主要内容包括:
1、基于boosting级联学习的遥感目标检测
Adaboost算法、前向分步算法、提升树、梯度提升、级联学习框架、Haar特征、级联分类器训练方法
2、基于随机几何模型的遥感目标检测
点过程、标记点过程
3、基于主题语义模型的遥感目标提取
分水岭分割、特征提取、主题语义建模、PLSA统计、分割区域语义判定
1、基于boosting级联学习的遥感目标检测
【Adaboost算法】
boosting算法通过改变训练样本的权重,学习多个分类器,并将这些分类器线性组合以提高分类的性能。其中强分类器是指正确率很高的学习算法;弱分类器是指正确率只比随机猜测好一点的学习算法。
总的来说是对于同一个训练样本集,设置初始权重,求另损失函数最小的弱分类器,对错分的样本更改权重使其更加重要,再次求弱分类器,最后将这些弱分类器进行线性相加。
两个关键问题:1、权值如何改变 2、如何组合弱分类器
Adaboost算法的具体步骤
输入:二类分类的训练集 T ={(x_1,y_1), (x_2,y_2)..(x_n,y_n)} 其中x_i为样本实例,y_i为标记;弱学习算法
输出:最终分类器
(1) 初始化训练数据的权值分布,得到D1 = {w_1...w_n}。假设数据集有均匀权值分布时表示训练样本正在基本分类器学习中作用相同
(2) 对 m =1,2,3..M,使用具有权值分布的Dm的训练集进行学习,得到基本分类器Gm(x)。随后Adaboost会反复学习基本分类器。
(3) 计算Gm(x)的分类误差率e_m,为权值乘以分错的概率。
(4) 通过某种方式计算Gm(x)的系数,参数为e_m。e_m大于1/2时α_m大于零且随e的减小而增大,所以分类误差率越小的基本分类器在最终分类器作用越大。

(5) 更新训练数据的权值分布为Dm+1,计算方式为
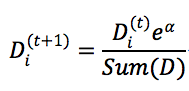
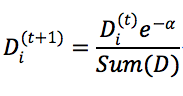
Sum(D)是对权重的规范化,它使Dm+1成为概率分布。被误分类的样本权值得以扩大,在下一轮起到更大作用。
(6) 构建基本分类器的线性集合 f(x) = Σ(α_m × Gm(x) ),最后得到最终分类器G(x) = sign( f(x) )。实现M个分类器的加权表决, f(x)表示分类的确信度。
【前向分步算法】
可以认为Adaboost算法是“模型为加法模型、损失函数为指数函数、学习算法为前向分布算法”时的二类分类学习方法。在Adaboost算法中,我们的最终目的是通过构建弱分类器的线性组合来得到最终分类器:
加法模型的一般形式:
显然式8.6是一个加法模型。
对于加法模型,在给定训练数据及损失函数L(y, f(x))的条件下,学习加法模型f(x)就成为经验风险极小化损失函数极小化问题,但这是一个复杂的优化问题。
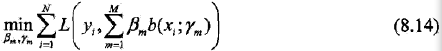
前向分布算法(forward stagewise algorithm)求解这一优化问题的想法是:因为学习的是加法模型,那如果能够从前向后,每一步只学习一个基函数及其系数,然后逐步逼近优化目标式8.14,那么就可以简化优化的复杂度。具体的,每步只需优化如下损失函数:
前向分布算法步骤

这样,前向分布算法将同时求解从m=1到M的所有参数βm, rm的优化问题简化为逐次求解各个βm, rm的优化问题。
【提升树】
提升树是以决策树为弱分类器的提升方法,通常使用CART树。提升树被认为是统计学习中性能最好的方法之一。
提升树方法实际采用:加法模型 + 前向分布算法 + CART树(基函数)。在Adaboost的例子中看到的弱分类器xv,可以看做是由一个根结点直接连接两个叶结点的简单决策树,即所谓的决策树桩。提升树模型可以表示为决策树的加法模型:
提升树算法
首先,确定初始提升树f0(x)= 0,于是第m步的模型就是:
其中fm-1(x)是当前模型,通过经验风险极小化确定下一棵决策树的参数θm,
由于树的线性组合可以很好的拟合训练数据,即使数据中的输入与输出之间的关系很复杂也可以很好的拟合。所以提升树是一个高功能的学习算法。
针对不同问题的提升树学习算法,其主要区别在于使用的损失函数不同。包括用平方误差损失函数的回归问题,用指数损失函数的分类问题,以及用一般损失函数的一般决策问题。
对于二类分类问题,提升树算法只需将Adaboost中的弱分类器限制为二类分类树即可。下面叙述回归问题的提升树:已知一个训练数据集T={(x1,y1), (x2, y2), ..., (xN, yN)},x∈X⊆ Rn,X为输入空间,yi∈Y⊆ R,Y为输出空间。如果将输入空间X划分为J个互不相交的区域R1, R2, ..., RJ,并且在每个区域上确定输出的常量cj,那么树可以表示为:
回归问题提升树使用以下前向分布算法:

R是当前模型拟合数据的残差。所以对回归问题的提升树算法来说,只需简单的拟合当前模型的残差。这样,算法是相当简单的。
现将回归问题的提升树算法叙述如下

【梯度提升】
上面的提升树算法利用加法模型与前向分步算法实现学习的优化过程。虽然当损失函数时平方损失和指数损失函数时,每一步的优化很简单,但对于一般损失函数而言,往往每一步的优化并不那么容易。而梯度提升(gradient boosting)算法就是解决这个问题的。梯度提升算法利用最速下降法的近似方法,其关键是利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中残差的近似值,拟合一个回归树。
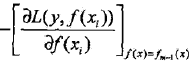
【级联学习框架】
传统的Adaboost算法关注最小化错误率,但是目标检测时负样本出现的概率通常远高于正样本概率,有人提出了非对称的Adaboost算法,引入非对称的损失函数使正样本被错分的损失更大。目前遥感图像数据特点导致利用级联学习来检测的方法不多见。介绍一套实时的遥感目标自动检测系统。
【Haar特征】
构建分类器时主要采用Haar特征。Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。它分为三类:边缘特征、线性特征、中心特征和对角线特征。用黑白两种矩形框组合成特征模板,在特征模板内用 黑色矩形像素和 减去 白色矩形像素和来表示这个模版的特征值。

如上图A、B、D模块的图像Haar特征为:v=Sum白-Sum黑 ; C模块的图像Haar特征为:v=Sum白(左)+Sum白(右)-2*Sum黑.这里要保证白色矩形模块中的像素与黑色矩形的模块的像素数相同,所以乘2
对于一幅图像来说,可以通过通过改变特征模板的大小和位置,可穷举出大量的特征来表示一幅图像。上图的特征模板称为“特征原型”;特征原型在图像子窗口中扩展(平移伸缩)得到的特征称为“矩形特征”;矩形特征的值称为“特征值”。矩形特征值是矩形模版类别、矩形位置和矩形大小这三个因素的函数。在工程中需要进行快速计算某个矩形内的像素值的和,这就需要引入积分图的概念,有利于大尺寸遥感图像中小尺度目标的检测
积分图的定义:
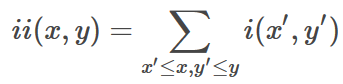
那么我们实现的时候是如何进行计算积分图的呢?
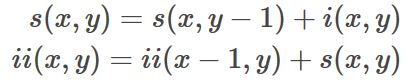
计算方块内的像素和:
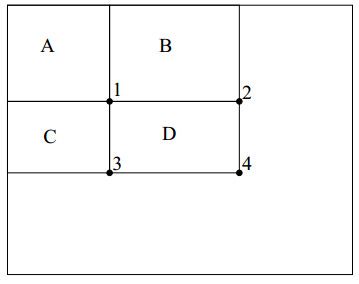
有四个位置分别为1、2、3、4。要计算D区域内部的像素和:记位置4的左上的所有像素为rectsum(4),那么
D位置的像素之和就是rectsum(1)+rectsum(4)−rectsum(2)−rectsum(3)。
有了积分图,就可以很快地计算出了任意矩形内的像素之和
三种类型的Haar-like特征中,二矩形特征需要6次查找积分图中的值,而三矩形特征需要8次查找积分图中的值,而对角的特征需要9次。
【使用级联分类器对Haar特征进行训练】
在输入图像之后首先计算积分图,然后通过积分图在计算上述三种特征,如果窗口的大小为24*24像素,那么生成的特征数目有16000之多。
(1)弱分类器的定义
Adaboost算法中需要定义弱分类器,该弱分类器的定义如下:

上述公式中的pj是为了控制不等式的方向而设置的参数。
fj(x)表示输入一个窗口x,比如24*24像素的窗口,通过fj提取特征,得到若干特征。通过一个阈值θ判定该窗口是不是所要检测的物体。
(2)adaboost算法
假设训练样本图像为(x1,y1),…,(xn,yn),其中yi=0,1,0表示负样本,1表示正样本。
首先初始化权重w1,i=12m,初始化yi为22l,其中m表示负样本的个数,l表示正样本的个数。

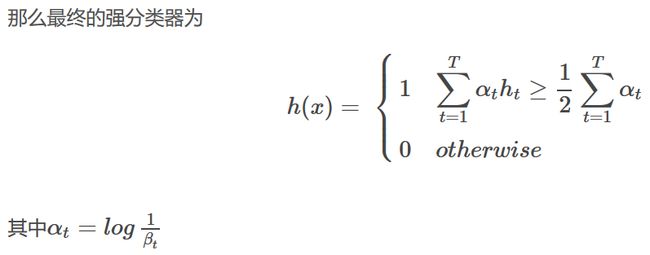
(3) 动态级联训练
每一级强分类器都是通过前面所有级的样本训练构造而成。难的样本交给更深级的分类器。
给定一个级联分类器,误检率为f1,f2...,fn,检测率为d1,d2..dn,N个非目标窗口经过n个强分类器后的误分率为N*f1*f2*...*fn,整个分类器的误检率为F = f1*f2*...*fn,检测率为D = d1*d2*...*dn
训练级联分类器以达到给定的检测率D和误检率F,只需要分别训练N个具有检测率 d_i 和误检率 f_i 的强分类器。通过增加弱分类器的个数来逼近F,但是要考虑计算时间。
构造级联分类器的算法:
(1)确定每级的最大误检率 f,最小检测率 d,以及最终的级联分类器误检率 F_obj
(2)P = 目标训练样本,N = 非目标训练样本,F_0 = 1.0, D_0 = 1.0, i = 0
(3)F_i > F_obj 时,执行循环:
a) i =i +1
b) n_i= 0 , F_i = F_i-1
c) F_i > f * F_i-1 时,执行循环:
i) n_i = n_i + 1
ii) 利用Adaboost算法训练P和N上具有 n_i 个特征的强分类器
iii) 计算当前级联分类器的检测率 D_i 和 F_i
iv) 降低第 i 级强分类器阈值知道当前级联分类器检测率达到 d * D_i-1
d) N = 空集
e) 如果F_i > F_obj,用当前的级联分类器检测非目标图像,将误识别的图像放入集合N,进行Bootstrap过程。(Bootstrap是从离线样本集合向训练样本集合中补充训练样本,形成动态训练集,将正确分类的负样本直接丢弃,错误分类的负样本送入下一级,随着训练进行,负样本难度不断增加)
(4)输出满足要求的分类器
【使用级联分类器进行检测】
检测窗扫描整幅图像。为了提高检测速度,应该尽早丢弃容易判别的非目标区域,训练时给每一个弱分类器设置一个拒绝阈值,如果样本累计输出大于阈值则送入下一级继续分类,否则就直接标记为负样本区域
首先第一个分类器的输入是所有的子窗口,然后通过级联的分类器去除掉一些子窗口,这样能够有效地降低窗口的数目,具体的去除方法就是如果任何一个级联分类器提出拒绝,那么后续的分类器就不需要处理之前分类器的子窗口。
通过这样的一种机制能够有效地去掉较多的子窗口,因为较大部分的子窗口中都没有所要检测的物体。
2、基于随机几何模型的遥感目标检测
有一类遥感人造地物目标结构相对复杂但是几何部件特性相对单一,可以使用基于随机几何理论的建模方法,通过对目标及其组件的组合式建模对物体形状位置等随机变化特征进行统计分析。
目标部件结构:提出可变形模板,用若干几何图形来拟合目标的轮廓。
【点过程】
