上节课我们一起学习了怎样搭建一个6台设备的Hadoop集群,这节课我们一起来学习一下怎样测试我们搭建的集群是否有问题。
第一步:启动Zookeeper
我们启动HDFS之前一定要先启动Zookeeper,否则DFSZKFailoverController这个进程将无法正常启动。
我们分别在itcast04、itcast05、itcast06上启动zookeeper,我们到/itcast/zookeeper-3.4.5/bin目录下执行./zkServer.sh start来启动,如下所示。
[root@itcast04 bin]# ./zkServer.sh start
JMX enabled by default
Using config: /itcast/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@itcast05 bin]# ./zkServer.sh start
JMX enabled by default
Using config: /itcast/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@itcast06 bin]# ./zkServer.sh start
JMX enabled by default
Using config: /itcast/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
启动完zookeeper之后,我们分别在itcast04、itcast05、itcast06上检查是否正常启动,发现一个leader和两个follower,说明正常。
[root@itcast04 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /itcast/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
[root@itcast05 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /itcast/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: leader
[root@itcast06 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /itcast/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
第二步:启动HDFS
启动HDFS我们只需要在itcast01上启动即可,如果已经进行过HDFS格式化,那么以后JournalNode不用单独启动了,启动HDFS就可以了。我们到hadoop-2.2.0目录下,然后使用命令sbin/start-dfs.sh来启动HDFS,启动信息如下所示。
[root@itcast01 hadoop-2.2.0]# sbin/start-dfs.sh
Starting namenodes on [itcast01 itcast02]
itcast01: starting namenode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-namenode-itcast01.out
itcast02: starting namenode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-namenode-itcast02.out
itcast06: starting datanode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-datanode-itcast06.out
itcast05: starting datanode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-datanode-itcast05.out
itcast04: starting datanode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-datanode-itcast04.out
Starting journal nodes [itcast04 itcast05 itcast06]
itcast04: starting journalnode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-journalnode-itcast04.out
itcast06: starting journalnode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-journalnode-itcast06.out
