特点:
- 字符串(string)是由数字、字母、下划线组成的一串字符。
- 在python中表示文本的数据类型,几乎可以包含任何字符,英文字符、中文字符、其他语言也行,是一种不可变的序列。
- 字符串通常包含在单引号('')双引号("")或者三引号之中(''' '''或或""" """,两者一样)。
name = 'tank'
city = 'beijing'
infos = "welcome to beijing"
字符串格式化:
字符串格式化,是将一个字符串中某些经常可能会改变的地方,提取出来,用一些占位符占位,后面再通过格式化的方式填充进去。格式化字符串有三种方式,第一种方式是使用%s的形式,第二种是使用format方法,第三种是使用f方法。下面依次来讲解一下:
- 使用
%s的形式
name = 'tank'
des = 'beijing'
print('welcome to %s %s'%(des,name))#%的数量和后面()元组中的变量要相互对应
welcome to beijing tank
以上是使用%s的形式进行补充,%的数量要后面%()括号里面的变量要相同。对于不同类型的数据,需要使用不同的格式:
- 字符串:使用
%s。 - 整形:使用
%d。 - 浮点类型:使用
%f。如果想要指定小数点后的位数。可以使用%.nf来表示,n为1表示一位小数,n为2表示2为小数,依次类推。
- 使用
format方法:需要填充的地方用{}进行占位,然后再用.format进行补充。
- 位置占位符进行字符串格式化
name = 'tank'
des = 'beijing'
print('welcome to {} {}'.format(des,name))#默认情况下根据索引从小到大进行,元组(des,name)索引默认就是0,1
welcome to beijing tank
等价于
name = 'tank'
des = 'beijing'
print('welcome to {0} {1}'.format(des,name))
print('welcome to {2} {3}'.format(des,name))#超过索引时,会提示错误
welcome to beijing tank
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
in
2 des = 'beijing'
3 print('welcome to {0} {1}'.format(des,name))
----> 4 print('welcome to {2} {3}'.format(des,name))
IndexError: tuple index out of range
还可以根据自己的需要调整占位符的顺序
name = 'tank'
des = 'beijing'
print('welcome to {1} {0}'.format(des,name))
welcome to tank beijing
这样就name显示在前,des显示在后了。
- 关键字参数占位符
name = 'tank'
des = 'beijing'
print('welcome to {arg1} {arg2}'.format(arg1=des,arg2=name))
welcome to beijing tank
- f-strings方法:注意在python3.7才能使用。
name = 'tank'
des = 'beijing'
print(f'welcome to {des} {name}')
welcome to beijing tank
这里f的作用就是找到{},然后把括号中的值当作一个变量,然后再获取这个变量的值。另外,还需要注意使用f-strings格式化时的转义,比如要在字符串中输出{ok},要输入两个花括号{{}}。
name = 'tank'
des = 'beijing'
print(f'{{ok}} welcome to {des} {name}')
{ok} welcome to beijing tank
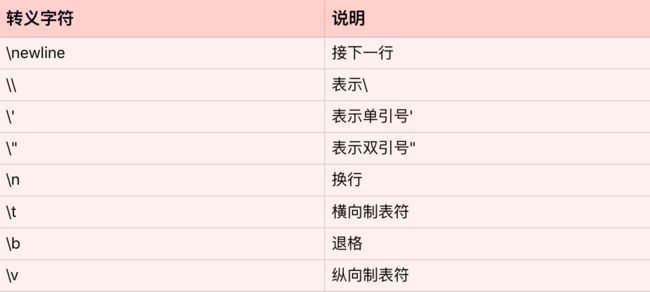
所谓的转义字符,就是用反斜杠开头的字符串,来表示一些特定意义的字符。常见的的转义字符,如下表:
字符串的常用方法
- 字符串索引:其实和列表、元组的操作差不多。
l = 'welcome to beijing tank'
print(l[0])
print(l[1])
print(l[2])
print(l[3])
w
e
l
c
- 字符串的切片:其实和列表、元组的操作差不多。需要注意左包含原则。
l = 'welcome to beijing tank'
print(l[0:7])
print(l[-4:])
welcome
tank
-
find:返回查找字符串的下标位置。如果返回的是-1,代表的是没有查找到该字符串。rfind是从右边到左边。
l = 'welcome to beijing tank tank'
print(l.find('t'))
8
返回的是找到的第一个字符串的索引位置。
-
index:和find非常类似。只不过当查找不到这个字符串的时候,不是返回-1,而是抛出一个异常。rindex是从右边开始查找。 -
len:获取字符串字符的长度。
l = 'welcome to beijing tank tank'
print(len(l))
28
-
count:用来获取子字符串在原来字符串中出现的次数。
l = 'welcome to beijing tank tank'
print(l.count('t'))
3
-
replace:新创建一个字符串,把原来字符串中的某个字符串替换为你想要的字符串。
list_1 = 'welcome to beijing tank tank'
print(list_1.replace('to','XX'))
welcome XX beijing tank tank
-
split:按照给定的字符串进行分割。返回的是一个列表。
list_1 = 'welcome to beijing tank tank'
list_2 = 'www.baidu.com'
print(list_1.split(' '))
print(list_2.split('.'))
['welcome', 'to', 'beijing', 'tank', 'tank']
['www', 'baidu', 'com']
-
startswith:判断一个字符串是否以某个字符串开始。
list_2 = 'www.baidu.com'
print(list_2.startswith('www'))
True
endswith:判断一个字符串是否以某个字符串结束。使用与startswith相同。lower:将字符串全部改成小写,返回一个新字符串。
list_1 = 'Welcome To Beijing '
list_2 = list_1.lower()
print(list_1)
print(list_2)
Welcome To Beijing
welcome to beijing
-
upper:将字符串全部改成大写。 -
strip:将字符串左右的空格全部去掉。
list_1 = ' Welcome To Beijing '
list_2 = list_1.strip()
print(list_1)
print(list_2)
Welcome To Beijing
Welcome To Beijing
lstrip:删除字符串左边的空格。rstrip:删除字符串右边的空格。isalnum:如果string至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False。
list_1 = '123'
print(list_1.isalnum())
True
-
isalpha:如果string至少有一个字符并且所有字符都是字母则返回True,否则返回False。 -
isdigit:如果string只包含数字则返回True否则返回False。 -
isspace:如果字符串中只包含空格,则返回True,否则返回False。 - 字符串的拼接:使用加法操作符'+='的字符串拼接方法。它是一个例外,打破了字符串不可改变的特性。另外,它的使用效率非常高,时间复杂度就仅为 O(n)。
s = ' '
for x in range(0,10):
s += str(x)
print(s)
0123456789
‘ ’.jion方法也可以实现字符串的拼接
s = []
for x in range(0,10):
s.append(str(x))
s = ''.join(s)
print(s)
0123456789