本文旨在实现论文 Deep Image Matting 中的抠图模型(Pytorch 版实现见 Pytorch 抠图算法 Deep Image Matting 模型实现)。
所有代码见 GitHub: deep_image_matting。
抠图是一个比较传统和应用广泛的技术,目前已经提出了一大批的算法,见 AlphaMatting,虽然以传统图像处理的方式居多,但随着深度学习技术的突飞猛进,当前抠图效果排行榜前几名已经被基于深度学习的算法占据。抠图问题可以用如下的方程来描述:
其中 表示给定的的要被抠图的图像, 分别表示前景、背景, 表示透明度的 alpha 通道。抠图算法要求解的是上述方程右边的 ,但是因为图像有三个通道,因此方程右边有 7 个未知数,而左边只有 3 个已知值,因此是一个不定方程(缺乏约束)。为了求出方程的确定解,通常的做法是添加一个额外的约束,或者事先给定一个三分图 trimap,或者给定一个草图 scribble。比如,给定一张要被抠的图像:

那么对应的三分图则类似于:

其中,白色部分表示一定是前景的区域,而黑色则一定是背景,剩下的灰色是不确定区域,需要抠图算法来求解;而草图则比较随意:

可以看成是三分图的极其简易版本。
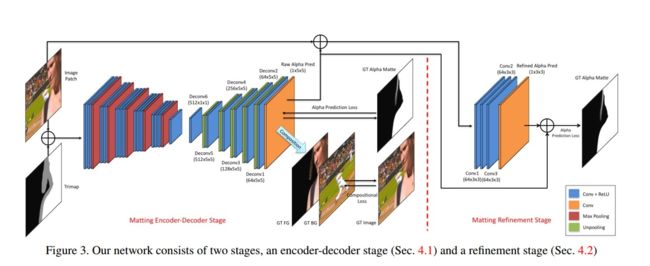
Deep Image Matting 使用卷积神经网络来从原图和三分图中预测 alpha 通道,具体为:将原图和三分图同时输入网络,首先借助卷积网络从图像中提取特征(编码器),然后利用转置卷积提升分辨率预测与输入一样大小的 alpha 通道(解码器),整个编码-解码的过程组成网络的第一阶段(编码器-解码器阶段);因为网络只关心三分图的不确定区域(灰色区域,对于确定区域由 trimap 提供 alpha 通道值),显然有理由相信网络的预测值要比输入的 trimap 更准确,如果用这个预测的 alpha 通道替换原来的 trimap,和原图再次合并重新进行编码-解码过程,那么新的预测值将更加准确,不过缺点也很明显,就是网络太大了,为了兼顾利用预测的更准确的 alpha 通道,又不至于使网络结构太复杂,论文作者将原图和预测的 alpha 通道合并之后,进行了 4 次卷积运行,输出最终的 alpha 通道预测值,这个过程称为网络的细化阶段。整个过程如下:
一、模型实现
对于给定的一张被抠图像和对应的三分图,deep image matting 论文的思路是:首先使用 VGG-16 的卷积层和第一个全连接层(fc6,也用卷积实现)作为编码器来提取特征,其中被抠图像是三通道的,因此直接用预训练的 VGG-16 模型参数来初始化,而三分图这个单通道则随机初始化;接下来,预测第一阶段的 alpha 通道,因为前面的编码阶段做了 5 次步幅为 2 的池化,因此图像的分辨率下降了 32 倍,即如果输入图像的分辨率为 320 x 320,则现在的分辨率为 10 x 10,为了预测与输入图像具有相同分辨率的 alpha 通道,需要将分辨率扩大 32 倍,这可以通过 5 个步幅为 2 的转置卷积实现;最后,将预测的 alpha 通道和输入图像拼接,再进行 4 个保持分辨率不变但通道数不断减小的卷积层得到最终的预测 alpha 通道。整个模型定义如下(见 model.py):
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 8 11:11:59 2018
@author: shirhe-lyh
"""
import tensorflow as tf
from tensorflow.contrib.slim import nets
import preprocessing
slim = tf.contrib.slim
class Model(object):
"""xxx definition."""
def __init__(self, is_training,
default_image_size=320,
first_stage_alpha_loss_weight=1.0,
first_stage_image_loss_weight=1.0,
second_stage_alpha_loss_weight=1.0):
"""Constructor.
Args:
is_training: A boolean indicating whether the training version of
computation graph should be constructed.
"""
self._is_training = is_training
self._default_image_size = default_image_size
self._first_stage_alpha_loss_weight = first_stage_alpha_loss_weight
self._first_stage_image_loss_weight = first_stage_image_loss_weight
self._second_stage_alpha_loss_weight = second_stage_alpha_loss_weight
def preprocess(self, trimaps, images=None, images_forground=None,
images_background=None, alpha_mattes=None):
"""preprocessing.