itcast05: starting journalnode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-journalnode-itcast05.out
Starting ZK Failover Controllers on NN hosts [itcast01 itcast02]
itcast02: starting zkfc, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-zkfc-itcast02.out
itcast01: starting zkfc, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-zkfc-itcast01.out
[root@itcast01 hadoop-2.2.0]#
下面我们来详细说一下启动的流程。
首先它启动的是namenode,我们知道我们的集群当中有两个namenode,分别在itcast01和itcast02上,因此首先启动的是namenodes,Starting namenodes on [itcast01 itcast02]第一句信息就是这个意思。itcast01: starting namenode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-namenode-itcast01.out和
itcast02: starting namenode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-namenode-itcast02.out是具体两个namenode的启动信息。我们看到在信息之前有itcast01或者itcast02或其它主机名,说明itcast01不是在本地调用脚本,而是通过SSH协议调用脚本来控制自己及其它设备的。那么问题来了,itcast01怎么知道namenodes在itcast01和Itcast02上的呢?它是根据配置文件hdfs-site.xml来获取的,hdfs-site.xml中有下面一段配置,这段配置指定了nn1和nn2(也就是namenode1和namenode2)在哪台设备上,我们可以清楚的看到,就在itcast01和itcast02上。所以启动的时候itcast01知道去哪台设备上启动namenode了。
dfs.nameservices
ns1
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
itcast01:9000
dfs.namenode.rpc-address.ns1.nn2
itcast02:9000
接下来是启动datanode的信息,如下所示。
itcast06: starting datanode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-datanode-itcast06.out
itcast05: starting datanode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-datanode-itcast05.out
itcast04: starting datanode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-datanode-itcast04.out
那么问题又来了,itcast01怎么知道要去itcast06、itcast05、itcast04上去启动datanode呢?其实它是去slaves配置文件中去读取的。
slaves文件中配置的内容如下,可以看到这里面有三行内容分别是itcast04、itcast05、itcast06,既然namenode都启动起来了,namenode要控制datanode,当然就要启动datanode,因此itcast01便知道通过SSH协议向itcast04、itcast05、itcast06发送指令,让它们启动起来。
itcast04
itcast05
itcast06
接下来是启动journalnode(journalnode是用来存放共享的edits文件的)的信息,如下所示。
Starting journal nodes [itcast04 itcast05 itcast06]
itcast04: starting journalnode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-journalnode-itcast04.out
itcast06: starting journalnode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-journalnode-itcast06.out
itcast05: starting journalnode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-journalnode-itcast05.out