描述随机点分布的随机过程。很多随机现象发生的时刻、地点、状态等往往可以用某一空间上的点来表示。例如,服务台前顾客的到来时刻,真空管阴极电子的发射时刻,可表为实轴上的点。又如,天空中某一区域内星体的分布,核医疗中放射性示踪物质在人体器官的各处出现,不同能级地震的发生,都可用二维以上空间的点表示。点过程就是描述这类现象的理想化的数学模型。它在随机服务系统、交通运输、物理学和地球物理学、生态学、神经生理学、传染病学、信息传输、核医疗学等很多方面都有应用。
对于X的点过程是从一个概率空间到(N,N)的一个可度量映射N。N是最小域可数子集。
【标值点过程】
标值点过程(marked pointprocess)一种点过程。令点过程的每一点联系一个标值,就得到标值点过程。设{N(t),t}是一基本的点过程,如果对这过程的每一点t�(n=1,2,3,...)赋予一个辅助的随机变量u�,并称之为联系于该点的标值,变量u随机地取值于某一标值空间au,这种每一点都带有一个标值的点过程即称为标值点过程。
标值点过程用于目标提取,主要有两个优势,一、该方法是一种面向对象的方法二、该方法是基于统计框架的。
从像素到对象
传统的道路提取的方法一般是建立在基于像素级别的光谱信息分析的基础上,它们的共同特征是主要使用图像的强度量即灰度值的统汁信息,而对地物形状、结构等信息的分析很少涉及。在高分辨率图像中,道路表现为具有一定的宽度的“面状物”,具有丰富的细节信息,并存在较多的噪声干扰车辆、树木、阴影等,使用像素级方法一般很难得到较好的提取结果。面向对象的思想来源于软件工程领域,其特点是将影像对象作为影像分析的基本单元。影像对象是指影像分割后若干“同质”像素的集合。在很多特征信息提取的问题中,能够完整表现目标特征的并非单个像元,而是那些“同质”像素的集合,因此,基于对象的分析方法更符合实际情况,能更好地利用目标的特征。采用面向对象的方法有以下优势一、可以较好的解决噪声问题,噪声区域将和其周边的像元一起合并到特定的影像对象中去二、可充分利用目标的几何结构特征长、宽等和光谱特征方差、均值等三、可充分利用目标的空间特征距离、方向等,使专家知识能直接指导图像分析。基于标值点过程提取目标的方法是一种面向对象的方法。这种方法根据对象的几何特征建立模型,根据目标的光谱特性建立数据项,根据目标的拓扑性质等空间特性建立先验项。
统计方法
标值点过程的方法克服了MRF的不足。它从对象的角度建立目标的模型,每个标值点可以表示复杂的结构,可以较好的解决噪声问题。而且,这种方法可以通过定义标值点之间的相互关系来描述目标形状和全局结构。
3、基于主题语义模型的遥感目标提取
融合了检测和分割两个过程。首先通过多尺度分割,在大尺度图像上定位感兴趣目标所在的区域,然后利用“最优语义标记结果”的自动选择分割提取目标的精确轮廓。
将图像比作文本,将图像中存在的目标比作文本主题,不同目标对应不同的主题,图像即为不同模型的混合体。下面的方法首先对图像进行多尺度分割,获取图像中各类目标以及其背景在各个尺度上的分割结果,然后自动提取特征,并且结合主题语义模型,对图像各个尺度中包含的先验知识和相互关系进行定量计算。
【分水岭分割】
利用分水岭进行图像分割的方法。它是一种区域分割法,区域分割法利用图像的空间性质,以像素点之间的相似性为依据,根据不同的分割准则进行图像分割。这样能弥补阈值、边缘检测、轮廓检测中忽略像素点空间关系的缺点。分水岭分割是基于自然的启发算法来模拟水流通过地形起伏的现象从而研究总结出来的一种分割方法,其基本原理是将图像特征看作地理上的地貌特征,利用像素的灰度值分布特征,对每个符合特征的区域进行划分,形成边界以构成分水岭。下面是分水岭算法的物理模型:

在上面的水岭算法示意图中局部极小值、积水盆地,分水岭线以及水坝的概念可以描述为:
(1)区域极小值:导数为0的点,局部范围内的最小值点;
(2)集水盆(汇水盆地):当“水”落到汇水盆地时,“水”会自然而然地流到汇水盆地中的区域极小值点处。每一个汇水盆地中有且仅有一个区域极小值点;集水盆地就是要识别的物体区域
(3)分水岭:当“水”处于分水岭的位置时,会等概率地流向多个与它相邻的汇水盆地中;
(4)水坝:人为修建的分水岭,防止相邻汇水盆地之间的“水”互相交汇影响。
分水岭算法最大的不足在于过分割现象,为此在分割之前利用非线性滤波算法对原始图像进行去噪和平滑,之后对分割后的结果图像进行多尺度区域合并算法进行合并。
【目标候选区域的生成】
首先通过图像的多尺度分割对训练图像在不同尺度下进行不同分割数目的划分,把图像表现为图像块的集合。之后对过小区域进行合并。合并准则的主要依据是图像的光谱和形状信息。

合并的具体步骤为:
(1)从初始结果得到区域的邻接图(RAG)
(2)计算初始分割中最小的区域面积定义为C_min
(3)挑选出所有面积为C_min的区域,并根据邻接图找出相邻区域,弱=如果区域为孤立区域,邻域区域为包含区域
(4)计算被挑选出的区域与邻接区域的同质性度量值(合并准则),保存具有最小同质性值的区域对
(5)合并上一步中的区域对
(6)重新计算邻接图(RAG),计算合并后新图像的C_min
(7)如果新图像C_min大于阈值则输出结果,否则返回(3)
【特征提取】
总希望提取简单而稳定的特征。主要包括Harris-Affine特征和MSER特征
【Harris角点】
在现实世界中,角点对应于物体的拐角,道路的十字路口、丁字路口等。从图像分析的角度来定义角点可以有以下两种定义:1)角点可以是两个边缘的角点;2)角点是邻域内具有两个主方向的特征点;
人眼对角点的识别通常是在一个局部的小区域或小窗口完成的。如果在各个方向上移动这个特征的小窗口,窗口内区域的灰度发生了较大的变化,那么就认为在窗口内遇到了角点。如果这个特定的窗口在图像各个方向上移动时,窗口内图像的灰度没有发生变化,那么窗口内就不存在角点;如果窗口在某一个方向移动时,窗口内图像的灰度发生了较大的变化,而在另一些方向上没有发生变化,那么,窗口内的图像可能就是一条直线的线段。
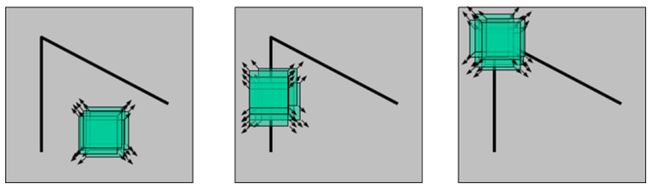
对于图像I(x,y),当在点(x,y)处平移(Δx,Δy)后的自相似性,可以通过自相关函数给出:
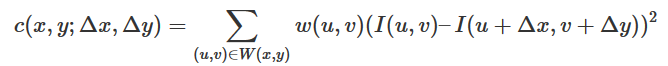

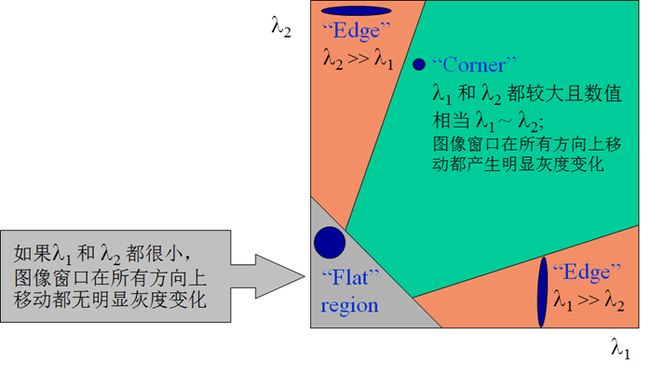
椭圆函数特征值与图像中的角点、直线(边缘)和平面之间的关系如下图所示。共可分为三种情况:
图像中的直线。一个特征值大,另一个特征值小,λ1≫λ2或λ2≫λ1。自相关函数值在某一方向上大,在其他方向上小。
图像中的平面。两个特征值都小,且近似相等;自相关函数数值在各个方向上都小。
图像中的角点。两个特征值都大,且近似相等,自相关函数在所有方向都增大。
根据二次项函数特征值的计算公式,我们可以求M(x,y)矩阵的特征值。但是Harris给出的角点差别方法并不需要计算具体的特征值,而是计算一个角点响应值R来判断角点。R的计算公式为:
式中,detM为矩阵M的行列式;traceM为矩阵M的直迹;α为经常常数,取值范围为0.04~0.06。事实上,特征是隐含在detM和traceM中,因为,

