
文/Bruce.Liu1
文章大纲
- MySQL数据库升级
1.1. MySQL升级限制及方法
1.2. MySQL5.6升级、降级最佳实践- MySQL日志管理
2.1. Binary Log
2.2. Slow Query Log
2.3. General Log
2.4. redo log- MySQL表空间管理
3.1. 表空间概念
3.2. 共享表空间
3.3. 独立表空间
3.4. General Tablespace
3.5. Undo Tablespace(Log)
1.MySQL数据库升级
1.1.MySQL升级限制及方法
- MySQL升级的限制
MySQL数据库升级中不建议跨度版本太大的版本直接升级;如5.5升级到5.7这种方式是不支持的。
推荐升级的版本:
5.1 -> 5.5
5.5 -> 5.6
5.6 -> 5.7
详情参考:https://dev.mysql.com/doc/refman/5.7/en/upgrading.html
- MySQL升级的方法
替换更新:详情参考:https://dev.mysql.com/doc/refman/5.7/en/upgrading.html#upgrade-procedure-inplace
逻辑更新:详情参考:https://dev.mysql.com/doc/refman/5.7/en/upgrading.html#upgrade-procedure-logical
扩展知识:以上两种是官方提供的升级解决方案,这种方案在7x24的实时性较高的业务时,无疑是不可能的;但可以基于MySQL复制特性做"滚动升级"。
- MySQL降级的方法
降级操作:详情参考:https://dev.mysql.com/doc/refman/5.7/en/downgrading-to-previous-series.html
1.2.MySQL5.6升级、降级最佳实践
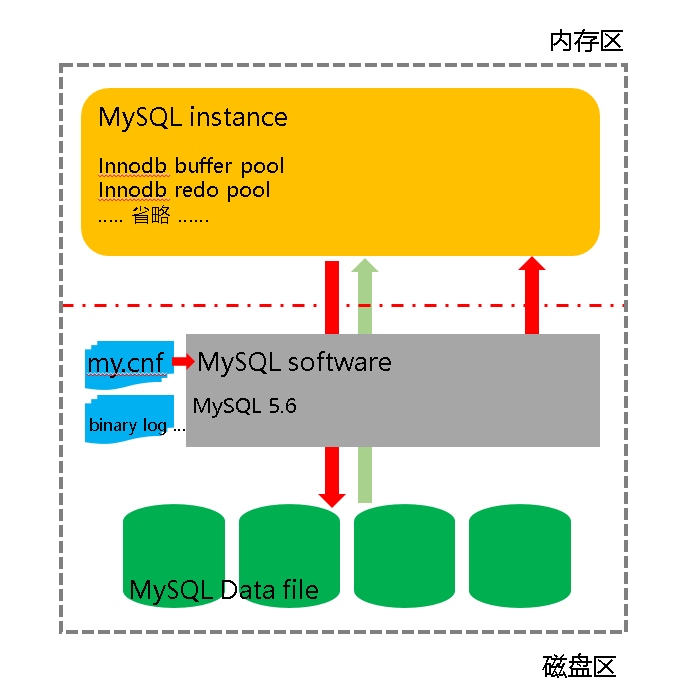
替换更新流程
- 将参数innodb_fast_shutdown禁用
- 关闭MySQL数据库
- 替换高版本的MySQL Server软件
- 检查参数兼容性
- 用高版本的软件挂在低版本的数据库并启动
- 升级数据库表结构(-s选项)
逻辑更新流程
- 创建目标端新版本数据库
- 将源端数据逻辑导出
- 导入目标端新版本数据库
DB降级流程
降级其实就是数据库升级的逆向操作,MySQL有解决方案但是不推荐,升级前先备份软件数据库即可。
2.MySQL日志管理
2.1.Binary Log
Binary Log也就是常说的bin-log,用于记录数据的变更历史变化,参数log_bin是生成的bin-log的文件名,后缀则是6位数字的编码,从000001开始,按照上面的配置,生成的文件则为"mysql_bin.000001";Binary Log还有一个重要的文件即:mysql_bin.index,它记录了Binary Log的顺序(手动清理Binary log时,改文件就不会及时更新,会造成潜在的风险)
Binary Log内容及作用
1.包含了所有更新了数据或者已经潜在更新了数据(比如没有匹配任何行的一个DELETE)
2.包含关于每个更新数据库(DML)的语句的执行时间信息
3.不包含没有修改任何数据的语句,如果需要启用该选项,需要开启通用日志功能
4.主要目的是尽可能的将数据库恢复到数据库故障点,因为二进制日志包含备份后进行的所有更新
5.用于在主复制服务器上记录所有将发送给从服务器的语句
6.启用该选项数据库性能降低1%,但保障数据库完整性,对于重要数据库值得以性能换完整。有些类似于Oracle开启归档模式。Binary Log特性