那么itcast01怎么知道journalnode在哪几台设备上呢?其实它是通过hdfs-site.xml的下面这段配置来知道的。itcast01同样通过SSH协议向itcast04 itcast05 itcast06发送启动命令,让它们启动。
dfs.namenode.shared.edits.dir
qjournal://itcast04:8485;itcast05:8485;itcast06:8485/ns1
接下来是ZK Failover Controllers的启动信息,如下所示。
Starting ZK Failover Controllers on NN hosts [itcast01 itcast02]
itcast02: starting zkfc, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-zkfc-itcast02.out
itcast01: starting zkfc, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-zkfc-itcast01.out
那么itcast01是怎么知道要在itcast01和itcast02上启动ZKFailoverController呢?我们首先说一下NameNode和ZKFailoverController是必须在一起的,因此NameNode所在的设备也就是ZKFailoverController所在的设备,通过上面我们知道NameNode在itcast01和itcast02上,因此ZKFailoverController也在这两台设备上。
可以看到,HDFS的启动顺序是有严格顺序的。不是随便启动的。
启动完HDFS之后,我们需要检查一下itcast01和itcast02上的进程,如下所示,发现都有NameNode和DFSZKFailoverController两个进程,说明正常。
[root@itcast01 hadoop-2.2.0]# jps
4936 NameNode
5310 Jps
5202 DFSZKFailoverController
[root@itcast02 hadoop-2.2.0]# jps
4936 NameNode
5310 Jps
5202 DFSZKFailoverController
第三步:启动Yarn
我们集群规划的ResourceManager所在的设备是itcast03,因此我们需要到itcast03上去启动Yarn,我们先到itcast03的hadoop-2.2.0目录下,然后使用命令sbin/start-yarn.sh来启动yarn,启动信息如下所示。
[root@itcast03 hadoop-2.2.0]# sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /itcast/hadoop-2.2.0/logs/yarn-root-resourcemanager-itcast03.out
itcast04: starting nodemanager, logging to /itcast/hadoop-2.2.0/logs/yarn-root-nodemanager-itcast04.out
itcast05: starting nodemanager, logging to /itcast/hadoop-2.2.0/logs/yarn-root-nodemanager-itcast05.out
itcast06: starting nodemanager, logging to /itcast/hadoop-2.2.0/logs/yarn-root-nodemanager-itcast06.out
[root@itcast03 hadoop-2.2.0]#
下面我们来分析一下yarn的启动信息,首先starting yarn daemons(yarn的守护进程)。我们看集群规划当然知道ResourceManager在itcast03上,那么itcast03怎么知道在哪台设备上呢?其实是在yarn-site.xml配置文件中得到的,配置信息如下。
yarn.resourcemanager.hostname
itcast03
从而itcast03知道要在自己身上启动ResoureManager,我们再来说一下starting resourcemanager, logging to /itcast/hadoop-2.2.0/logs/yarn-root-resourcemanager-itcast03.out这条信息,我们发现前面没有主机名,说明itcast03没有通过SSH协议启动自己身上的ResourceManager,而是通过本地脚本启动的,而启动nodemanager前面有主机名说明是通过SSH协议远程控制启动的。
