目前比较好的开源音频降噪方法,一是speex,另外一个就是webrtc中的NoiseSuppression模块。speex是一个强大点音频处理工具,除了包含speex编解码外还有对于音频效果处理回声消除、自动增益与噪声抑制。WebRTC的强大自不必提,自从Google开源gips的音频处理技术后,很多做实时通讯的公司都在使用WebRTC的VoiceEngine做音频处理。VoiceEngine本是对于实时音视频通讯而设计的,但也可以摘取其中near end的一些处理应用到直播的推流端来优化音频效果,增加音频的体验,比如降噪,解决环境音较重问题;比如自动增益,解决主播离手机或其他直播设备较远(还处于近场)时采集到声音较小的问题。
APM(Audio Preprocessing Module)为VoiceEngine层级的音频处理模块,本文介绍了在直播推流中如何使用APM进行音频降噪,并对降噪效果进行了简单分析
一. 介绍
进入正题前先简单了解下WebRTC的结构,WebRTC由语音引擎,视频引擎和网络传输三大模块组成,其中语音引擎是WebRTC中最具价值的技术之一。

语音引擎的一般工作流程如下:
- 发起端进行音频采集;
- 采集到的音频数据进行回声消除,噪音抑制,自动增益控制处理;
- 音频编码;
- 通过网路传输到接收端;
- 到达接收端,先进入NetEQ模块进行抖动消除,丢包隐藏解码等操作;
- 将处理过后的音频数据送入声卡设备进行播放。

降噪NS模块(NoiseSuppression),是VoiceEngine中一个关键的语音信号处理组件。在 VOIP 语音通信过程中,来自周围环境和传输媒介引入的噪声、通信设备内部电噪声乃至其它讲话者的干扰不可避免地会对正常语音通信产生影响。这些干扰使接收端接收到的语音成为受噪声污染的带噪语音信号。从带噪语音信号中最大限度提取纯净的原始语音是噪声抑制的主要目标。
二. APM集成说明
2.1 提取编译APM
WebRTC源码链接https://chromium.googlesource.com/external/webrtc/
APM模块的提取与编译可以参考这篇文章,不过版本略旧,模块与新版本略有区别。大家可以同步最新版本进行测试,以下为使用较新版本提取出的apm文件结构