1.log-bin在未指定绝对路径的情形下,缺省位置保存在数据目录下。
2.若当前的日志大小达到max_binlog_size,则自动创建新的二进制日志。
3.对于大的事务,二进制日志会超过max_binlog_size设定的值。也即是事务仅仅写入一个二进制日志。(二进制日志文件大小接近,其size不是完全相等)
4.二进制日志文件会有一个对应二进制日志索引文件,该文件包含所有的二进制日志,其文件名与二进制日志相同,扩展名为mysql-bin.index
5.binary log切换的瞬间数据库中的变更是锁定状态,即数据库"挂起状态",binary log的存放地方应该放到一个快速的设备上。
6.Binary Log的切换至发生在以下情况:
6.1.数据库重启时
6.2.达到max_binlog_size值时
6.3.手动切换Binary log时(flush logs;)相关参数
| 参数 | 解释 |
|---|---|
| log_bin | 是否启动binlog |
| log_bin_index | 指定binlog的一个索引文件,默认是在datadir路径下的mysql-bin.index |
| binlog_do_db=comp | 只记录该数据库的binlog(不建议使用) |
| max_binlog_size=500M | 指定binlog的大小为500M一个文件,默认1G,建议是切换间隔在30分钟 |
| expire-logs-days=5 | 指定保留几天的binlog |
| binlog_format = row | 指定binlog日志格式,支持statement,row,mixed格式,推荐row格式 |
| binlog_row_image=full | 记录log的详细信息的相关程度 |
| binlog_error_action=abort_server | 当mysql不能写binlog时,抛出异常,默认是ignore_error不报错 |
| binlog_direct_non_transactional_updates=off | 对于非事务引擎,直接写日志,不走2pc提交,默认是不支持 |
| binlog_order_commit = on | 按顺序写入日志,和memcache API交互相关的参数(默认memcache写入不是顺序写) |
| binlog_cache_size = 1M | 该参数表示binlog使用内存大小,可以通过状态变量binlog_cache_use和binlog_cache_disk_use来帮助测试 |
- 最佳实践
示例一:binlog内容的查看
mysql> SHOW BINARY LOGS;
mysql> SHOW MASTER LOGS;
查看binlog中的内容(单位是events)
mysql> show binlog events;
mysql> show binlog events in '716210059-bin.000004';
重置所有binlog,慎操作
mysql> reset master;
示例二:binlog的清理
一般来说配置合理的expire-logs-days参数,mysql就能自动清理超过阈值的binary log,但这种方法也未必是万能的例如:抢购、双11、等重大节日,就会造成DB推挤的binary log过多,那么如何正确的清理binary log呢?
MySQL 提供了purge命令,可以基于日志也可以基于文件名purge。
mysql> help purge
...... 省略 ......
