案例说明:1.本例使用了两台pc作为实验对象;
2.本例中的master的ip为192.168.1.103;slave2的ip为192.168.1.102;
一、新建用户
1.linux 如何创建新用户:
sudo useradd -m hadoop -s /bin/bash
2.新建用户设置密码 :
sudo passwd hadoop
3.增加管理员权限:
sudo adduser hadoop sudo
4.更新apt:
sudo apt-get update
5.安装vim:
sudo apt-get install vim
二、网络配置
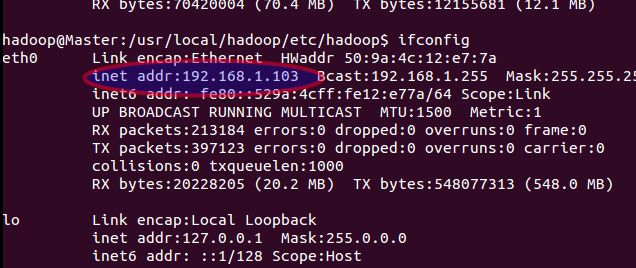
1.查看ip :
ifconfig
2.修改主机名:
sudo vim /etc/hostname
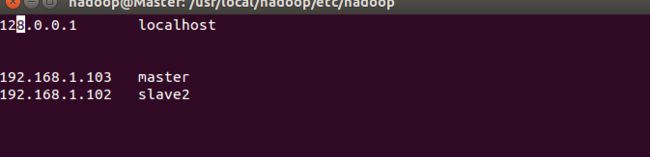
3.修改所有节点(slave2也要修改)的ip映射:
ifconfig #查看master 的ip
sudo vim /etc/hosts
4.测试是否配置好:
ping slave2 -c 3 #只ping3次 或者 ping ip
三、安装、配置ssh无密码登录
1.安装ssh:
sudo apt-get install openssh-server
2.登陆本机:
ssh localhost
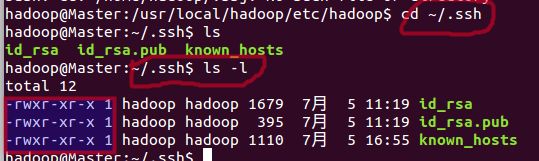
3.退出ssh登录的localhost,ssh-keygen生成密钥,并将密钥加入到授权中:
exit
cd ~/.ssh/
ssh-keygen -t rsa #如果执行不成功在最前面加sudo
cat ./id_rsa.pub >> /.authorized_keys #如果报错权限问题,需要重新为~/.shh复制权限
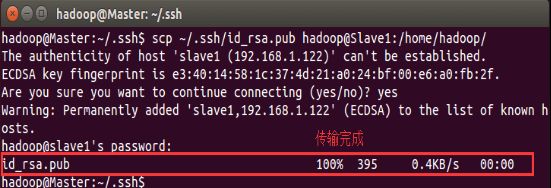
4.传输公钥到slave2节点:
scp ~/.ssh/id_rsa.pub hadoop@slave2:/home/hadoop/
5.在slave2节点上,将ssh公钥加入授权:
mkdir ~/.ssh
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys #将密钥加入
rm ~/id_rsa.pub #可以不删除
6.登出用户 选择log out;在重新登录
7.在master上进入slave2节点:
ssh slave2
(如果出现问题实在解决不了可重装) 卸载ssh:
sudo apt-get --purge remove openssh-serve
四、Java安装配置
千万不能安装openjdk,血泪史。
1.下载Jdk-8u131-linux-x64.tar.gz并解压
sudo tar -zxf ~/Downloads/jdk-8u131-linux-x64.tar.gz -C /usr/local #解压命令
2.添加java环境:
sudo vim ~/.bashrc
加入下列变量:
export JAVA_HOME=/usr/local/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/rt.jar
3.使环境变量生效:
source ~/.bashrc
4.验证java环境配置正确与否
echo $JAVA_HOME
Java -version
$JAVA_HOME/bin/java -version #应该输出相同结果
五、Hadoop安装
1.下载Hadoop安装至/usr/local
sudo tar -zxf ~/Downloads/hadoop-2.7.3.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-2.7.3/ ./hadoop #修改名字
sudo chown -R hadoop ./hadoop # 赋予权限
2.查看Hadoop是否可用
cd /usr/local/hadoop
./bin/hadoop version
3.hadoop环境配置
sudo vim ~/.bashrc
添加如下变量
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
执行
source ~/.bashrc
六、Hadoop集群配置
cd /usr/local/hadoop/etc/hadoop
1.修改hadoop-env.sh
sudo vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_131
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:/usr/local/hadoop/bin
2.修改slaves删除localhost加入 slave2
sudo vim slaves
3.修改core-site.xml
fs.defaultFS
hdfs://Master:9000
io.file.buffer.size
131072
hadoop.tmp.dir
/usr/local/hadoop/tmp
4.修改hdfs-site.xml
dfs.namenode.secondary.http-address
Master:50090
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/hdfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/hdfs/data
5.修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
修改mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master:10020
mapreduce.jobhistory.address
Master:19888
6.修改yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
Master:8032
yarn.resourcemanager.scheduler.address
Master:8030
yarn.resourcemanager.resource-tracker.address
Master:8031
yarn.resourcemanager.admin.address
Master:8033
yarn.resourcemanager.webapp.address
Master:8088
7.复制master节点的Hadoop文件夹到slave2上
scp -r /usr/local/hadoop hadoop@slave2:/usr/local
如果报错一般由于权限问题无法访问,可以执行:
scp -r /usr/local/hadoop hadoop@slave2:/home/hadoop
ssh slave2
sudo cp -r ~/hadoop /usr/local
sudo chown -R hadoop /usr/local/hadoop
8.在slave2上,安装java,并在~/.bashrc配置java、Hadoop环境(参考上文)
9.首次启动需要在Master节点执行NameNode的格式化:
hdfs namenode -format
10.测试Hadoop是否安装成功
start-dfs.sh
start-yarn.sh
查看集群是否启动成功,输入在master输入jps显示:
SecondaryNameNode
ResourceManager
NameNode
在slave2上输入jps显示:
NodeManager
DataNode
另外需要在Master节点通过命令
hdfs dfsadmin -report
查看DataNode启动。
安装出现的问题:
1.安装openjava出现hadoop无法启动,需要卸载openjava,在安装sun java;
2.Nodedata不能启动,用户对/usr/local/hadoop文件夹权限不足,不能读取;必须对slave机器的hadoop文件夹设置权限,sudo chown -R hadoop /usr/local/hadoop, 如果是权限比较大的用户如root不会出现问题;
3. Configured Capacity: 0 (0 KB)
Present Capacity: 0 (0 KB)
DFS Remaining: 0 (0 KB)
DFS Used: 0 (0 KB)
DFS Used%: �%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
解决方法:
关闭安全模式:
hadoop路径/bin/hadoop dfsadmin -safemode leave
修改Hadoop core-site.xml 因为nodedata不能识别master
fs.defaultFS
hdfs://192.168.1.103:9000