可以将Harris图像角点检测算法归纳如下,共分以下五步:

Harris角点检测算子对亮度和对比度的变化不敏感,具有旋转不变性,不具有尺度不变性
Harris角点检测虽然对于光照强度、旋转角度改变具有较好的检测不变性,但是却不具有尺度不变性及仿射不变性,然后在现实生活中,两张图片中目标物体发生尺度变化,或由视点变化而引起仿射变化是非常常见的。为了获得尺度不变性,比较直观的方法就是建立多尺度空间(类似于sift方法),对于每个特征位置都有在不同尺度下的表示,那么在匹配时只要找到对应尺度空间下的特征点就可以了。所以我们只需要在经典的方法里引入多尺度空间,在原特征点空间里增加了多个其他尺度空间的特征点,这些增加的特征点对应于不同的尺度空间的图像,增加了目标尺度变化的鲁棒性,使其具有了一定程度的尺度不变性。
【MSER特征】
MSER(最稳定极值区域)基于分水岭的概念:对图像进行二值化,二值化阈值取[0, 255],这样二值化图像就经历一个从全黑到全白的过程(就像水位不断上升的俯瞰图)。在这个过程中,有些连通区域面积随阈值上升的变化很小,这种区域就叫MSER。
如把灰度图看成高低起伏的地形图,其中灰度值看成海平面高度的话,MSER的作用就是在灰度图中找到符合条件的坑洼。条件为坑的最小高度,坑的大小,坑的倾斜程度,坑中如果已有小坑时大坑与小坑的变化率。

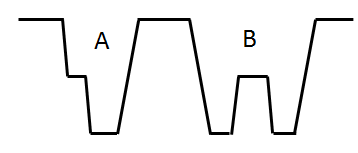
以上便是对坑的举例,MSER主要流程就三部分组成:
1.预处理数据
2.遍历灰度图
3.判断一个区域(坑洼)是否满足条件
简单来说,就如将水注入这个地形中。水遇到低处就往低处流,如果没有低处了,水位就会一点点增长,直至淹没整个地形。在之前预处理下数据,在水位提高时判断下是否满足条件。
【主题语义建模】
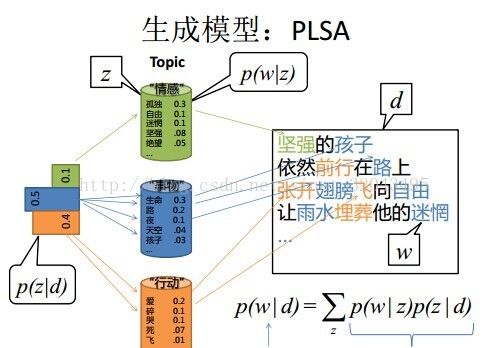
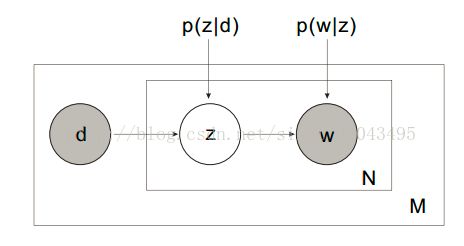
可以采用pLSA模型分析每个候选区域包含的特征信息。图像候选区域视为文档(document),待分割提取的目标为文档主题(topic),候选区域包含的特征就是文档中的单词(word)。
用pLSA模型统计图像上的特征分布,而后拟合成若干个已知的主题类别的混合。对于每幅图像,计算得到原始图像的特征描述子后按照不同尺度不同的划分规则分配给每个候选区域,这样不同尺度的候选区域就包含数量不同和各种类别的特征描述子,用特征描述子的直方图形式表达候选区域信息。
【pLSA】
1.词袋模型
词袋模型(BOW, Bag-of-Words) 模型是NLP领域中的一个基本假设,一个文档(document)被表示为一组单词(word/term)的无序组合,而忽略了语法或者词序的部分,存在缺陷:
稀疏性: 对于大词典,尤其是包括了生僻字的词典,文档稀疏性不可避免;
多义词: BOW模型只统计单词出现的次数,而忽略了一个词可能存在多种含义,一词多义;
同义词(Synonym): 多个单词可以表示同一个意思,一义多词;
从同义词和多义词问题可以看到:单词也许不是文档的最基本组成元素,在单词与文档之间还有一层隐含的关系,我们称之为主题(Topic),我们更关注隐藏在词之后的意义和概念。在写文章时首先确定的是文章的主题,再根据主题选择合适的单词来表达观点。在BOW模型中引入Topic的因素,即潜在语义分析(LSA, Latent SemanticAnalysis)和概率潜在语义分析(pLSA,probabilistic Latent Semantic Analysis)
2.LSA模型
LSA的基本思想就是,将document从稀疏的高维Vocabulary空间映射到一个低维的向量空间,我们称之为隐含语义空间(Latent Semantic Space).
具体说来就是对一个大型的文档集合使用一个合理的维度建模,并将词和文档都表示到该空间,比如有2000个文档,包含7000个索引词,LSA使用一个维度为100的向量空间将文档和词表示到该空间,进而在该空间进行信息检索。
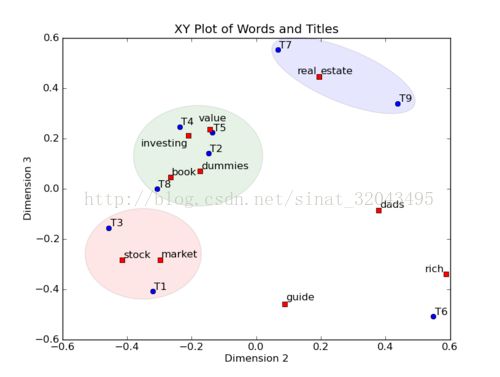
在图上,每一个圆圈表示一个主题,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说 stock 和 market 可以放在一类,因为他们老是出现在一起,real 和 estate 可以放在一类,dads,guide 这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,在某个主题下,会有多个文档和多个单词。
而将文档表示到此空间的过程就是SVD奇异值分解和降维的过程。降维是LSA分析中最重要的一步,通过降维,去除了文档中的“噪音”,也就是无关信息(比如词的误用或不相关的词偶尔出现在一起),语义结构逐渐呈现。