Examples:
PURGE BINARY LOGS TO 'mysql-bin.010';
PURGE BINARY LOGS BEFORE '2008-04-02 22:46:26';
强烈不建议手工清理binary log,那时会造成MySQL读取binlog时,发生以下错误:
ERROR 29 (HY000): File '/var/wd/db10059/716210059-bin.000001' not found (Errcode: 2 - No such file or directory)
2.2.Slow Query Log
顾名思义,慢查询日志中记录的是执行时间较长的query,也就是我们常说的slow query。
Slow Query Log作用
慢查询日志是将mysql服务器中影响数据库性能的相关SQL语句记录到日志文件,通过对这些特殊的SQL语句分析,改进以达到提高数据库性能的目的。相关参数
| 参数 | 解释 |
|---|---|
| slow_query_log | 是否开启慢查询日志 |
| slow_query_log_file | 慢查询日志文件名,默认是HOSTNAME-slow.log |
| long_query_time | 制定慢查询阈值, 单位是秒;记录大于该值,包括值本身 |
| log_queries_not_using_indexes | 将没有使用索引的SQL记录到慢查询日志 |
| log_throttle_queries_not_using_indexes | 限制每分钟内,在慢查询日志中,去记录没有使用索引的SQL语句的次数;版本需要>=5.6.X |
| min_examined_row_limit | 扫描记录少于改值的SQL不记录到慢查询日志 |
| log_slow_admin_statements | 记录超时的管理操作SQL到慢查询日志,比如ALTER/ANALYZE TABLE |
| log_output | 慢查询日志的格式,[ FILE | TABLE | NONE ],默认是FILE |
| log_slow_slave_statements | 复制节点从库上开启慢查询日志 |
| log_timestamps | 写入时区信息。可根据需求记录UTC时间或者服务器本地系统时间 |
- 最佳实践
示例一:验证slow query log
开启slow query log
session1:
mysql> set global slow_query_log=1;
Query OK, 0 rows affected (0.00 sec)
mysql> set global long_query_time=1;
Query OK, 0 rows affected (0.00 sec)
验证
session2:
# mysql
mysql> select sleep(1);
+----------+
| sleep(1) |
+----------+
| 0 |
+----------+
1 row in set (1.00 sec)
mysql> select sleep(1.5);
+------------+
| sleep(1.5) |
+------------+
| 0 |
+------------+
1 row in set (1.50 sec)
# tail -200 slow-queries.log
...... 省略 ......
# Time: 170822 16:18:33
# User@Host: root[root] @ localhost [] Id: 30
# Schema: Last_errno: 0 Killed: 0
# Query_time: 1.500188 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0 Rows_affected: 0
# Bytes_sent: 65
SET timestamp=1503389913;
select sleep(1.5);
示例二:slow query log存入表
mysql> set global log_output = 'TABLE';
Query OK, 0 rows affected (0.00 sec)
mysql> set global slow_query_log = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> alter table mysql.slow_log engine = MyISAM;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> set global slow_query_log = 1;
Query OK, 0 rows affected (0.00 sec)
建议 :使用TABLE的优势在于方便查询,但是数据库最小化运行原则,不建议使用TABLE方式存放slow query log。
2.3.General Log
常常遇到这样的问题:为了数据库技术研究以及程序排障,需要知道程序在数据库执行的每一个步骤;此时就需要用到general log,因为为了性能考虑,一般general log不会开启。s low log可以定位一些有性能问题的sql,而general log会记录所有的SQL。
General Log作用
1.当需要查找某条特定SQL语句,且该SQL语句执行较快,无法记录到slow_log中时,可以开启通用日志generic_log,进行全面记录, 可用于审计Audit
