在NODE中,应用需要处理网络协议、操作系统数据库、处理图片、接受上传文件等,在网络流和文件的操作中,需要处理大量的二进制数据,JavaScript自有的字符串不能满足这些需求,所以引入Buffer对象。
ECMAScript规范中,没有二进制方面的定义,CommonJS中有部分定义。
Buffer 结构
Buffer是一个类似于Array的对象,但它主要用来操作字节。
Buffer模块结构
Buffer是一个典型的JavaScript与C++结合的模块,它将性能相关部分用C++实现,将非性能相关部分用JavaScript实现
Buffer所占用的内存不是通过V8分配的,属于对外内存,由于V8垃圾回收性能的影响,将常用的操作对象用更高效和专有的内存分配回收策略来管理是个不错的方式。
由于Buffer在Node中应用太过常见,Node在进程启动就已经加载并放在全局对象global中,所以在使用Buffer时,无需通过require()即可直接使用
Buffer 对象
Buffer对象类似于数组,元素为16进制的两位数,既0到255 的数值
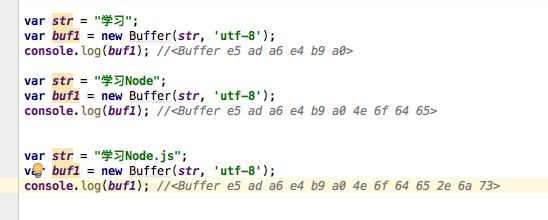
上面的列子可见,不同的编码字符占用的元素各不相同,上面代码中的中文字在UTF-8编码下占用3个元素,字母和标点字符占用一个元素。
Buffer可以访问length属性得到长度,可以通过下标访问元素
Buffer内存分配
Buffer对象的内存分配不是在V8的堆内存中,而是在Node的C++层面实现内存的申请的。
处理大量的字节数据不能采用需要一点内存就向操作系统申请一点内存的方式,这会造成大量内存申请的系统调用,对操作系统有一定得压力。Node在内存中使用上应用的是C++层面申请内存、在JavaScript中分配的策略。
为了高效地使用申请来的内存,Node采用了Slab分配机制。Slab是一种动态内存管理机制。
slab就是一块申请好的固定大小的内存区域。slab具有如下3种状态
full:完全分配状态。
partial:部分分配状态。
empty:没有被分配状态。
当我们需要一个Buffer对象可以使用 new Buffer(size)
Node以8KB为界限来区分Buffer是大对象还是小对象
Buffer.poolSize = 8 * 1024;
8KB的值也就是每个slab的大小值,在JavaScript层面,以它作为单位单元进行内存的分配
1.分配小Buffer对象
指定Buffer的大小小于8KB,Node会按照小对象的方式进行分配。Buffer的分配过程中主要使用一个局部变量pool作为中间处理对象,处于分配状态的slab单元都指向它。
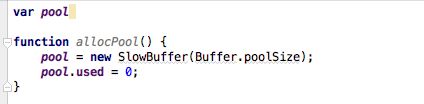
小Buffer分配会存在一个slab多个Buffer对象使用,只有这些小Buffer对象在作用域释放并都可以回收时,slab的8KB空间才会被回收。
2.分配大Buffer对象
如果需要超过8KB的Buffer对象,将会直接分配一个SlowBuffer对象作为slab单元,这个slab单元将会被这个大Buffer对象独占
this.parent = new SlowBuffer(this.length);
this.offset = 0;
Buffer 的转换
Buffer对象可以与字符串之间相互转换,目前支持的字符串编码类型有如下:
ASCII 、UTF-8、UTF-16LE/UCS-2、Base64、Binary、Hex
字符串转Buffer
字符串转Buferr主要在构造函数中完成 new Buffer(str, [encoding]);
encoding参数不传递时,默认按UTF-8编码进行转码和存储。
一个Buffer对象可以存储不同编码类型的字符串转码的值,调用write()方法可以实现该目的:
buf.write(string, [offset], [length], [encoding])
由于可以不断写入内容到Buffer对象中,并且每次写入可以指定编码,所以Buffer对象中可以存在多种编码转换后的内容,每次编码所有的字节长度不同,将Buffer反转回字符串时需要谨慎处理
Buffer 转字符串
but.toString([encoding], [ start], [end])
比较精巧的是,可以设置encoding(默认为UTF-8)、start、end这三个参数实现整体或局部的转换。如果Buffer对象由多种编码写入,就需要在局部指定不同的编码,才能转换回正常的编码
Buffer 不支持的编码类型
目前Node的Buffer对象支持的编码类型有限,只有少数的几种编码类型可以在字符串和Buffer之间转换。
Buffer.isEncoding(encoding)
可以使用第三方模块 iconv iconv-lite
Buffer的拼接
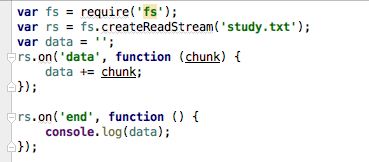
这里有个潜在的问题
data += chunk;
data = data.toString() + chunk.toString();
对于英文没什么问题,但对于宽字符会有问题,会出现乱码的问题。
每次读取的Buffer长度为4 - 》 "好好学习,天天向上。" -》好������习,������向上���
Buffer.toString()方法默认采用UTF-8编码
setEncoding() 与 string_decoder()
在调用setEncoding()时,可读流对象在内部设置了一个decoder对象。每次data事件都通过该decoder对象进行Buffer到字符串中解码,然后传递给调用者
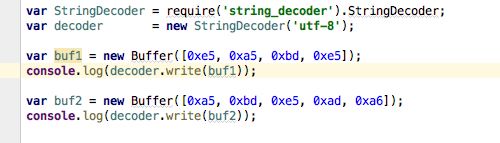
StringDecoder在得到编码后,知道宽字节字符串在UTF-8编码下是以3个字节的方式存储,所以第一次write()时,只取前面三个字节转码,后一个字节被保留在StringDecoder实例内部。第二次write()时,会将剩余的一个字节和后续的五个字节组合在一起,再次用3的整数倍字节进行转码。于是乱码问题被解决。
目前string_decoder模块能够处理的编码有 UTF-8,Base64和UCS-2/UTF-16LE这三种编码。
如果不是上述三种编码,采用的拼接方式为,用一个数组来存储接受到的所有Buffer片段并记录下所有片段的总长度,然后调用Buffer.concat()方法生成一个合并的Buffer对象。