疑惑
《如何用VOSviewer分析CNKI数据?》一文发布后,有同学问我:
王老师,我有个问题,我用cnki导出关键词后,想统计关键词的词频,我应该用什么样的工具?如果不利用citespace和python,做出excel那种的统计表格,该怎么做呢?
这个问题,我觉得很有意思。统计关键词的词频,确实也用不到Citespace。
那我们就来试试看,怎么做才好。
数据
首先检索文献。我这里检索的是2017年知网收录的“竞争情报”相关的论文。一共154篇。
下面就是手动全选,翻几页,选完全部。
然后导出文献。
默认的格式显然不符合我们的要求,因为根本不包含关键词。我们可以选择“自定义”。
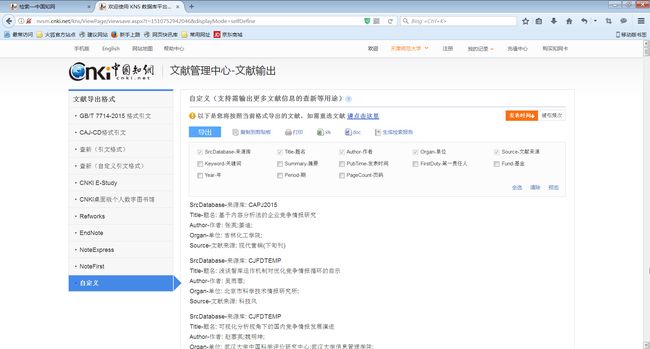
注意前面几项内容,是无法不勾选的。我们因为要分析关键词,所以勾选关键词项。
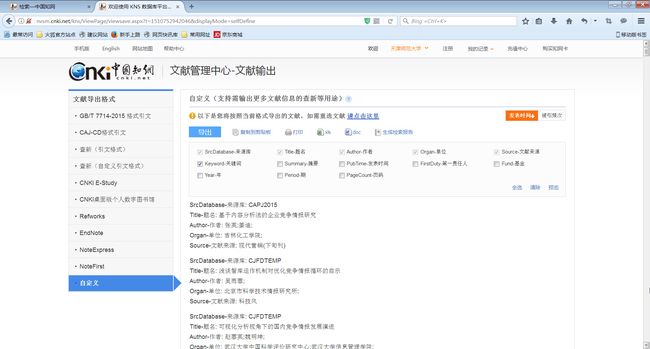
好了,我们用xls格式导出。
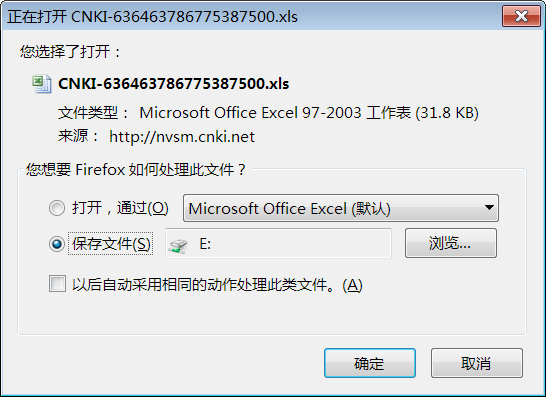
注意在macOS下面,导出后的Excel文件打开的时候会报错,忽略即可。
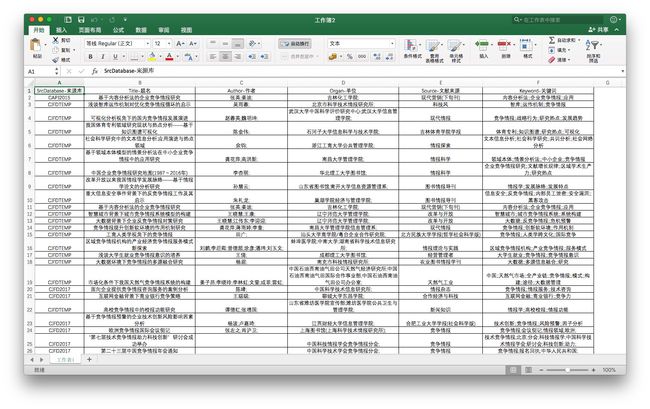
经检验,数据完整。但是我们最好重新保存成为新的xlsx文件,以便于后续正常使用。我们另存为文件名cnki.xlsx。
注意这里的关键词列,可以看到关键词之间用两个分号来分割。有的文章关键词多,有的关键词少。我们要统计关键词词频,就得处理这种格式问题。
分析
因为读者要求,不可以用Citespace,也不许用Python。Excel的编程我又不会,怎么办呢?