itcast03是怎么知道要去itcast04、itcast05、itcast06上去启动nodemanager呢?其实也是通过slaves文件来获取的,resourcemanager控制nodemanager,因此是itcast03去启动各个nodemanager。需要说明的是,nodemanager的数量是可以和datanode不一样的,不过建议最好保持一致。
启动完yarn之后,我们需要查看一下itcast03上的进程,发现ResourceManager确实已经启动,说明正常。
[root@itcast03 hadoop-2.2.0]# jps
3441 ResourceManager
3686 Jps
第四步:通过浏览界面检验
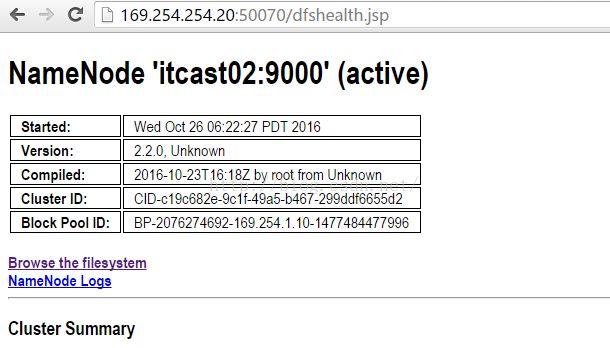
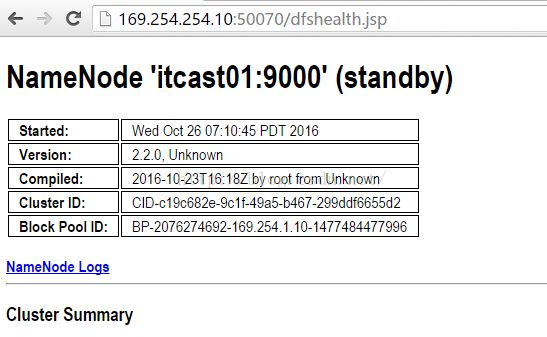
经过前三步,我们已经将Hadoop启动起来了,接下来我们便开始正式测试这个集群的可靠性如何。我们在浏览器地址栏中输入:169.254.254.10:50070即可看到如下图所示的界面,需要说明的是,169.254.254.10是itcast01的IP地址,你的itcast01的IP地址是多少就写多少,50070是查看HDFS的默认端口,直接使用它就可以。可以发现我们可以正常访问HDFS的界面。而且我们发现itcast01上的状态是"active",那么itcast02上就应该是standby状态。
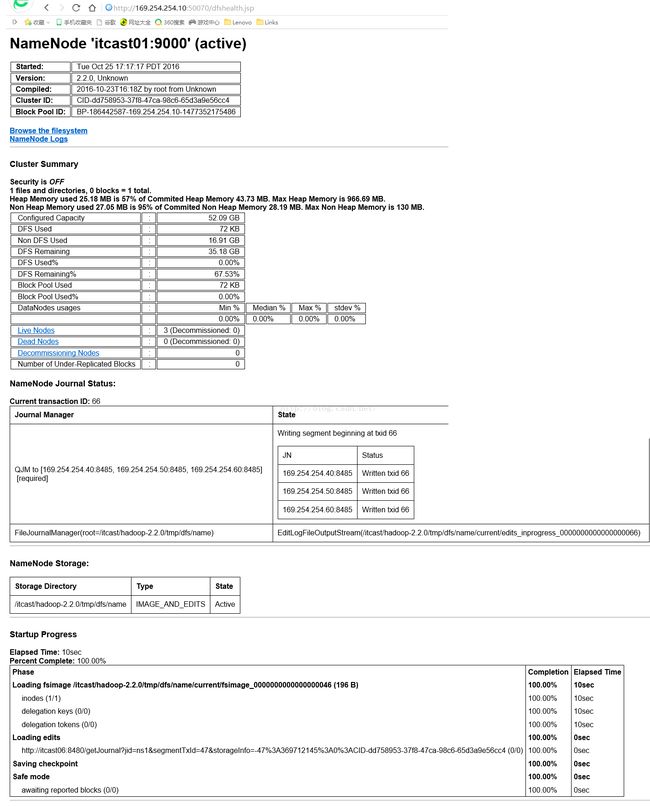
光理论不行,我们得亲自验证一下itcast02上的状态是否真的是standby状态,于是我们在地址栏输入169.254.254.20:50070就可以查看itcast02的界面,如下图所示,发现确实是standby状态,说明正常。
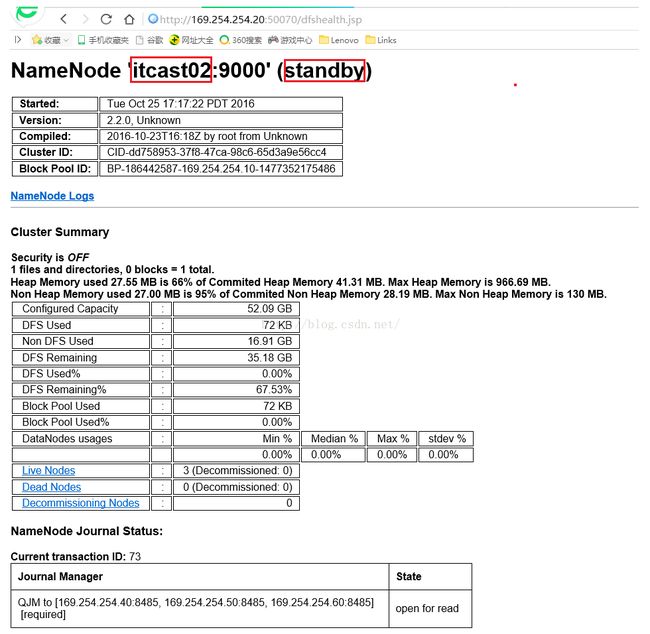
我们再看看itcast01的"Live Nodes"节点信息,我们点击itcast01界面的"Live Nodes"链接,会看到如下图所示信息,活着的Node有itcast04、itcast05、itcast06,这三台设备上都有DataNode节点,说明正常。

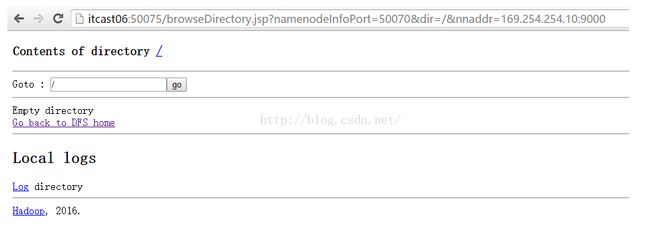
我们还可以查看itcast01的FileSystem,我们点击itcast01界面的"Browse the filesystem"链接,程序会自动跳转到itcast04或itcast05或itcast06上,因为这三台设备的身份是datanode,是专门用来存储数据的。会看到如下图所示界面,发现当前根目录下没有任何文件,也是正常。
** 需要注意的是,我刚开始碰到了点击“Browse the filesystem”没有反应的问题,原来是我Windows下的hosts文件配置的有问题。需要配置你的虚拟机的IP地址和主机名的映射关系,我现在正确配置的内容如下,你根据你搭建的环境配置好就可以了。**
169.254.254.10 itcast01
169.254.254.20 itcast02
169.254.254.30 itcast03
169.254.254.40 itcast04
169.254.254.50 itcast05
169.254.254.60 itcast06
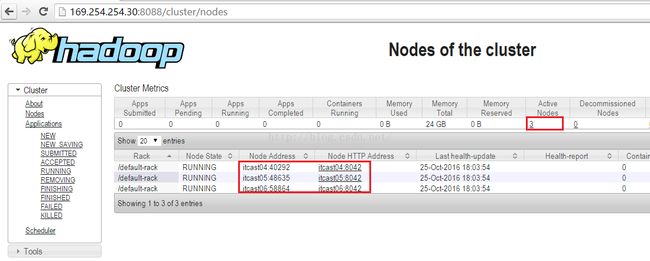
接下来我们检验Yarn的管理界面是否正常,我们在地址栏输入:169.254.254.30:8088,需要说明的是,169.254.254.30是我itcast03的IP地址,8088是Yarn的默认端口不用改,你根据你的itcast03的IP来输入就可以,页面打开后,我们可以看到有一列是"Active Nodes",值是3,我们点击那个3,就可以看到如下图所示的界面,我们可以看到Yarn活跃的子节点(nodemanager)数量是3个,分别是itcast04、itcast05、itcast06这三台设备。说明这项也正常。
第五步:核心功能检验
第四步只是简单看了下界面有没有问题,这还远远不够,一个集群是否具有高可靠性,一定要经过重重检验才可以。下面我们分几步来分别检验。
5.1 itcast01到itcast02角色切换
5.1.1 既然是高可靠性,那么itcast01和itcast02就都有可能充当active角色,一旦active的设备异常或宕机了,处于standby状态的设备立马顶上去工作,因此standby状态的设备与active状态的设备的数据一定是实时同步的,否则虽然角色正常切换了,但是数据不一致,这也是灾难性的后果。因此我们第一步先向处于active状态的设备上传一个文件。待后面active状态的设备出现异常或宕机,我们便可以从新变为active状态的设备上去检验是否有这个文件,文件内容是否一致。
我们从itcast03的root根目录下把install.log文件上传到HDFS系统根目录下,并且起名叫log,如下所示。
[root@itcast03 ~]# ls