2.通用日志会记录所有操作,性能下降明显。所以如果需要审计,需要Audit Plugin
3.审计插件参考:https://mariadb.com/kb/en/mariadb/mariadb-audit-plugin/
软件下载地址:https://downloads.mariadb.com/Audit-Plugin/MariaDB-Audit-Plugin/相关参数
| 参数 | 解释 |
|---|---|
| general_log=OFF | 开启general log |
| general_log_file=general.log | general log路径,默认在datadir下 |
2.4.Redo Log
InnoDB有buffer pool(简称bp)。bp是数据库页面的缓存,对InnoDB的任何修改操作都会首先在bp的page上进行,然后这样的页面将被标记为dirty并被放到专门的flush list上,后续将由master thread或专门的刷脏线程阶段性的将这些页面写入磁盘(disk or ssd)。这样的好处是避免每次写操作都操作磁盘导致大量的随机IO,阶段性的刷脏可以将多次对页面的修改merge成一次IO操作,同时异步写入也降低了访问的时延。然而,如果在dirty page还未刷入磁盘时,server非正常关闭,这些修改操作将会丢失,如果写入操作正在进行,甚至会由于损坏数据文件导致数据库不可用。为了避免上述问题的发生,Innodb将所有对页面的修改操作写入一个专门的文件,并在数据库启动时从此文件进行恢复操作,这个文件就是redo log file。这样的技术推迟了bp页面的刷新,从而提升了数据库的吞吐,有效的降低了访问时延。带来的问题是额外的写redo log操作的开销(顺序IO,当然很快),以及数据库启动时恢复操作所需的时间。最后为大家总结一句话,所有的RDBMS中,都是日志先行的设计理念。
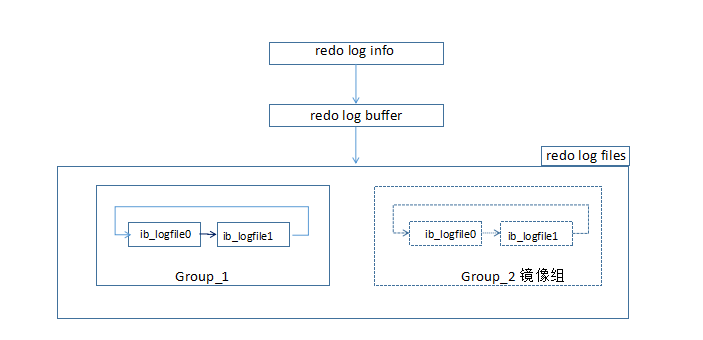
- redo log原理
- 内存中任何脏块变更产生的redo log info都会放入redo log buffer
- redo log buffer按照一定的规则阶段性的写入redo log files文件,在以下三种情况下,会将重做日志缓冲中的内容刷新到外部磁盘的重做日志文件中。
a) Master Thread 每一秒将重做日志缓冲刷新到重做日志文件;
b) 每个事务提交时会将重做日志缓冲刷新到重做日志文件;
c) 当重做日志缓冲池剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件。
而redo buffer写入redo log file的规则是:
- 顺序写redo log file
- 当redo log file写满时,覆盖循环写入。
- 相关参数
| 参数 | 解释 |
|---|---|
| innodb_log_file_size | redo log file大小 |
| innodb_log_files_in_group | redo log file 组数量 |
| innodb_log_group_home_dir | redo log 家目录,默认不写就是datadir |
| innodb_log_buffer_size | redo buffer大小 |
思考:innodb_log_file_size 和 innodb_log_buffer_size 越大越好吗?
注意:5.6.*之前redo大小,以及redo group数量是不能修改的。
3.MySQL表空间管理
3.1.表空间概念
对于innodb的数据结构,首先要解决两个概念性的问题: 共享表空间以及独占表空间。表空间的概念实际上是引擎层的,共享表空间以及独占表空间都是针对数据的存储方式而言的。只要在my.cnf里面增加innodb_file_per_table=1就可以从共享表空间切换到独立表空间。当然对于已经存在的表,则需要执行alter table table_name engine=innodb命令迁移数据。
定义:从逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,即:"表空间"
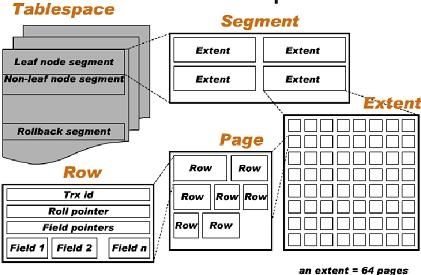
3.2.共享表空间
innodb_data_file_path参数配置的就是一个共享表空间,数据都往这一个文件里放,也就是ibdata1,共享表空间还包含:回滚(undo)信息、插入缓冲索引页、系统的事物信息、双写缓冲(Double write buffer)等。ibdata1会伴随时间、数据等因素持续增长,且无法收缩,这是共享表空间一直让人所诟病的问题。
优点
1.由于所有的数据都放在共享表空间所以文件数量相对很少,方便管理。
2.表空间可以分成多个文件存放到各个磁盘,所以表也就可以分成多个文件存放在磁盘上,用于提升IO性能。(现在的版本已经不支持该功能)缺点
1.所有的数据和索引存放到一个或多个文件中,但是多个表及索引在表空间中混合存储,当数据量非常大的时候。带来的性能会有下降。
2.正由于集中管理的方式,也间接导致了存储空间中有可能多个表数据存放在一起,此时如果一个pgae包含的多一个表对象都请求该page时,就会有锁的争抢。
3.共享表空间分配后的空间不能回收:当出现创建一个表的操作表空间扩大后,即使删除相关的表数据也没办法回缩那部分已分配的空间;这就是很多线上为什么MySQL ibdata*文件会变成几百G的原因。同时也会为物理备份的方式带来额外的负担。
注意:如果想回收共享表空间的大小,只能是逻辑导出,重建数据库,在导入!