后来一想,干脆用R好了。
打开RStudio环境。
新建一个RMarkdown文件。清除全部正文内容。正式开始我们的分析过程。
首先,设置时区。
Sys.setenv(TZ="Asia/Shanghai")
然后设定工作目录。请根据你的具体情况,更改为自己的工作目录。
setwd("/Users/wsy/coaching/term-frequency-cnki/")
下面载入几个必要的软件包。
library(tidyverse)
library(readxl)
library(tidytext)
读入我们的Excel文件。
df <- read_excel("cnki.xlsx")
我们只需要其中的两列数据,分别是标题和关键词。
df1 <- df %>%
select(starts_with('Keyword'), starts_with('Title'))
因为原先的Excel里面列名中英文混合,这里我们修改为英文名称,便于后续使用。
colnames(df1) <- c('keyword', 'title')
然后我们就需要对关键词这一列进行处理了。我们拆分一下,把关键词拆分,每一行保留一个关键词。
df1 %>%
unnest_tokens(word, keyword, token = stringr::str_split, pattern = ";;")
结果如下:
## # A tibble: 524 x 2
## title word
##
## 1 基于内容分析法的企业竞争情报研究 内容分析法
## 2 基于内容分析法的企业竞争情报研究 企业竞争情报
## 3 基于内容分析法的企业竞争情报研究 应用
## 4 浅谈智库运作机制对优化竞争情报循环的启示 智库
## 5 浅谈智库运作机制对优化竞争情报循环的启示 运作机制
## 6 浅谈智库运作机制对优化竞争情报循环的启示 竞争情报
## 7 可视化分析视角下的国内竞争情报发展演进 竞争情报
## 8 可视化分析视角下的国内竞争情报发展演进 战略行为
## 9 可视化分析视角下的国内竞争情报发展演进 研究热点
## 10 可视化分析视角下的国内竞争情报发展演进 发展趋势
## # ... with 514 more rows
这样看着就清晰多了,是不是?
下面我们需要设置停用词。毕竟我们搜索的主题词是竞争情报,这里再统计“竞争情报”没有意义。所以我们需要在停用词表里过滤掉它。
我们先看看系统默认的停用词表是什么样子的?
data(stop_words)
stop_words
## # A tibble: 1,149 x 2
## word lexicon
##
## 1 a SMART
## 2 a's SMART
## 3 able SMART
## 4 about SMART
## 5 above SMART
## 6 according SMART
## 7 accordingly SMART
## 8 across SMART
## 9 actually SMART
## 10 after SMART
## # ... with 1,139 more rows
哦,原来是个数据框,那我们仿照这个样子,也设置自己的停用词表。
my_stop_words_list = c('竞争情报')
my_lexicon_list = c('UNKNOWN')
my_stop_words = data.frame(my_stop_words_list, my_lexicon_list, stringsAsFactors=FALSE)
colnames(my_stop_words) <- c('word', 'lexicon')
my_stop_words