Outputs of this function can be passed to loss or postprocess functions.
Args:
trimaps: A float32 tensor with shape [batch_size,
height, width, 1] representing a batch of trimaps.
images: A float32 tensor with shape [batch_size, height, width,
3] representing a batch of images. Only passed values in case
of test (i.e., in training case images=None).
images_foreground: A float32 tensor with shape [batch_size,
height, width, 3] representing a batch of foreground images.
images_background: A float32 tensor with shape [batch_size,
height, width, 3] representing a batch of background images.
alpha_mattes: A float32 tensor with shape [batch_size,
height, width, 1] representing a batch of groundtruth masks.
Returns:
The preprocessed tensors.
"""
def _random_crop(t):
num_channels = t.get_shape().as_list()[2]
return preprocessing.random_crop_background(
t, output_height=self._default_image_size,
output_width=self._default_image_size,
channels=num_channels)
def _border_expand_and_resize(t):
return preprocessing.border_expand_and_resize(
t, output_height=self._default_image_size,
output_width=self._default_image_size)
def _border_expand_and_resize_g(t):
return preprocessing.border_expand_and_resize(
t, output_height=self._default_image_size,
output_width=self._default_image_size,
channels=1)
preprocessed_images_fg = None
preprocessed_images_bg = None
preprocessed_alpha_mattes = None
preprocessed_trimaps = tf.map_fn(_border_expand_and_resize_g, trimaps)
preprocessed_trimaps = tf.to_float(preprocessed_trimaps)
if self._is_training:
preprocessed_images_fg = tf.map_fn(_border_expand_and_resize,
images_forground)
preprocessed_alpha_mattes = tf.map_fn(_border_expand_and_resize_g,
alpha_mattes)
images_background = tf.to_float(images_background)
preprocessed_images_bg = tf.map_fn(_random_crop, images_background)
preprocessed_images_fg = tf.to_float(preprocessed_images_fg)
preprocessed_alpha_mattes = tf.to_float(preprocessed_alpha_mattes)
preprocessed_images = (tf.multiply(
preprocessed_alpha_mattes, preprocessed_images_fg) +
tf.multiply(
1 - preprocessed_alpha_mattes, preprocessed_images_bg))
else:
preprocessed_images = tf.map_fn(_border_expand_and_resize, images)
preprocessed_images = tf.to_float(preprocessed_images)
preprocessed_dict = {'images_fg': preprocessed_images_fg,
'images_bg': preprocessed_images_bg,
'alpha_mattes': preprocessed_alpha_mattes,
'images': preprocessed_images,
'trimaps': preprocessed_trimaps}
return preprocessed_dict
def predict(self, preprocessed_dict):
"""Predict prediction tensors from inputs tensor.
Outputs of this function can be passed to loss or postprocess functions.
Args:
preprocessed_dict: See The preprocess function.
Returns:
prediction_dict: A dictionary holding prediction tensors to be
passed to the Loss or Postprocess functions.
"""
# The inputs for the first stage
preprocessed_images = preprocessed_dict.get('images')
preprocessed_trimaps = preprocessed_dict.get('trimaps')
# VGG-16
_, endpoints = nets.vgg.vgg_16(preprocessed_images,
num_classes=1,
spatial_squeeze=False,
is_training=self._is_training)