anaconda-ks.cfg Desktop Documents Downloads install.log install.log.syslog Music Pictures Public Templates Videos
[root@itcast03 ~]# hadoop fs -put install.log /log
[root@itcast03 ~]#
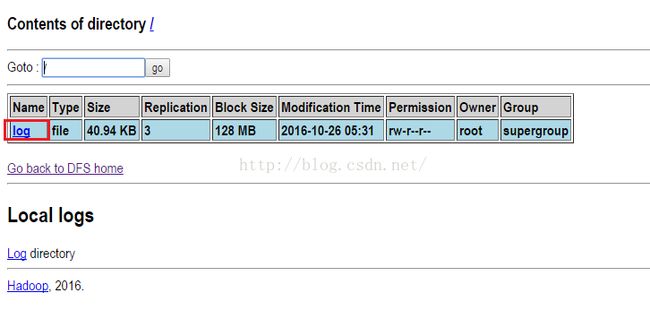
5.1.2 上传完之后,我们去itcast01上去看下是否有我们刚上传的log文件,我们首先在地址栏输入169.254.254.10:50070回车后会看到如下所示界面,说明当前是itcast01在管理我们的文件,我们点击"Browse the filesystem"。

点击上图的"Browse the filesystem"之后,我们可以看到如下图所示的界面,发现确实有我们刚才上传的log文件,说明上传成功。
5.1.3 我们人为杀掉itcast01的namenode进程,我们先使用jps查看当前进程,发现namenode的进程号是25781,那么我们便使用命令kill -9 25781来强制杀掉这个进程。杀掉之后我们再使用命令jps来检查一下,发现确实已经没有namenode进程了。
[root@itcast01 ~]# jps
26038 DFSZKFailoverController
25781 NameNode
26294 Jps
[root@itcast01 ~]# kill -9 25781
[root@itcast01 ~]# jps
26038 DFSZKFailoverController
26309 Jps
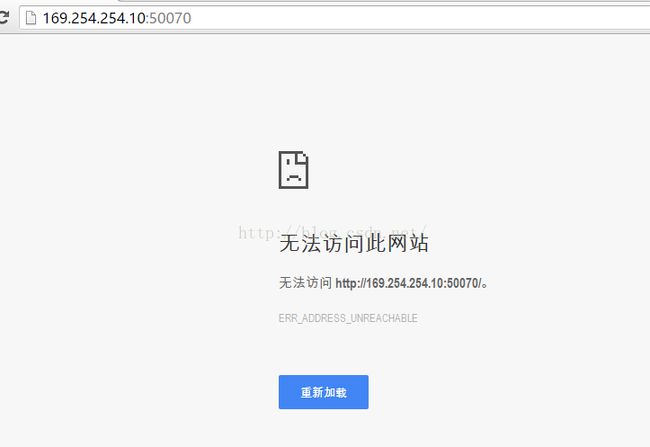
我们再到浏览器中访问itcast01,看还能不能访问,如下图所示,发现已经无法访问。
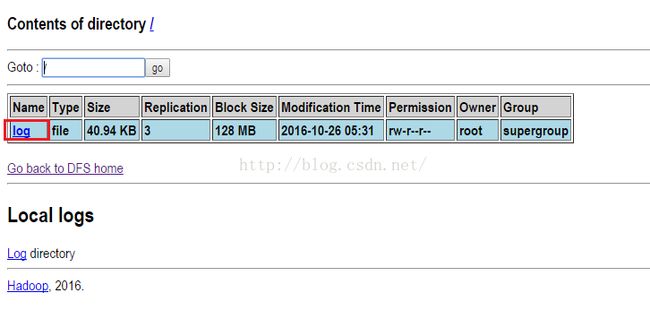
既然itcast01不能访问了,那么我们来访问一下itcast02,看它当前的状态是什么,如下图所示,发现现在itcast02的状态已经自动变换成active了,而且现在是itcast02在管理文件系统了,我们点击Browse the filesystem(文件系统),看itcast02上是否管理者我们刚才上传的log文件。

点击上图的"Browse the filesystem"之后,我们发现确实有log这个文件,如下图所示。
5.1.4 我们再将itcast01的namenode进程启动起来,并查看它现在的角色是什么角色,我们先到hadoop-2.2.0目录下,然后使用命令sbin/hadoop-daemon.sh start namenode来单独启动namenode进程。启动完之后我们使用命令jps来查看当前进程,发现namenode进程已经启动起来了,如下所示。
[root@itcast01 hadoop-2.2.0]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-namenode-itcast01.out
[root@itcast01 hadoop-2.2.0]# jps
26038 DFSZKFailoverController
26385 NameNode
26453 Jps
[root@itcast01 hadoop-2.2.0]#
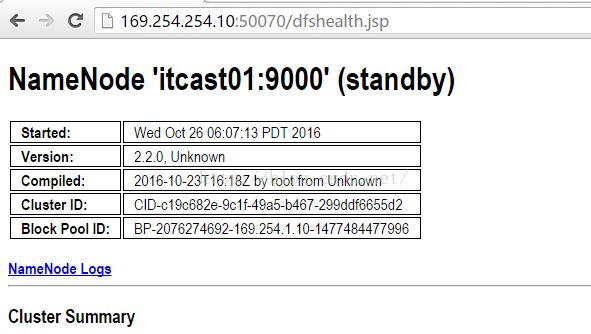
接着我们访问itcast01的界面,如下图所示,我们发现itcast01已经是standby状态了,而且它现在不能管理文件系统了。说明切换完全正常。
5.2 从itcast02到itcast01的角色切换
5.2.1 既然现在itcast02是active状态,要想切换角色,就先杀掉itcast02上的namenode进程,我们使用jps查看itcast02上的进程,发现namenode的进程是3242,因此我们使用kill -9 3242强制杀掉namenode进程,杀掉之后再检查一下是否真的杀掉了。发现确实已经杀掉了。
[root@itcast02 hadoop-2.2.0]# jps
25843 Jps
3242 NameNode
2948 DFSZKFailoverController
[root@itcast02 hadoop-2.2.0]# kill -9 3242
[root@itcast02 hadoop-2.2.0]# jps
25861 Jps
2948 DFSZKFailoverController
[root@itcast02 hadoop-2.2.0]#
我们这时再访问itcast02的界面,如下图所示,发现itcast02已经无法访问了。
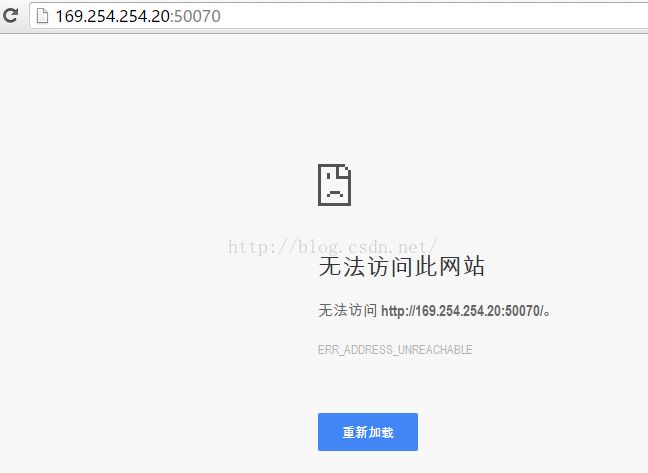
5.2.2 我们来查看itcast01的界面,看它现在是什么状态,发现itcast01现在又自动切换成active状态了。
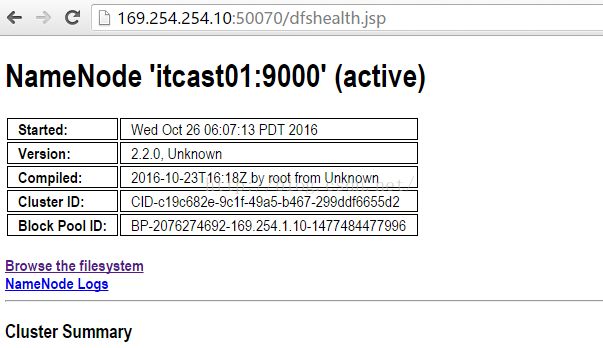