这一段里面,我们先建立两个向量,分别是停用词和词典。因为我们不涉及词典的属性设置,所以统一设置为UNKOWN。
显示的结果,停用词表是个数据框,里面只有一个停用词——“竞争情报”。
## word lexicon
## 1 竞争情报 UNKNOWN
下面我们把刚才的内容串起来,先拆关键词,然后停用词过滤,最后统计停用词词频,并且排序:
df1 %>%
unnest_tokens(word, keyword, token = stringr::str_split, pattern = ";;") %>%
anti_join(my_stop_words) %>%
count(word, sort = TRUE)
结果如下:
## Joining, by = "word"
## # A tibble: 362 x 2
## word n
##
## 1 大数据 17
## 2 企业竞争情报 9
## 3 企业 8
## 4 情报学 7
## 5 产业竞争情报 6
## 6 反竞争情报 6
## 7 研究热点 6
## 8 情报服务 5
## 9 情报需求 4
## 10 知识图谱 4
## # ... with 352 more rows
看来今年的竞争情报研究文献里,最突出的关键词是“大数据”。
然后我们尝试用ggplot可视化一下,只看那些出现3次以上的关键词统计结果:
df1 %>%
unnest_tokens(word, keyword, token = stringr::str_split, pattern = ";;") %>%
anti_join(my_stop_words) %>%
count(word, sort = TRUE) %>%
filter(n > 3) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col() +
xlab(NULL) +
coord_flip()
## Joining, by = "word"
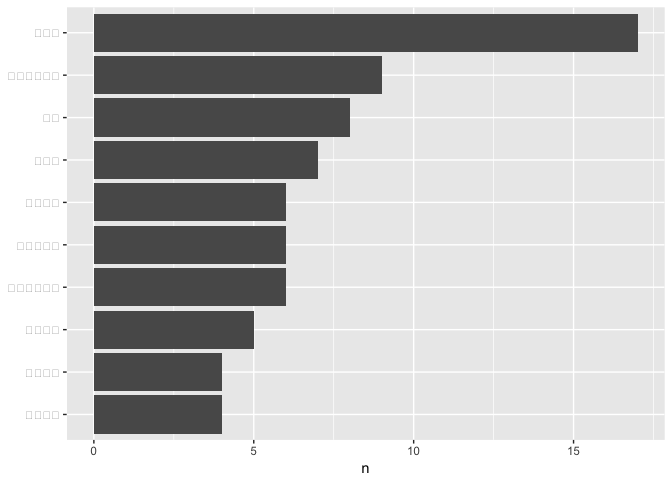
结果令我们很不满,因为关键词显示都是方框。
别着急,这种情况,是因为系统默认使用的字体不能识别汉字。只要告诉ggplot一声,让它使用汉字字体,例如黑体,就可以了。
df1 %>%
unnest_tokens(word, keyword, token = stringr::str_split, pattern = ";;") %>%
anti_join(my_stop_words) %>%
count(word, sort = TRUE) %>%
filter(n > 3) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col() +
xlab(NULL) +
coord_flip() +
theme(text=element_text(family="SimHei"))
## Joining, by = "word"
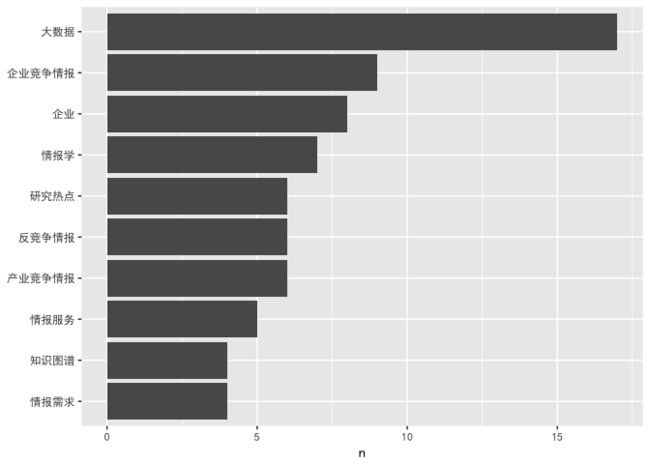
这次看着就舒服多了,不是吗?
讨论
读过本文之后,你有什么心得要分享给大家吗?有没有不同的意见或看法?欢迎留言,记录下你的思考,我们一起交流讨论。
如果你对我的文章感兴趣,欢迎点赞,并且微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果本文可能对你身边的亲友有帮助,也欢迎你把本文通过微博或朋友圈分享给他们。让他们一起参与到我们的讨论中来。
延伸阅读
如何用《玉树芝兰》入门数据科学?
数据科学相关文章合集(玉树芝兰)