# Note: The `padding` method of fc6 of VGG-16 in tf.contrib.slim is
# `VALID`, but the expected value is `SAME`, so we must replace it.
net_image = endpoints.get('vgg_16/pool5')
net_image = slim.conv2d(net_image, num_outputs=4096, kernel_size=7,
padding='SAME', scope='fc6_')
# VGG-16 for alpha channel
net_alpha = slim.repeat(preprocessed_trimaps, 2, slim.conv2d, 64,
[3, 3], scope='conv1_alpha')
net_alpha = slim.max_pool2d(net_alpha, [2, 2], scope='pool1_alpha')
net_alpha = slim.repeat(net_alpha, 2, slim.conv2d, 128, [3, 3],
scope='conv2_alpha')
net_alpha = slim.max_pool2d(net_alpha, [2, 2], scope='pool2_alpha')
net_alpha = slim.repeat(net_alpha, 2, slim.conv2d, 256, [3, 3],
scope='conv3_alpha')
net_alpha = slim.max_pool2d(net_alpha, [2, 2], scope='pool3_alpha')
net_alpha = slim.repeat(net_alpha, 2, slim.conv2d, 512, [3, 3],
scope='conv4_alpha')
net_alpha = slim.max_pool2d(net_alpha, [2, 2], scope='pool4_alpha')
net_alpha = slim.repeat(net_alpha, 2, slim.conv2d, 512, [3, 3],
scope='conv5_alpha')
net_alpha = slim.max_pool2d(net_alpha, [2, 2], scope='pool5_alpha')
net_alpha = slim.conv2d(net_alpha, 4096, [7, 7], padding='SAME',
scope='fc6_alpha')
# Concate the first stage prediction
net = tf.concat(values=[net_image, net_alpha], axis=3)
net.set_shape([None, self._default_image_size // 32,
self._default_image_size // 32, 8192])
# Deconvlution
with slim.arg_scope([slim.conv2d_transpose], stride=2, kernel_size=5):
# Deconv6
net = slim.conv2d_transpose(net, num_outputs=512, kernel_size=1,
scope='deconv6')
# Deconv5
net = slim.conv2d_transpose(net, num_outputs=512, scope='deconv5')
# Deconv4
net = slim.conv2d_transpose(net, num_outputs=256, scope='deconv4')
# Deconv3
net = slim.conv2d_transpose(net, num_outputs=128, scope='deconv3')
# Deconv2
net = slim.conv2d_transpose(net, num_outputs=64, scope='deconv2')
# Deconv1
net = slim.conv2d_transpose(net, num_outputs=64, stride=1,
scope='deconv1')
# Predict alpha matte
alpha_matte = slim.conv2d(net, num_outputs=1, kernel_size=[5, 5],
activation_fn=tf.nn.sigmoid,
scope='AlphaMatte')
# The inputs for the second stage
alpha_matte_scaled = tf.multiply(alpha_matte, 255.)
refine_inputs = tf.concat(
values=[preprocessed_images, alpha_matte_scaled], axis=3)
refine_inputs.set_shape([None, self._default_image_size,
self._default_image_size, 4])
# Refine
net = slim.conv2d(refine_inputs, num_outputs=64, kernel_size=[3, 3],
scope='refine_conv1')
net = slim.conv2d(net, num_outputs=64, kernel_size=[3, 3],
scope='refine_conv2')
net = slim.conv2d(net, num_outputs=64, kernel_size=[3, 3],
scope='refine_conv3')
refined_alpha_matte = slim.conv2d(net, num_outputs=1,
kernel_size=[3, 3],
activation_fn=tf.nn.sigmoid,
scope='RefinedAlphaMatte')
prediction_dict = {'alpha_matte': alpha_matte,
'refined_alpha_matte': refined_alpha_matte,
'trimaps': preprocessed_trimaps,}
return prediction_dict
def postprocess(self, prediction_dict, use_trimap=True):
"""Convert predicted output tensors to final forms.
Args:
prediction_dict: A dictionary holding prediction tensors.
**params: Additional keyword arguments for specific implementations
of specified models.
Returns:
A dictionary containing the postprocessed results.
"""
alpha_matte = prediction_dict.get('alpha_matte')
refined_alpha_matte = prediction_dict.get('refined_alpha_matte')
if use_trimap:
trimaps = prediction_dict.get('trimaps')
alpha_matte = tf.where(tf.equal(trimaps, 128), alpha_matte,
trimaps / 255.)
refined_alpha_matte = tf.where(tf.equal(trimaps, 128),
refined_alpha_matte,
trimaps / 255.)
postprocessed_dict = {'alpha_matte': alpha_matte,
'refined_alpha_matte': refined_alpha_matte}
return postprocessed_dict
def loss(self, prediction_dict, preprocessed_dict, epsilon=1e-12):
"""Compute scalar loss tensors with respect to provided groundtruth.
Args:
prediction_dict: A dictionary holding prediction tensors.
preprocessed_dict: A dictionary of tensors holding groundtruth
information, see preprocess function. The pixel values of
groundtruth_alpha_matte must be in [0, 128, 255].
Returns:
A dictionary mapping strings (loss names) to scalar tensors
representing loss values.
"""
gt_images = preprocessed_dict.get('images')
gt_fg = preprocessed_dict.get('images_fg')
gt_bg = preprocessed_dict.get('images_bg')
gt_alpha_matte = preprocessed_dict.get('alpha_mattes')
alpha_matte = prediction_dict.get('alpha_matte')
refined_alpha_matte = prediction_dict.get('refined_alpha_matte')
pred_images = tf.multiply(alpha_matte, gt_fg) + tf.multiply(
1 - alpha_matte, gt_bg)
trimaps = prediction_dict.get('trimaps')
weights = tf.where(tf.equal(trimaps, 128),
tf.ones_like(trimaps),
tf.zeros_like(trimaps))
total_weights = tf.reduce_sum(weights) + epsilon
first_stage_alpha_losses = tf.sqrt(
tf.square(alpha_matte - gt_alpha_matte) + epsilon)
first_stage_alpha_loss = tf.reduce_sum(
first_stage_alpha_losses * weights) / total_weights
first_stage_image_losses = tf.sqrt(
tf.square(pred_images - gt_images) + epsilon) / 255.