我们再来从itcast01浏览文件系统,点击"Browse the filesystem",会出现如下图所示的界面,发现确实有log文件。
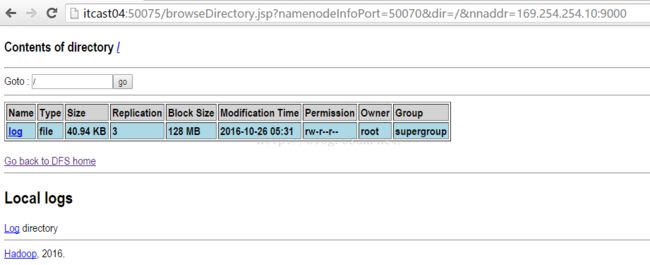
5.2.3 我们再启动itcast02上的namenode进程,如下所示。
[root@itcast02 hadoop-2.2.0]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-namenode-itcast02.out
[root@itcast02 hadoop-2.2.0]# jps
25952 Jps
2948 DFSZKFailoverController
25905 NameNode
[root@itcast02 hadoop-2.2.0]#
启动之后,我们再来查看itcast02的界面,发现itcast02现在又变回了standby状态,而且也不再管理文件系统,说明我们从itcast02到itcast01的角色切换完全正确。
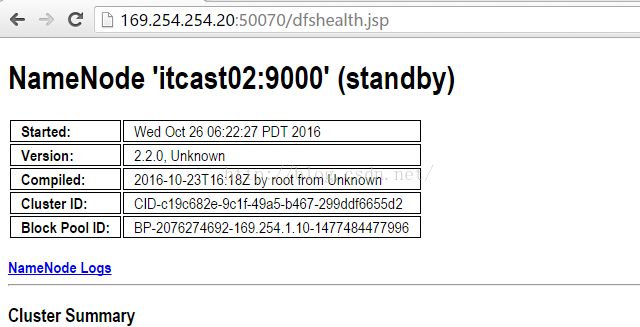
5.3 通过宕机来检验集群是否正常
前面我们是通过人为杀掉某台设备的namenode来检验集群是否能正常切换角色的,要知道我们只杀掉了namenode进程并没有杀掉DFSZKFailoverController进程,而这个进程是专门来监听namenode的状态的,一旦处于Active状态的namenode挂掉了,DFSZKFailoverController便会向Zookpeer报告,另一台设备上的DFSZKFailoverController进程从Zookeeper同步获取Active状态的namenode挂掉的信息,它便向它控制的namenode发送指令让它由Standby状态切换为Active状态。因此我们刚才测试的是没有问题的。
那么我们现在假如namenode所在设备宕机了,这也就意味着DFSZKFailoverController进程也一块死掉了,从而没有进程向Zookeeper汇报Active状态的namenode的状态了。我们便来测试一下这种情况集群是否能自动完成角色切换。
5.3.1 我们关闭itcast01虚拟机,我们在itcast01所在的虚拟机上右键,鼠标移动到“电源”上,然后点击“关闭客户机(D)”。
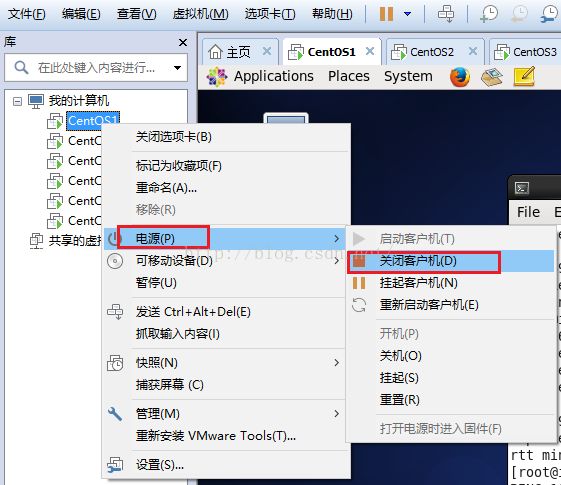
关闭itcast01虚拟机后,我们停30秒再检查itcast02的界面,发现itcast02已经自动切换成Active状态了!说明连宕机这种情况,我们的集群依然可以很好的应对。
那么为什么我们要等待30秒再查看itcast02的状态呢,这是因为我们在hdfs-site.xml中配置了30秒超时自动切换功能,如下所示。
宕机的情况下集群怎么做到去切换的呢?其实也是在hdfs-site.xml配置的,shell(/bin/true)就是配置的关键,当处于Active状态的设备宕机时,另一台设备的DFSZKFailoverController进程长时间得不到信息,于是它便去执行shell(/bin/true)这段脚本,如果脚本返回true,它便向自己控制的namenode发送指令让他由Standby状态切换为Active状态。
sshfence
shell(/bin/true)
上面是验证集群高可靠性的所有步骤,接下来说一些扩展的内容。
补充一:学会看Hadoop官方文档,我们配置文件中配置的内容在官方文档都可以看到,官方文档我们可以从hadoop解压后的包中找到,如下图所示,我们点击"index.html"便可以查看。
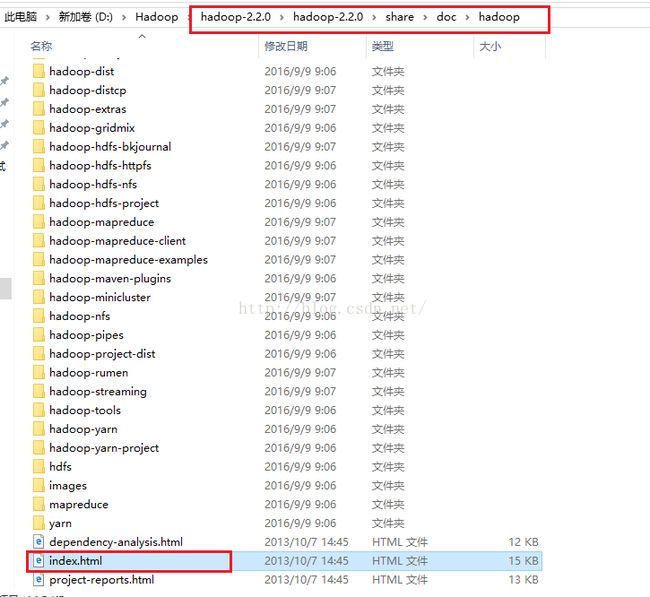
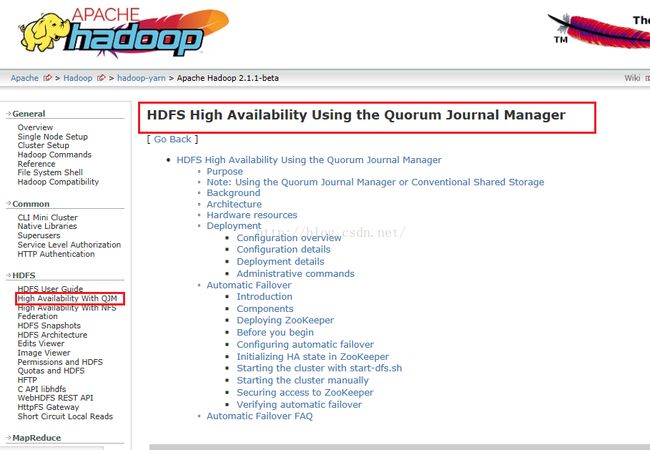
点击上图的"index.html"之后,我们会看到如下图所示的界面,高可靠性的文档内容在HDFS下的**High Availability With QJM**链接下。在里面大家好好看看其中的内容。
补充二:重新启动itcast01这台虚拟机并重新启动namenode和zkfc。
[root@itcast01 ~]# jps
2587 Jps
[root@itcast01 ~]# cd /itcast/hadoop-2.2.0/
[root@itcast01 hadoop-2.2.0]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-namenode-itcast01.out
[root@itcast01 hadoop-2.2.0]# jps
2618 NameNode
2655 Jps
[root@itcast01 hadoop-2.2.0]# sbin/hadoop-daemon.sh start zkfc
starting zkfc, logging to /itcast/hadoop-2.2.0/logs/hadoop-root-zkfc-itcast01.out