- 最佳实践
实例一:共享表空间的使用
要求MySQL实例共享表空间方式启动(参数:innodb_file_per_table = 0)
mysql> create database share_tablespace;
Query OK, 1 row affected (0.01 sec)
mysql> create table t_share_innodb (id bigint,table_name varchar(10));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t_share_innodb (table_name) values ('t1');
Query OK, 1 row affected (0.06 sec)
mysql> insert into t_share_innodb (table_name) values ('t2');
Query OK, 1 row affected (0.00 sec)
没有生成ibd文件,说明就是使用共享表空间
mysql> system ls /data1/db3306/share_tablespace
db.opt t_share_innodb.frm
实例二:共享表空间的扩容
如果觉得一个共享表空间实在太大,担心影响性能,可以扩展多个共享表空间
# mysqladmin -S /data1/db3306/my3306.sock shutdown
# vim /etc/my.cnf
...... 省略 ......
#innodb_data_file_path = ibdata1:100M:autoextend
innodb_data_file_path = ibdata1:100M;ibdata2:10M;ibdata3:50M:autoextend
...... 省略 ......
# service mysql start
Starting MySQL.. [ OK ]
实例三:共享表空间数据迁移
# vim /etc/my.cnf
...... 省略 ......
innodb_file_per_table = 1
...... 省略 ......
[root@localhost db3306]# service mysql restart
Shutting down MySQL.. [ OK ]
Starting MySQL.. [ OK ]
此时注意,实例虽然已经完成变更,但是表还是共享表空间方式
# ls /data1/db3306/share_tablespace
db.opt t_share_innodb.frm
将表迁移到独立表空间,两种方式:
mysql> optimize table t_share_innodb;
mysql> #or
mysql> alter table t_share_innodb engine = innodb;
mysql> system ls /data1/db3306/share_tablespace
db.opt t_share_innodb.frm t_share_innodb.ibd
3.3.独立表空间
每一个表都将会生成以独立的文件方式来进行存储,每一个表都有一个.frm表描述文件,还有一个.ibd数据文件。 其中这个文件包括了单独一个表的数据内容以及索引内容,默认情况下它的存储位置也是在表的位置之中。(该innodb_file_per_table参数控制着innodb存储方式是共享表空间还是独立表空间;5.6.7版本默认开启)
- 优点
1.表空间可以回收,也可以整理表空间碎片(alter table table_name engine=innodb; 线上慎重,有DDL锁)
2.使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
3.每个表都有自已独立的表空间,每个表的数据和索引都会存在自已的表空间中,减少page级别的锁争用。
- 缺点
1.数据都是在表所路径的*.table_name.ibd文件中,如果存储空间不足,只能从操作系统层面思考解决方法。
- 最佳实践
独立表空间迁移请参考:3.2.共享表空间中最佳实践
3.4.General Tablespace
从5.7.6开始,增加了一种新的 tablespace模式(成为general tablespace),实际上它和共享表空间比较类似:创建一个单独的ibd,ibd中包含多个表,兼容不同的格式。general tablespace没有库的概念,因此可以在多个库里建属于同一tablespace的表;这种表空间的模式继承了ORACLE表空间的概念及实现。
- gerenal tablesapce限制:
- tablespace_name是大小写敏感的,不允许出现’/‘或者innodb_前缀的命名
- 不支持临时tablespace,也不支持在其中创建临时表
- 在DROP TABLESPACE之前,需要先手动删光里面的表
- 属于tablespace中的表,不支持alter table…import/discard tablespace
- ALTER TABLE…TABLESPACE总是会触发表的重建,也不支持修改数据目录
详情参考:https://dev.mysql.com/doc/refman/5.7/en/general-tablespaces.html
具体语法:
CREATE TABLESPACE tablespace_name
ADD DATAFILE 'file_name'
[FILE_BLOCK_SIZE = value]
[ENGINE [=] engine_name]
- 最佳实践
实例一:表空间的创建和表迁移
mysql> create tablespace pay_tbs add datafile 'pay_tbs01.ibd' engine=innodb;