first_stage_image_loss = tf.reduce_sum(
first_stage_image_losses * weights) / total_weights
second_stage_alpha_losses = tf.sqrt(
tf.square(refined_alpha_matte - gt_alpha_matte) + epsilon)
second_stage_alpha_loss = tf.reduce_sum(
second_stage_alpha_losses * weights) / total_weights
loss = (self._first_stage_alpha_loss_weight * first_stage_alpha_loss +
self._first_stage_image_loss_weight * first_stage_image_loss +
self._second_stage_alpha_loss_weight * second_stage_alpha_loss)
loss_dict = {'loss': loss}
return loss_dict
说明:
1.在 tf.contrib.slim 中的 VGG-16 的定义中,虽然 fc6 已经用卷积替换全连接,但 padding 的方式是 VALID,这样经过 fc6 作用后分辨率将变成 4 x 4(10 - 7 + 1 = 4,假如输入图像分辨率为 320 x 320),将给后面扩充特征映射分辨率带来麻烦。因此需要将该层的 padding 方式修改为 SMAE,从而分辨率仍然保持为 10 x 10,这样通过 5 个步幅为 2 的转置卷积就可以将分辨率扩充到 320 x 320。
2.因为预训练的 VGG-16 模型的参数是针对 3 通道图像的,因此虽然待抠图像和三分图都要经过 VGG-16 网络,但为了导入预训练模型,仍然需要将它们分裂为两部分独立的输入 VGG-16 模型。(以上 model.py 定义 alpha 通道的 VGG-16 模型时写得复杂了,简化版参考如下说明 3 的 AlphaResNet 部分定义。)
3.因为 ResNet-50 比 VGG-16 ,在 ImageNet 上的分类效果好,而且模型参数总量更小,因此可以用 ResNet-50 替换 VGG-16,这时候可以将输入图像大小扩充为 640 x 640 的分辨率(但在 1080Ti 上需要将批量由 4 减小为 2)。替换代码如下(只需要替换 predict 函数):
def predict(self, preprocessed_dict):
"""Predict prediction tensors from inputs tensor.
Outputs of this function can be passed to loss or postprocess functions.
Args:
preprocessed_dict: See The preprocess function.
Returns:
prediction_dict: A dictionary holding prediction tensors to be
passed to the Loss or Postprocess functions.
"""
# The inputs for the first stage
preprocessed_images = preprocessed_dict.get('images')
preprocessed_trimaps = preprocessed_dict.get('trimaps')
# ResNet-50
net_image, _ = nets.resnet_v1.resnet_v1_50(
preprocessed_images,num_classes=None, global_pool=False,
is_training=self._is_training)
# ResNet-50 for alpha channel
with tf.variable_scope('AlphaResNet'):
net_alpha, _ = nets.resnet_v1.resnet_v1_50(
preprocessed_trimaps, num_classes=None, global_pool=False,
is_training=self._is_training)
# Concate the first stage prediction
net = tf.concat(values=[net_image, net_alpha], axis=3)
net.set_shape([None, self._default_image_size // 32,
self._default_image_size // 32, 4096])
# Deconvlution
with slim.arg_scope([slim.conv2d_transpose], stride=2, kernel_size=5):
# Deconv6
... (下同)
4.因为三分图中白色区域是确定的前景,黑色是确定的背景,因此在后处理(见函数 postprocess )时,直接在预测结果基础上将对应的前景、背景区域替换为三分图的前景、背景区域值作为模型最后的输出。
显然,整个模型的结构是非常清晰的,接下来需要定义损失函数。损失函数由三部分组成,第一阶段包含两个损失,第二阶段包含一个损失,这三个损失的加权和即是模型的总损失。因为,三分图中白色区域、黑色区域都是确定的前景、背景,因此这两个区域不存在损失,所以损失只需要对灰色区域计算即可。第一阶段的损失包括:alpha 预测损失,即预测的
alpha 通道和 groundtruth 的 alpha 通道的损失值;图像合成损失,即前景图像、背景图像关于预测的 alpha 通道的合成图像,和前景图像、背景图像关于 groundtruth 的 alpha 通道的合成图像的损失值。第二阶段的损失只有 alpha 预测损失,即细化的 alpha 通道预测值和 groundtruth 的 alpha 通道值之间的损失。论文中使用的三个损失都是逐像素的差值绝对值之和。具体实现见 loss 函数。
二、代码解释
三、训练实例
(未完,待续)