[root@itcast01 hadoop-2.2.0]# jps
2760 Jps
2714 DFSZKFailoverController
2618 NameNode
[root@itcast01 hadoop-2.2.0]#
我们启动完之后,查看itcast01的界面,发现itcast01现在是standby状态了。
补充三:用Java代码来验证我们的集群
既然要写java代码了,我们就要用到Eclipse,关于Eclipse的安装大家可以参考http://blog.csdn.net/u012453843/article/details/52600313这篇博客来学习,在那篇博客中我们新建一个Maven工程有详细的步骤,我们新建的Maven工程如下图所示。注意:关于Eclipse自动会关闭的问题,在我给的http://blog.csdn.net/u012453843/article/details/52600313这篇博客中是有解决方法的,还有关于快捷键的设置在这篇博客中也有详细说明。
要想跑代码,就要依赖相关的jar包,Maven是专门帮我们管理jar包的,前提是有本地仓库可供管理。我试了下连网自动导入jar包,发现很多包都找不到,说明中央仓库的包比较新,缺少我们hadoop-2.2.0所需要的一些jar包。因此我们还是采用人为在本地创建一个本地仓库的方式吧,关于如何操作,大家依然可以从http://blog.csdn.net/u012453843/article/details/52600313这篇博客中找到答案。我们配置完pom.xml文件后,发现Maven Dependencies下自动多了好多jar包,这就是我们需要用到的jar包,Maven帮我们自动引用了。Maven配置文件的内容如下图所示,红色为新增的配置。
4.0.0
< groupId>com.myhadoop.mr
hadoop
0.0.1-SNAPSHOT
org.apache.hadoop
hadoop-common
2.2.0
org.apache.hadoop
hadoop-hdfs
2.2.0
org.apache.hadoop
hadoop-mapreduce-client-core
2.2.0
准备好了环境,我们便开始写Java代码了,虚拟机中如果我们想使用中文的话,大家可以参考http://blog.csdn.net/u012453843/article/details/52777530这篇博客来进行安装和设置。如果配置完没按Ctrl+Space键没有立即生效的话,就重启Eclipse,重启后就可以使用中文输入法了。
下面是我们写的测试类HDFSDemo_HA,在main方法中我们测试了从集群上下载文件。
package com.hadoop.hdfs;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HDFSDemo_HA {
public static void main(String[] args) throws IOException, URISyntaxException{
//新建一个配置文件
Configuration conf=new Configuration();
//我们客户端现在不能直接连向itcast01或itcast02,因为它们的状态
//是不缺定的,我们能连的就是nameservice了,我们根据hdfs-site.xml
//文件来配置nameservices。
conf.set("dfs.nameservices", "ns1");
//配置完nameservice还要配置nameservice管理的两台设备
conf.set("dfs.ha.namenodes.ns1", "nn1,nn2");
//具体配置nn1和nn2都在哪台设备上
conf.set("dfs.namenode.rpc-address.ns1.nn1", "itcast01:9000");
conf.set("dfs.namenode.rpc-address.ns1.nn2","itcast02:9000");
//配置失败自动切换实现类,就是这个类知道到底哪个是活跃的,哪个是standby的
conf.set("dfs.client.failover.proxy.provider.ns1",
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
//获取文件系统
FileSystem fos=FileSystem.get(new URI("hdfs://ns1"), conf);
//获取输入流
InputStream in=fos.open(new Path("/log"));
//新建输出流,写到本地
OutputStream out=new FileOutputStream("/root/123.txt");
//写向本地
IOUtils.copyBytes(in, out, 4096, true);
}
}
