慢查询:
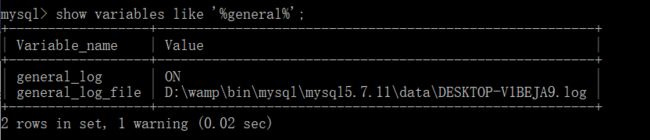
show variables like ‘%general%’;
通用日志是否开启和通用日志的位置
show variables like ‘%log_out%’;
日志记录的形式是数据表还是文件

show variables like ‘%query%’;
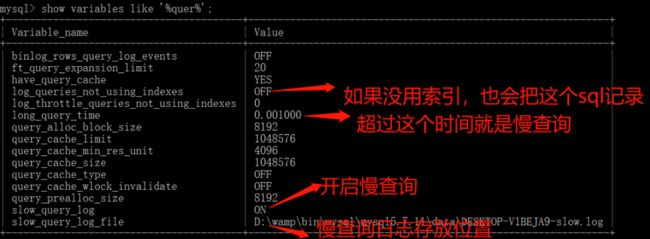
确认配置选项都是开启状态,我们模拟执行一条耗时量大的sql: select sleep(2)
在我们的日志中发现出现了新的纪录

explain:
显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句
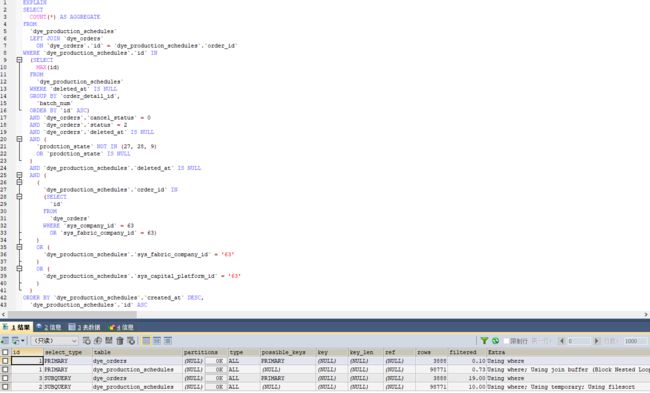
id:代表select 语句的编号, 如果是连接查询,表之间是平等关系, select 编号都是1,从1开始. 如果某select中有子查询,则编号递增.
select_type:查询类型
|--simple 它表示简单的select,没有union和子查询
|--primary 最外面的select,在有子查询的语句中,最外面的select查询就是primary,下图中就是这样
|--subquery 在where或者having子句中插入另一个sql
table:查询针对的表 有可能是实际表名或表的别名
type: 是指查询的方式, 非常重要,是分析”查数据过程”的重要依据 。从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL
|--const, system, null这3个分别指查询优化到常量级别, 甚至不需要查找时间.一般按照主键来查询时,易出现const,system或者直接查询某个表达式,不经过表时, 出现NULL
|--eq_ref是指,通过索引列,直接引用某1行数据,常见于连接查询中
|--ref意思是指 通过索引列,可以直接引用到某些数据行
|--range:意思是查询时,能根据索引做范围的扫描
|--index扫描所有的索引节点,相当于index_all
|--all:意味着从表的第1行,往后,逐行做全表扫描.,运气不好扫描到最后一行.
possible_key:可能用到的索引 注意:系统估计可能用的几个索引,但最终,只能用1个.
key :最终用的索引.
key_len:使用的索引的最大长度
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows: MYSQL认为必须检查的用来返回请求数据的行数
filtered:显示了通过条件过滤出的行数的百分比估计值。
extra:extra列中出现的信息一般不是太重要,但是还是有很多信息我们可以从这里面获取到:
|--using index:出现这个说明mysql使用了覆盖索引,避免访问了表的数据行,效率不错!
|--using where:这说明服务器在存储引擎收到行后将进行过滤。有些where中的条件会有属于索引的列,当它读取使用索引的时候,就会被过滤,所以会出现有些where语句并没有在extra列中出现using where这么一个说明。
|--using temporary:这意味着mysql对查询结果进行排序的时候使用了一张临时表。
|--using filesort:这个说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。
|--using join buffer:MySQL在完成某些join需求的时候(all row join/all index /scan join)为了减少参与join的“被驱动表”的读取次数以提高性能,需要使用到join buffer来协助完成join操作当join buffer 太小,MySQL不会将该buffer存入磁盘文件而是先将join buffer中的结果与需求join的表进行操作,然后清空join buffer中的数据,继续将剩余的结果集写入次buffer中,如此往复,这势必会造成被驱动表需要被多次读取,成倍增加IO访问,降低效率(执行计划中如果现实using join buffer)
show Profiles:
show Profiles :分析sql执行性能
查看mysql是否支持show profile

如果profiling是关闭的,可以set语句开启 set profiling=1;
show profiles语句查看当前sql的queryid

然后通过show profile for query qyeryID分析(获取指定查询的开销 )
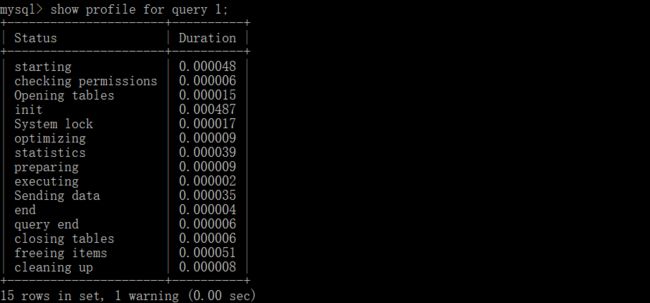
查看特定部分的开销,如下为CPU部分的开销
show profile block io,cpu for query 1;
show profile memory for query 1;