。这样我们就能够构造出来一个要下载的多个页面的URL列表。
def structure_links(base_url, page_num):
# 构建一个内容为base_url、长度为page_num的urls列表
base_urls = [base_url] * page_num
# 构建一个[base_url + 1, base_url + 2, ..., base_url + page_num]的url列表
urls = [base_url + unicode(index + 1) for index, base_url in enumerate(base_urls)]
return urls
跟进链接(follow)
虽然使用遍历id的方法可以生成一个URL列表,但是有的网站的URL中可能没有数字id。这时候就需要在当前页面找到下一个页面的链接。
使用chrome打开网页后,在第一条糗事的文字上点击右键,然后找到“检查”选项,左键:

点击之后得到如下的界面:
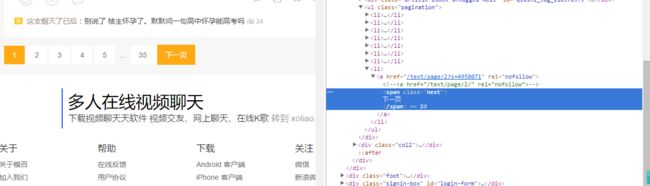
我们发现下一页的链接在一个 标签里,我们可以使用正则表达式来匹配出来。
import re
def download(url, user_agent='crawl', num_retries=2, timeout=3):
"""
下载一个URL页面
:param url: 要下载的url页面
:param user_agent: 用户代理
:param num_retries: 碰到5xx状态码时尝试重新下载的次数
:param timeout: 超时时间,单位为s
:return:
"""
print 'Downloading: url %s' % url
headers = {'User-Agent': user_agent}
request = urllib2.Request(url, headers=headers)
try:
html = urllib2.urlopen(request, timeout=timeout).read()
except urllib2.HTTPError, e:
print 'URL: %s,HTTP Error %s: %s' % (url, e.code, e.msg)
html = None
if num_retries > 0 and 500 <= e.code < 600:
return download(url, num_retries = num_retries - 1)
except urllib2.URLError, e:
print 'URL: %s, urlopen Error %s' % (url, e.reason)
html = None
return html
link_regex = re.compile('.*', re.S)
html = download('http://www.qiushibaike.com/text/')
link = get_links(html, link_regex)
print "link: %s" % link
运行结果:

注意:
- download使用的是上一篇中的 download 方法。
- 正则表达式中
.*?是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到.*?的搭配。 -
(.*?)代表一个分组,在这个正则表达式中我们匹配了一个分组,所以使用 [0] 来提取出来。 -
re.S标志代表在匹配时为点任意匹配模式,点.也可以代表换行符。 - 我们得到的URL只是相对URL,下载页面时需要使用绝对URL,否则会出错,下面进行详细描述。
现在我们来尝试跟进链接来下载多个页面:
def link_crawler(seed_url, link_regex):
"""
爬取一个页面
:param seed_url: 种子URL
:param link_regex: 从种子URL页面中提取跟进链接所用的正则表达式
:return:
"""
crawl_queue = [seed_url] # 需要下载的URL列表
while crawl_queue:
url = crawl_queue.pop() # 将种子URL弹出
html = download(url) # 下载当前URL页面
links = get_links(html, link_regex) # 得到当前URL页面的跟进链接
print "links: %s" % links
for link in links:
crawl_queue.append(link)
link_regex = re.compile('.*', re.S)
link_crawler('http://www.qiushibaike.com/text/', link_regex)
运行后我们会发现程序出错了。
Downloading: url http://www.qiushibaike.com/text/
links: ['/text/page/2/']
Downloading: url /text/page/2/
Traceback (most recent call last):
File "D:/work/spider_ex/chapter01/1.3.py", line 101, in
link_crawler('http://www.qiushibaike.com/text/', link_regex)
File "D:/work/spider_ex/chapter01/1.3.py", line 44, in link_crawler
html = download(url) # 下载当前URL页面
File "D:/work/spider_ex/chapter01/1.3.py", line 71, in download
html = opener.open(request, timeout=timeout).read()
File "D:\software_work\Anaconda2\Lib\urllib2.py", line 421, in open
protocol = req.get_type()
File "D:\software_work\Anaconda2\Lib\urllib2.py", line 283, in get_type
raise ValueError, "unknown url type: %s" % self.__original
ValueError: unknown url type: /text/page/2/
出错原因:无法识别 /text/page/2 这种URL类型,这是因为我们使用的是相对URL,需要转为绝对URL。
将相对URL转为绝对URL
为了解决这个问题,urlparse 该上场了。使用urlparse.urljoin方法来解决。完善后的 link_crawler 如下:
def link_crawler(seed_url, link_regex):
"""
爬取一个页面
:param seed_url: 种子URL
:param link_regex: 从种子URL页面中提取跟进链接所用的正则表达式
:return:
"""
crawl_queue = [seed_url] # 需要下载的URL列表
while crawl_queue:
url = crawl_queue.pop() # 将种子URL弹出
html = download(url) # 下载当前URL页面
links = get_links(html, link_regex) # 得到当前URL页面的跟进链接
print "links: %s" % links
for link in links:
link = urlparse.urljoin(seed_url, link)
crawl_queue.append(link)
link_regex = re.compile(u'.*?', re.S)
link_crawler('http://www.qiushibaike.com/text/', link_regex)
再次运行:
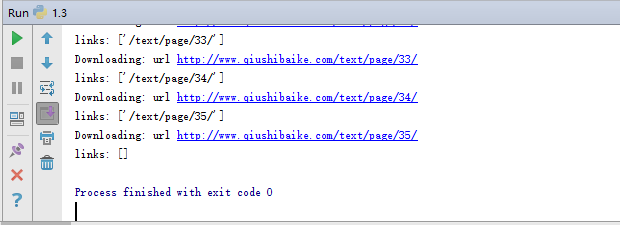
成功运行。
下载限速
有时我们频繁下载一个网站会被封禁,所以需要进行限速。创建一个限速器:
class Throttle:
"""每次请求相同的域时,会暂停指定的时间
"""
def __init__(self, delay):
# amount of delay between downloads for each domain
self.delay = delay
# timestamp of when a domain was last accessed
self.domains = {}
def wait(self, url):
# 由于我们只爬取糗事百科的内容,所以在这儿,domain一直为 www.qiushibaike.com
domain = urlparse.urlparse(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.now() - last_accessed).seconds
if sleep_secs > 0:
print "sleep %s s" % sleep_secs
time.sleep(sleep_secs)
self.domains[domain] = datetime.now()
使用方法:
throttle = Throttle(delay)
throttle.wait(url)
download(url)
支持代理
有时我们需要使用代理访问某个网站。使用urllib2支持代理代码如下:
proxy = ...
opener = urllib2.build_opener()
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
response = opener.open(request, timeout=timeout)
这样,我们可以将 download 进行改进,如下:
def download(url, headers=None, proxy=None, num_retries=2, timeout=3):
"""
下载一个URL页面
:param url: 要下载的url页面
:param headers: headers
:param proxy:代理
:param num_retries: 碰到5xx状态码时尝试重新下载的次数
:param timeout: 超时时间,单位为s
:return:
"""
print 'Downloading url: %s' % url
request = urllib2.Request(url, headers=headers)
opener = urllib2.build_opener()
if proxy:
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
response = opener.open(request, timeout=timeout)
html = response.read()
except urllib2.HTTPError, e:
print 'URL: %s,HTTP Error %s: %s' % (url, e.code, e.msg)
html = None
if num_retries > 0 and 500 <= e.code < 600:
return download(url, num_retries = num_retries - 1)
except urllib2.URLError, e:
print 'URL: %s, urlopen Error %s' % (url, e.reason)
html = None
return html
运行测试
完整代码见:https://github.com/Oner-wv/spider_note/blob/master/chapter01/1.3.py
我们运行程序后得到如下结果:

到目前为止我们已经能够下载多个页面了,但是得到的只是单纯的HTML代码,这在实际中并没有什么卵用,我们需要的是能够得到HTML代码中所包含的我们想要的数据,比如糗百中每条糗事的文本内容,好笑数,评论数等。这将在下篇进行讲解。
下篇:爬虫修炼之道——从网页中提取结构化数据并保存(以爬取糗百文本板块所有糗事为例)
更多内容请关注公众号:AI派