每个奇异值对应的是每个“语义”维度的权重,将不太重要的权重置为0,只保留最重要的维度信息,去掉一些信息“nosie”,因而可以得到文档的一种更优表示形式。理解:矩阵 U 中的每一列表示一个关键词,每个key word与各个词的相关性,数值越大越相关;矩阵 V 中的每一行表示一类主题,其中的每个非零元素表示一个主题与一个文档的相关性。中间的矩阵 D 则表示文章主题和keyword之间的相关性。因此,我们只要对关联矩阵 X 进行一次奇异值分解,我们就可以同时完成了近义词分类和文章的分类。(同时得到每个主题的相关性)。
LSA的优点
1)低维空间表示可以刻画同义词,同义词会对应着相同或相似的主题。
2)降维可去除部分噪声,是特征更鲁棒。
3)充分利用冗余数据。
4)无监督/完全自动化。
5)与语言无关。
LSA的缺点
LSA可以处理向量空间模型无法解决的一义多词(synonymy)问题,但不能解决一词多义(polysemy)问题。因为LSA将每一个词映射为潜在语义空间中的一个点,也就是说一个词的多个意思在空间中对于的是同一个点,并没有被区分
3.PLSA模型
假设你要写M篇文档,由于一篇文档由各个不同的词组成,所以你需要确定每篇文档里每个位置上的词。再假定你一共有K个可选的主题,有V个可选的词,咱们来玩一个扔骰子的游戏。
1. 假设你每写一篇文档会制作一颗K面的“文档-主题”骰子(扔此骰子能得到K个主题中的任意一个),和K个V面的“主题-词项” 骰子(每个骰子对应一个主题,K个骰子对应之前的K个主题,且骰子的每一面对应要选择的词项,V个面对应着V个可选的词)。
比如可令K=3,即制作1个含有3个主题的“文档-主题”骰子,这3个主题可以是:教育、经济、交通。然后令V =
3,制作3个有着3面的“主题-词项”骰子,其中,教育主题骰子的3个面上的词可以是:大学、老师、课程,经济主题骰子的3个面上的词可以是:市场、企业、金融,交通主题骰子的3个面上的词可以是:高铁、汽车、飞机。
2. 每写一个词,先扔该“文档-主题”骰子选择主题,得到主题的结果后,使用和主题结果对应的那颗“主题-词项”骰子,扔该骰子选择要写的词。 {每篇文档有不同的文档-主题 骰子}
先扔“文档-主题”的骰子,假设(以一定的概率)得到的主题是教育,所以下一步便是扔教育主题筛子,(以一定的概率)得到教育主题筛子对应的某个词:大学。
上面这个投骰子产生词的过程简化下便是:“先以一定的概率选取主题,再以一定的概率选取词”。事实上,一开始可供选择的主题有3个:教育、经济、交通,那为何偏偏选取教育这个主题呢?其实是随机选取的,只是这个随机遵循一定的概率分布。比如3个主题的概率分布是{教育:0.5,经济:0.3,交通:0.2}, 我们把各个主题z在文档d中出现的概率分布称之为主题分布,且是一个多项分布。
同样的,从主题分布中随机抽取出教育主题后,依然面对着3个词:大学、老师、课程,这3个词都可能被选中,但它们被选中的概率也是不一样的。比如3个词的概率分布是{大学:0.5,老师:0.3,课程:0.2},我们把各个词语w在主题z下出现的概率分布称之为词分布,这个词分布也是一个多项分布。
所以,选主题和选词都是两个随机的过程,先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
3. 最后,你不停的重复扔“文档-主题”骰子和”主题-词项“骰子,重复N次(产生N个词),完成一篇文档,重复这产生一篇文档的方法M次,则完成M篇文档。