Query OK, 0 rows affected (0.00 sec)
或者绝对路径
mysql> create tablespace center_tbs add datafile '/data2/db3306_datafile/center01.ibd' engine=innodb;
或者非标准page大小表空间
mysql> CREATE TABLESPACE `ts2` ADD DATAFILE 'ts2.ibd' FILE_BLOCK_SIZE = 8192 Engine=InnoDB;
创建表迁移至表空间
mysql> create table t2 (`id` int not null auto_increment,p_name varchar(20) ,primary key(id));
mysql> alter table t2 tablespace = pay_tbs;
表迁移至共享表空间
mysql> alter table t2 tablespace innodb_system;
表迁移至独立表空间
mysql> alter table t2 tablespace innodb_file_per_table;
实例二:分区表,表空间的应用
创建表空间
mysql> CREATE TABLESPACE `partition_tbs1` ADD DATAFILE 'partition_tbs1.ibd' Engine=InnoDB;
Query OK, 0 rows affected (0.01 sec)
mysql> CREATE TABLESPACE `partition_tbs2` ADD DATAFILE 'partition_tbs2.ibd' Engine=InnoDB;
Query OK, 0 rows affected (0.01 sec)
创建分区表
mysql> CREATE TABLE t1 (a INT, b INT) ENGINE = InnoDB
-> PARTITION BY RANGE(a) SUBPARTITION BY KEY(b) (
-> PARTITION p1 VALUES LESS THAN (100) TABLESPACE=`partition_tbs1`,
-> PARTITION p2 VALUES LESS THAN (1000) TABLESPACE=`partition_tbs2`,
-> PARTITION p3 VALUES LESS THAN (10000) TABLESPACE `innodb_file_per_table`,
-> PARTITION p4 VALUES LESS THAN (100000) TABLESPACE `innodb_system`);
创建子分区表
mysql> CREATE TABLE t3 (a INT, b INT) ENGINE = InnoDB
-> PARTITION BY RANGE(a) SUBPARTITION BY KEY(b) (
-> PARTITION p1 VALUES LESS THAN (100) TABLESPACE=`partition_tbs1`
-> (SUBPARTITION sp1,
-> SUBPARTITION sp2),
-> PARTITION p2 VALUES LESS THAN (1000)
-> (SUBPARTITION sp3,
-> SUBPARTITION sp4 TABLESPACE=`partition_tbs2`),
-> PARTITION p3 VALUES LESS THAN (10000)
-> (SUBPARTITION sp5 TABLESPACE `innodb_system`,
-> SUBPARTITION sp6 TABLESPACE `innodb_file_per_table`));
访问数据字典
mysql> SELECT NAME, SPACE, SPACE_TYPE FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES WHERE NAME LIKE '%t3%';
+---------------------------------+-------+------------+
| NAME | SPACE | SPACE_TYPE |
+---------------------------------+-------+------------+
| share_tablespace/t3#P#p1#SP#sp1 | 17 | General |
| share_tablespace/t3#P#p1#SP#sp2 | 17 | General |
| share_tablespace/t3#P#p2#SP#sp3 | 20 | Single |
| share_tablespace/t3#P#p2#SP#sp4 | 18 | General |
| share_tablespace/t3#P#p3#SP#sp5 | 0 | System |
| share_tablespace/t3#P#p3#SP#sp6 | 21 | Single |
+---------------------------------+-------+------------+
6 rows in set (0.00 sec)
mysql> SELECT A.NAME as partition_name, A.SPACE_TYPE as space_type, B.NAME as space_name FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES A LEFT JOIN INFORMATION_SCHEMA.INNODB_SYS_TABLESPACES B ON A.SPACE = B.SPACE WHERE A.NAME LIKE '%t1%' ORDER BY A.NAME;
