前两天有个朋友给我推荐了kaggle这个网站,感觉对于我这种想要学习却不太清楚如何实践的新手来说是个很有效的学习方式。
之前学的东西都比较乱,这边学一点,那边学一点,这次要一步一步的,从简到难好好搞一搞~
做这个的目的呢,主要是学习机器学习人工智能这方面的东西,通过具体的问题,把不同的算法放上去尝试,同时,也可以给想要学习的同学提供一些比较简单的方式~
之前看教程,感觉都是没有例子或者没有理论知识或者没有数据,或者理论知识讲的太专业,公式太多,有时候感觉很难下手,所以我还是通过这个系列把需要学的和做的都讲明白,让入门的人有一些良好的体验~
好了,废话不多说,开始正题
题目
连接:https://www.kaggle.com/c/titanic
这个问题大概的意思就是说,在泰坦尼克号撞冰山沉没的时候,由于没有足够的救生艇,导致不是所有人都能获救,虽然有幸运的成分在里面,但是有一部分群体获救的可能性更高,比如妇女小孩之类的人。你需要做的就是通过给定的数据,通过机器学习的方法,判断某个人是否能够生还。
简析
可以看出来这是一个二分类问题,所以我们需要一个分类器,我打算先用贝叶斯分类器搞一下,试试水,其实有其他的分类器,后面可以都试一试。
贝叶斯公式
首先可以看一下贝叶斯公式:
![[kaggle系列 一] 使用贝叶斯分类器判断是否能从泰坦尼克号生还_第1张图片](http://img.e-com-net.com/image/info10/e83a00a0b96b440982fa407f961b16bb.jpg)
换个姿势可能更好理解一些:
![[kaggle系列 一] 使用贝叶斯分类器判断是否能从泰坦尼克号生还_第2张图片](http://img.e-com-net.com/image/info10/3f9c83c2bb3f4e90a254eae08ab73106.jpg)
这里所谓的求解对象,其实就是你关注的信息而已,你也可以关注别的信息,让其他的信息成为求解对象。贝叶斯公式求概率大概可以理解为:我知道过去发生了一些事情,在一件我关注的信息(求解对象)出现的时候,还有其他一些信息或者说特征,现在我掌握了除求解对象以外的信息,我关注的求解对象发生的概率是多少?
下面说一个简单的例子,也是我面试碰到过的问题,大概意思是说,我有两个完全一样的盒子,第一个盒子里放了2个红球和2个白球,另一个盒子里放了3个红球和1个白球,现在我从某一个盒子里拿了一个球,发现是红球,那么这个红球来自第一个盒子里的概率是多少?
![[kaggle系列 一] 使用贝叶斯分类器判断是否能从泰坦尼克号生还_第3张图片](http://img.e-com-net.com/image/info10/c5d929fd93564cb28bd28cd066b9fa76.jpg)
我们定义:
P(A) = 从第一个盒子里取球的概率
P(B) = 取到红球的概率
根据前面的公式就可以算了,最后我们要求的就是
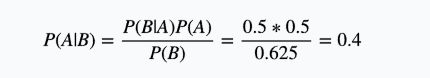
上面是贝叶斯公式简单的介绍,如果还是不太清楚就去找找别的教程吧~
贝叶斯分类器
那么贝叶斯分类器又是什么东西呢?结合我们要求解的问题,我们想要一个分类器,它的输入是乘客的各种信息(性别,年龄,舱位……),输出这个乘客是否生还。我们其实可以把乘客的信息作为输入信息,是否生还作为求解对象,根据给定训练数据,我们可以求出在某个信息下是否生还的概率和死亡的概率,取概率较大的那个,不就是一个分类器了吗?
假设我们有n个信息:
我们想要求解的对象就是是否存活,即:
利用贝叶斯公式,就有:

刚才也说了,我们要求生还概率和死亡概率两者中的较大值,两者中的分母是相同的,可以忽略,因此,我们要求的就是:
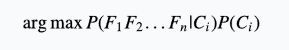
其中:

argmax 就是求最大值的坐标,这些值都可以算出来,我们就得到了一个贝叶斯分类器。
另外,虽然不需要求分母,但是我最开始写代码的时候是求了分母的,因为我想先算出个概率,然后比较一下谁比较大,但是我翻了个错误,是这样,当给定的n个事件都是互相独立的,那么就有:
但是,实际上对于这个问题,并不能用这个公式,因为事件并不是相互独立的,你可以想象当时我求出概率大于1时的懵逼心情,如果事件不是独立的,那么要求这个概率就要利用条件概率的链式法则了,这个公式比较麻烦,就不写了,有兴趣的可以去看看。
代码与结果
这是第一版代码,基本是完全按照公式写的,数据可以在前面给的链接里下到。
数据的格式大概是这样的:
![[kaggle系列 一] 使用贝叶斯分类器判断是否能从泰坦尼克号生还_第4张图片](http://img.e-com-net.com/image/info10/6401bfdede0840f38bf98ab3a6b767f2.jpg)
import csv
import os
def readData(fileName):
result = {}
with open(fileName,'rb') as f:
rows = csv.reader(f)
count = 0
for row in rows:
if result.has_key('attr_list'):
count += 1
for i in range(len(result['attr_list'])):
if not result.has_key(i):
result[i] = []
result[i].append(row[i])
else:
result['attr_list'] = row
return result
def writeData(fileName, data):
csvFile = open(fileName, 'w')
writer = csv.writer(csvFile)
n = len(data)
for i in range(n):
writer.writerow(data[i])
csvFile.close()
def calProb(data):
result = {}
for i in range(len(data['attr_list'])):
result[i] = {}
n = len(data[0])
for i in range(len(data['attr_list'])):
for j in range(n):
key = data[i][j]
if not result[i].has_key(key):
result[i][key] = 0;
result[i][key] += 1.0/n;
return result
def calCondiProb(data):
result = {}
n = len(data[0])
sum_n = 0
sum_n0 = 0
for i in range(n):
sum_n += float(data[1][i])
sum_n0 += 1 - float(data[1][i])
for i in range(2, len(data['attr_list'])):
result[i] = {}
for j in range(n):
key = data[i][j]
if not result[i].has_key(key):
result[i][key] = {0:0,1:0}
result[i][key][0] += (1 - float(data[1][j])) / sum_n0
result[i][key][1] += float(data[1][j]) / sum_n
return result
def calResult(P, CP, inputs,pos, n):
ignores = {0:True, 1:True,3:True,8:True,9:True,10:True}
pa0 = P[1]["0"]
pa1 = P[1]["1"]