代码执行完之后,我们到/root目录下看是否多了一个123.txt文件,发现确实有这个文件了。说明下载功能正常。
[root@itcast01 ~]# ls -l
total 438288
-rw-r--r--. 1 root root 41918 Oct 26 10:20 123.txt
-rw-------. 1 root root 3358 Oct 26 03:52 anaconda-ks.cfg
drwxr-xr-x. 2 root root 4096 Oct 26 09:38 Desktop
drwxr-xr-x. 2 root root 4096 Oct 26 04:05 Documents
drwxr-xr-x. 2 root root 4096 Oct 26 04:05 Downloads
-rw-r--r--. 1 root root 260603076 Oct 26 07:23 eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz
-rw-r--r--. 1 root root 96096075 Oct 26 04:57 hadoop-2.2.0.tar.gz
-rw-r--r--. 1 root root 41918 Oct 26 03:52 install.log
-rw-r--r--. 1 root root 25485 Oct 26 03:51 install.log.syslog
-rw-r--r--. 1 root root 91936250 Oct 26 08:05 m2.tar.gz
drwxr-xr-x. 2 root root 4096 Oct 26 04:05 Music
drwxr-xr-x. 2 root root 4096 Oct 26 04:05 Pictures
drwxr-xr-x. 2 root root 4096 Oct 26 04:05 Public
drwxr-xr-x. 2 root root 4096 Oct 26 04:05 Templates
drwxr-xr-x. 2 root root 4096 Oct 26 04:05 Videos
drwxr-xr-x. 5 root root 4096 Oct 26 07:28 workspace
[root@itcast01 ~]#
接下来我们测试一下上传功能,我们在原来的HDFSDemo_HA类的main方法中只需要改下输入和输出流就可以,其它代码不用改,要改的代码如下。
**InputStream in=new FileInputStream("/root/m2.tar.gz");
OutputStream out=fos.create(new Path("/m2"));**
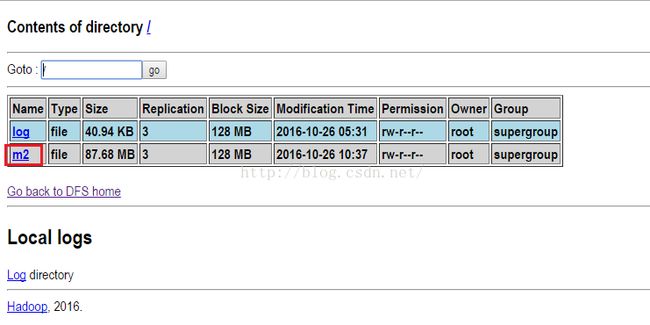
我们跑一下程序,跑完之后,我们到HDFS系统看下是否已经有叫m2的文件,如下图所示,发现确实已经有m2文件了。说明上传也没问题。
补充四:测试Yarn的功能是否正常
我们在itcast01的root根目录下新建一个wc.txt文件并在文件中输入的内容如下。
[root@itcast01 ~]# vim wc.txt
hello tom
hello jerry
hello kitty
hello tom
hello world
接着我们把wc.txt文件上传到HDFS系统,使用的命令如下。
[root@itcast01 ~]# hadoop fs -put wc.txt /wc
[root@itcast01 ~]#
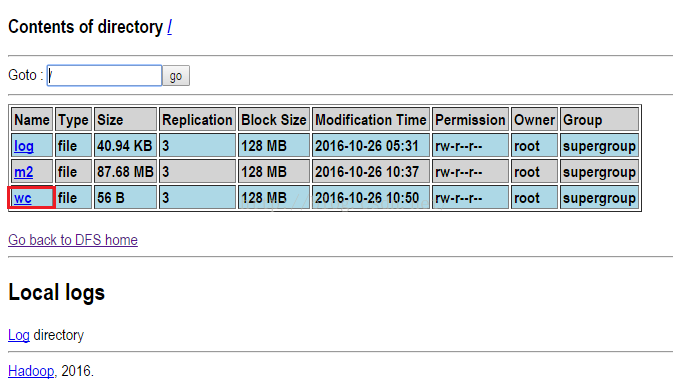
上传完后我们到HDFS系统查看是否已经上传上来了,如下图所示,发现确实已经上传上来了。
接下来我们使用hadoop自带的wordcount统计功能来统计一下单词的数量,hadoop jar是用来执行某个jar包的某个功能的。我们现在就是要用**hadoop-mapreduce-examples-2.2.0.jar **这个jar包的wordcount功能。这个功能需要输入和输出两个参数,输入我们写HDFS系统根目录下的wc文件,输出我们命名为wcout也放到HDFS系统根目录下。
[root@itcast01 ~]# hadoop jar /itcast/hadoop-2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /wc /wcout
上面的命令执行成功之后,我们到HDFS系统查看一下,我们首先看一下根目录,发现已经生成wcout文件。
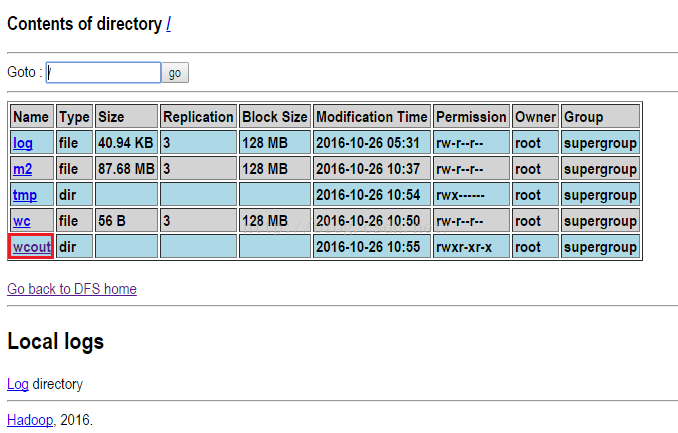
接着我们进入wcout内,可以看到内部有两个文件,其中part-r-00000文件是我们的结果文件,我们点进去。

点进去之后我们可以看到如下图所示的界面,发现单词的数量已经统计出来了,而且数量完全正确。
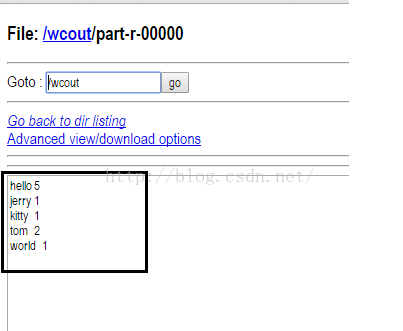
好了,以上便是Hadoop集群测试的所有内容。