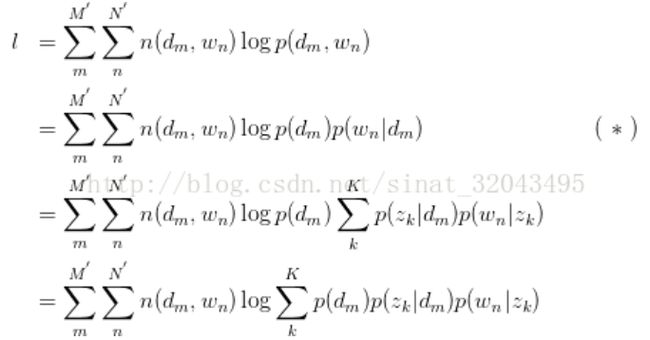

4、在训练图像上的应用
假设存在M个文档(样本候选区域),对应N个词汇(特征)分布,n(s_i,f_i)表示候选区域s_i 中特征f_i出现的次数,而隐含目标类别变量t_g与单个特征在特定区域中的出现概率相关联。隐含概率语义模型的目的是学习P(f_i | t_g)和P(t_g|s_i),求得模型参数后对各个图层中待标记区域求解对应标记的概率,概率值P(t_g|s_i)越大说明该位置属于目标的可能性越大
【分割区域语义判定】
经过对测试图像的多尺度分割和特征提取与描述,再根据生成的主题和单词的对应关系,计算各个候选区域与各个主题的相似度。最后选择合适的主题作为该候选主题的所属主题,实现图像目标的分割。
基于KL距离的语义相关函数,对层次之间的不同候选区域的语义关系进行定量分析,并确定图像块的语义属性。
1、KL距离
是Kullback-Leibler差异(Kullback-Leibler Divergence)的简称,也叫做相对熵(Relative Entropy)。它衡量的是相同事件空间里的两个概率分布的差异情况。其物理意义是:在相同事件空间里,概率分布P(x)对应的每个事件,若用概率分布Q(x)编码时,平均每个基本事件(符号)编码长度增加了多少比特。我们用D(P||Q)表示KL距离,计算公式如下:
概率分布P(X)的信息熵为:
利用KL距离计算图像区域和词统计模型之间的差异,进而统计候选区域的语义相关系数向量,进行候选区域的语义相关系数向量,进行候选区域的语义分析,最终确定候选区域的语义属性。
第l个图像在词空间向量的表示为P_l(x),第k个主题的词分布记作Q_k(x)。图像区域和主题之间的KL距离为
根据KL距离定义的语义相关系数为依据,计算出语义属性,将语义属性和阈值进行比较,得到目标提取的结果
引用参考
Adaboost算法
向前分步算法和提升树
Haar特征1
Haar特征2
分水岭算法
Harris角点检测
Harris角点PPT
尺度及仿射不变的Harris角特征点检测及匹配算法
MSER最稳定极值区域