pba0 = 1
pba1 = 1
for i in range(n):
if not ignores.has_key(i):
if CP[i].has_key(inputs[i- 1][pos]):
pba0 *= CP[i][inputs[i - 1][pos]][0]
pba1 *= CP[i][inputs[i - 1][pos]][1]
if (pba0*pa0 > pba1*pa1):
return inputs[0][pos],0
return inputs[0][pos],1
def run():
dataRoot = '../../kaggledata/titanic/'
data = readData(dataRoot + 'train.csv')
P = calProb(data)
CP = calCondiProb(data)
test_data = readData(dataRoot + 'test.csv')
n = len(test_data[0])
result_list = []
result_list.append([data['attr_list'][0], data['attr_list'][1]])
for i in range(n):
pid,suvived = calResult(P,CP, test_data, i, len(data['attr_list']))
result_list.append([pid, suvived])
writeData(dataRoot + 'result.csv', result_list)
run()
上面的代码跑出来的结果有0.74641的准确率,看起来一般般。
下面的代码用了开源机器学习框架scikit-learn,毕竟自己写公式造轮子很容易出错,用已经造好的就会方便很多,但是学习的过程写一写还是有助于理解的。这个版本又对原始数据做了一些处理,比如年龄这种需要原本的值,并且有些人没有年龄数据,我让他等于训练数据的平均值,其他的映射为一个数字了,然后有些可能对于是否生还没有太大影响的数据去掉了。并且这里用了贝叶斯公式的变种:高斯朴素贝叶斯公式,它的好处是对于像年龄这种连续的数据会处理的比较好一些。
可以在http://sklearn.lzjqsdd.com/modules/naive_bayes.html#gaussian-naive-bayes上看到其他公式,可以尝试一下。
import csv
import os
from sklearn.naive_bayes import GaussianNB
def readData(fileName):
result = {}
with open(fileName,'rb') as f:
rows = csv.reader(f)
for row in rows:
if result.has_key('attr_list'):
for i in range(len(result['attr_list'])):
key = result['attr_list'][i]
if not result.has_key(key):
result[key] = []
result[key].append(row[i])
else:
result['attr_list'] = row
return result
def writeData(fileName, data):
csvFile = open(fileName, 'w')
writer = csv.writer(csvFile)
n = len(data)
for i in range(n):
writer.writerow(data[i])
csvFile.close()
def convertData(dataList):
hashTable = {}
count = 0.0
for i in range(len(dataList)):
if not hashTable.has_key(dataList[i]):
hashTable[dataList[i]] = count
count += 1
dataList[i] = hashTable[dataList[i]]
def convertValueData(dataList):
sumValue = 0.0
count = 0
for i in range(len(dataList)):
if dataList[i] == "":
continue
sumValue += float(dataList[i])
count += 1
dataList[i] = float(dataList[i])
avg = sumValue / count
for i in range(len(dataList)):
if dataList[i] == "":
dataList[i] = avg
def dataPredeal(data):
convertValueData(data["Age"])
convertData(data["Fare"])
convertData(data["Pclass"])
convertData(data["Sex"])
convertData(data["SibSp"])
convertData(data["Parch"])
convertData(data["Embarked"])
def getX(data):
x = []
ignores = {"PassengerId":1, "Survived":1, "Name":1,"Ticket":1, "Cabin":1,"Fare":1,"Embarked":1}
for i in range(len(data["PassengerId"])):
x.append([])
for j in range(len(data["attr_list"])):
key = data["attr_list"][j]
if not ignores.has_key(key):
x[i].append(data[key][i])
return x
def getLabel(data):
label = []
for i in range(len(data["PassengerId"])):
label.append(int(data["Survived"][i]))
return label
def calResult(x,label, input_x):
bayes = GaussianNB().fit(x,label)
return bayes.predict(input_x)
def run():
dataRoot = '../../kaggledata/titanic/'
data = readData(dataRoot + 'train.csv')
test_data = readData(dataRoot + 'test.csv')
dataPredeal(data)
dataPredeal(test_data)
x = getX(data)
label = getLabel(data)
input_x = getX(test_data)
x_result = calResult(x, label,input_x)
res = [[test_data["PassengerId"][i], x_result[i]] for i in range(len(x_result))]
res.insert(0, ["PassengerId", "Survived"])
writeData(dataRoot + 'result.csv', res)
run()
这个版本的准确率可以达到0.77511,相比上一个提高了不少,不过在kaggle上的rank还是不算太高,后面可以用用别的分类器试试~