+-----------------------------------+------------+-----------------------------------+
| partition_name | space_type | space_name |
+-----------------------------------+------------+-----------------------------------+
| share_tablespace/t1#P#p1#SP#p1sp0 | General | partition_tbs1 |
| share_tablespace/t1#P#p2#SP#p2sp0 | General | partition_tbs2 |
| share_tablespace/t1#P#p3#SP#p3sp0 | Single | share_tablespace/t1#P#p3#SP#p3sp0 |
| share_tablespace/t1#P#p4#SP#p4sp0 | System | NULL |
+-----------------------------------+------------+-----------------------------------+
3.5.Undo Tablespace(Log)
Innodb使用undo log来实现MVCC,这意味着如果一个很老的事务长时间不提交,那么新产生的undo log都无法被及时清理掉。在MySQL 5.5及之前版本中,undo log是存储在ibdata中。从5.6开始可以使用独立的undo log表空间来存储undo。但是直到5.6,一旦undo log膨胀,依然没有任何办法为其 “减肥”。因此我们经常看到ibdata被膨胀到几十上百G。
- undo truncate原理
当设置innodb_undo_log_truncate=ON的时候, undo表空间的文件大小,如果超过了innodb_max_undo_log_size, 就会被truncate到初始大小,但有一个前提,就是表空间中的undo不再被使用。
其主要步骤如下:
- 超过大小了之后,会被mark truncation,一次会选择一个
- 选择的undo不能再分配新给新的事务
- purge线程清理不再需要的rollback segment
- 等所有的回滚段都释放了后,truncate操作,使其成为install db时的初始状态。默认情况下, 是purge触发128次之后,进行一次rollback segment的free操作,然后如果全部free就进行一个truncate。但mark的操作需要几个依赖条件需要满足:
a) 系统至少得有两个undo表空间,防止一个offline后,至少另外一个还能工作
b) 除了ibdata里的segment,还至少有两个segment可用
c) undo表空间的大小确实超过了设置的阈值
因为,只要你设置了truncate = on,MySQL就尽可能的帮你去truncate所有的undo表空间,所以它会循环的把undo表空间加入到mark列表中。最后,循环所有的undo段,如果所属的表空间是marked truncate,就把这个rseg标志位不可分配,加入到trunc队列中,在purge的时候,进行free rollback segment。
注意:
如果是在线库,要注意影响,因为当一个undo tablespace在进行truncate的时候,不再承担undo的分配。只能由剩下的undo 表空间的rollback segment接受事务undo空间请求。
- 相关参数
| 参数 | 解释 |
|---|---|
| innodb_undo_tablespaces | 默认值为0;表示不独立设置undo的tablespace,默认记录到ibdata中;否则,则在undo目录下创建这么多个undo文件,例如假定设置该值为16,那么就会创建命名为undo001~undo016的undo tablespace文件,每个文件的默认大小为10M |
| innodb_undo_logs | 默认为128个回滚段;用于表示回滚段的个数(早期版本的命名为 innodb_rollback_segments ),该变量可以动态调整,但是物理上的回滚段不会减少,只是会控制用到的回滚段的个数; |
| innodb_undo_directory | 默认datadir目录;当开启独立undo表空间时,指定undo文件存放的目录如果我们想转移undo文件的位置,只需要修改下该配置,并将undo文件拷贝过去就可以了。 |
| innodb_purge_rseg_truncate_frequency | 默认128,表示purge undo轮询128次后,进行一次undo的truncate;用于控制purge回滚段的频度。 Innodb Purge操作的协调线程每隔这么多次purge事务分发后,就会触发一次History purge,并检查当前的undo log 表空间状态是否会触发truncate。 |
| innodb_max_undo_log_size | 控制最大undo tablespace文件的大小,超过这个阀值时才会去尝试truncate。truncate后的大小默认为10M。 |
| innodb_undo_log_truncate | 用于打开/关闭undo log 在线truncate特性,可动态调整。 |
扫描下方二维码关注本人微信号!欢迎大家交流学习!