提取编译完成后,我们看一下APM的主要接口文件/webrtc/modules/audio_processing/include/audio_processing.h,APM提供了简单易用的接口,将AEC、AGC、VAD、NS等模块都包含在一个处理接口中,audio_processing.h中包含所有需要的接口,调用一个process接口即可实现所有音频处理功能,但同样因为如此,想将某一块功能剥离出来也比较麻烦。audio_processing.h注释写的也很详细,不过在代码更新的时候注释没有相应的更新,有些接口已经废弃,网上大多数的对调用流程的说明还是停留在旧版本的注释上。下面通过噪音抑制模块的使用,来说明APM对音频的处理流程以及可能会遇到的一些坑。
2.2 APM关键数据结构说明
2.2.1 整型格式pcm与浮点格式pcm
APM中的接口根据输入数据格式不同分为两类,int16 interfaces 与 float interfaces。
- 整型格式PCM,现在终端用户用的最多的,是16位的整数,音乐制作方用的最多的,是24位的整数。人听力的动态范围大约有85dB,16位整数有65536个不同的取值,动态区间是96dB。 如果能够完全利用起来,其实已经足以满足人类对动态范围的需求。但整数格式的数字信号处理,不可避免的会产生误差,在只利用8,9位整数的情况下,产生1位的误差就会产生-50dB左右的噪音,如果误差更大,噪音就更明显。
- 使用浮点格式来保存音频数据,对于正确还原声音动态以及减小音效处理时产生的误差是十分有利的。但浮点运算的复杂度,要远远大于整数运算的复杂度,而且浮点格式在播放的时候还是需要把浮点数转化为整数,才能进行数模转换,而得到扬声器能够播放的模拟信号。
考虑到终端采集到的pcm为整型格式,如果使用浮点格式处理,还需要经过两次转换,而且浮点处理会增加cpu消耗(这点没有测试...),所以最后使用了int16的接口进行降噪。
2.2.2 AudioFrame类
在VoiceEngine擎中,进行音频数据操作的基本单位为 AudioFrame。主要成员变量如下:
int id_;
// RTP timestamp of the first sample in the AudioFrame.
uint32_ttimestamp_;
// Time since the first frame in milliseconds.
// -1 represents an uninitialized value.
int64_telapsed_time_ms_;
// NTP time of the estimated capture time in local timebase in milliseconds.
// -1 represents an uninitialized value.
int64_tntp_time_ms_;
int16_tdata_[kMaxDataSizeSamples];
size_tsamples_per_channel_;
intsample_rate_hz_;
size_tnum_channels_;
SpeechTypespeech_type_;
VADActivityvad_activity_;
boolinterleaved_;
其中:
- id_ :记录的是这个 AudioFrame 对应的 channelId,即属于哪个与会者终端。
- timestamp_ :用于编解码。
- data_ :存放待处理的音频帧
- samples_per_channel_ :每个声道包含的采样数
- sample_rate_hz_ :采样频率。每一种编解码方式都有对应的采样频率。另外目前降噪支持8K、16K、32K、48K
- num_channels_ :音频采样声道数。
- speech_type_ :音频数据类型。此处是一个枚举变量,类型有 kNormalSpeech,kPLC,kCNG,kPLCCNG,kUndefined。
- vad_activity_:同样是一个枚举变量,表示的是经过静音检测后该 AudioFrame 对应的类型。
2.3 调用流程
APM操作两个一帧接一帧的音频流。一个主流,一个逆向流。所有的处理都将被应用到主流的帧,这些帧通过ProcessStream函数传递过去。逆向流的帧被一些组件拿去分析,逆向流的帧通过AnalyzeReverseStream函数传递过去。这里作为推流端没有逆向流,只有主流,将采集到的音频数据输入就可以了。
组件接口遵循类似的模式设计,通过APM中相应的getter函数访问。 所有的组件在创建时默认都是不可用的。启用一个组件,新的设置将会被应用到APM。启用组件会触发内存分配和初始化,以允许这个组件开始处理音频流。 基于下面的假设,提供了线程安全,用以减少锁的开销:
- 在ProcessStream的时候,流的getter和setters方法应该在同一个线程被调用。更确切的说,流的方法绝对不能在ProcessStream的同时被调用。
- 参数的getter和setter绝不能同时调用。
2.3.1 使用示例
APM描述降噪相关接口如下:
1. 创建APM实例,AudioProcessing::Create()
为需要处理的每个主流使用一个实例。 在客户端,这通常是near-end流的一个实例,以及需要处理的每个远端流的附加实例。 在服务器端,这通常是每个传入流的一个实例。也可以调用带参构造函数,传递一些配置项。
2. 创建AudioFrame实例
设置 sample_rate_hz_、num_channels_、samples_per_channel_
3. 启用噪音抑制组件,设置降噪等级
apm->noise_suppression()->set_level(kVeryHigh);
apm->noise_suppression()->Enable(true);
4. 处理音频数据
apm->ProcessStream(capture_frame);
5. 结束app,删除amp
// Close the application... delete apm;
2.4 多采样率适配
// APM accepts only linear PCM audio data in chunks of 10 ms. The int16
// interfaces use interleaved data, while the float interfaces use deinterleaved data.
// The int16 interfaces require: only |NativeRate|s be used.
// The float interfaces accept arbitrary rates.
APM仅能接受以10ms长度的线性pcm音频数据,对于16bit pcm,降噪只能支持NativeRate中测采样率,即8k、16k、32、48k,回声消除、自动增益也同样如此。对于32位或64位浮点数pcm可以支持输入任意采样率且去交错的多声道pcm。
enum NativeRate {
kSampleRate8kHz = 8000,
kSampleRate16kHz = 16000,
kSampleRate32kHz = 32000,
kSampleRate48kHz = 48000
};
从int16的接口ProcessStream的实现看,也对于其他的采样率也是不支持的
// Must be a native rate.
if (frame->sample_rate_hz_ != kSampleRate8kHz &&
frame->sample_rate_hz_ != kSampleRate16kHz &&
frame->sample_rate_hz_ != kSampleRate32kHz &&
frame->sample_rate_hz_ != kSampleRate48kHz) {
return kBadSampleRateError;
}
如果在这两处加上其他的采样率,处理结果也是有问题的,噪音降低但是会引入其它杂音。所以在需要处理其它采样率时有两种选择,一种是先进行重采样,转为支持的采样格式后再进行降噪;另一种是转换为浮点数格式,进行降噪处理,处理完成后再转换为16bit格式,因为目前浮点数格式只能转换成整数,才能进行数模转换,而得到扬声器能够播放的模拟信号。浮点数pcm能减小处理过程中的精度损失,但运算的复杂度,要远远大于整数运算的复杂度,处理过程cpu的消耗也会更大。
三. 降噪效果分析
APM集成好了,现在来测试下效果。我们使用audition进行分析。
3.1 直观感受
输入16000HZ 16bit mono 音频数据观察降噪效果:


上图为降噪前,下图为降噪后,可以看出降噪前后对比比较明显,降噪后整体整体能量有所下降,音频较低处下降更为明显;实际感受降噪后环境噪音大幅度降低,但人声也会略有降低。
3.2 不同level降噪效果
采集48000HZ 16bit stereo音频数据,降噪有4个level(kLow、kModerate、kHigh、kVeryHigh)为方便对比,将采集到的音频数据存储到本地文件,从文件中读取数据依次使用没有level进行处理。
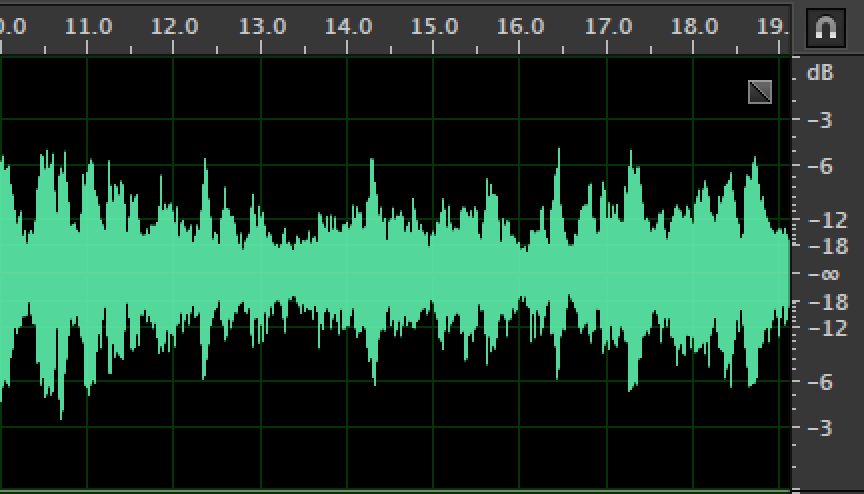


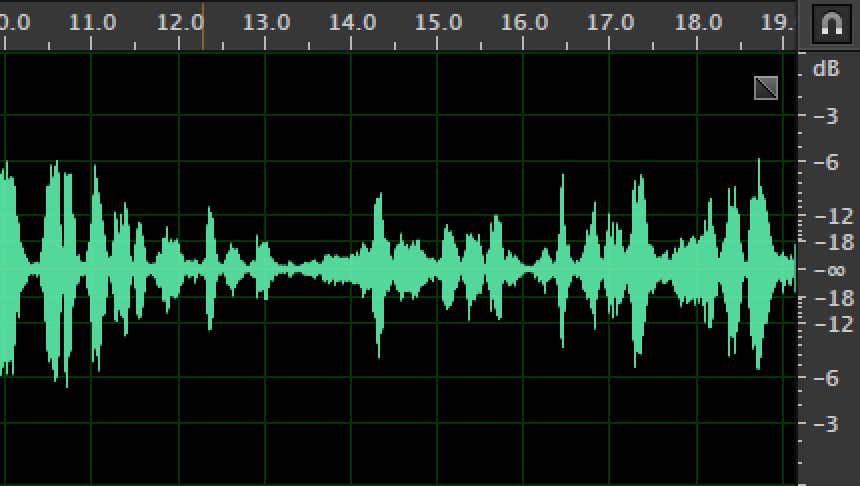

继续对比其他level的处理结果,发现随着level的提高,频域上较低的声音逐渐被消掉,噪音消的越来越干净,但level越高声音的细节也损失也越大,整体音量也有减小的趋势,实际用歌曲来测试发现立体声效果随level提高也越来越弱。
四. 总结
WebRTC的降噪效果不错,但降噪的同时对人声也会略有影响,所以还是要根据需要选择适合的降噪等级。
转载请注明:
作者金山视频云,首发 Jianshu.com
也欢迎大家使用我们的直播/短视频SDK,SDK已经支持APM的降噪功能。
- Android直播SDK(推流 + 播放):https://github.com/ksvc/KSYLive_Android
- iOS直播SDK(推流 + 播放):https://github.com/ksvc/KSYLive_iOS
有关音视频的更多精彩内容,请参考https://github.com/ksvc
视频云技术交流群(QQ):574179720。