原文:https://www.fanhaobai.com/2018/01/2018-new-year-activity.html
2017 年是自如快速增长的一年,自如客突破 100 万,管理资产达到 50 万间,在年底成功获得了 40 亿 A 轮融资,而这些都要感谢广大的自如客,公司为了回馈自如客,在六周年活动时就发放了 6000 万租住基金,当然年底散币活动也够疯狂。

活动规模
既然公司对自如客这么阔,那对我们员工也得够意思,所以年底我们共准备了 3 个活动。
1、针对 自如客 的服务费减免活动;
2、针对 自如客 的 1000 万现金礼包;
3、25 万的 员工 红包活动;

散币活动 2 和 3 是通过微信红包形式进行,想散币就散吧,可微信告诉我们,想散币还得交税(>﹏<)。员工红包来说,25 万要交掉 10 多万税,此时心疼我的钱。好了,下面开始说点正事。
技术方案
说到红包,我们肯定会想到红包拆分和抢红包两个场景。红包拆分是指将指定金额拆分为指定数目红包的过程,即是用来确定每个红包的金额数;而抢红包就是典型的高并发场景,需要避免红包超发的情况。
红包拆分
可选的方案
拆分方式
1、实时拆分
实时拆分,指的是在抢红包时实时计算每个红包的金额,以实现红包的拆分过程,对系统性能和拆分算法要求较高,例如拆分过程要一直保证后续待拆分红包的金额不能为空,不容易做到拆分红包的金额服从正态分布规律。
2、预先生成
预先生成,指的是在红包开抢之前已经完成了红包的拆分,抢红包时只是依次取出拆分好的红包金额,对拆分算法要求较低,可以拆分出随机性很好的红包金额,通常需要结合队列使用。
拆分算法
我并没有找到业界的通用算法,但红包拆分算法应该是拆分金额要看起来随机,最好能够服从正态分布,可以参考 微信 和 @lcode 提供的红包拆分算法。
微信拆分算法的优点是算法较简单,拆分效率高,同时,由于该算法天然的特性,可以保证后续红包金额一定不为空,特别适合实时拆分场景,但缺点是会导致大额红包较大概率地在拆分的最后出现。 @lcode 拆分算法的优点是拆分金额基本符合正态分布,适合随机性要求较高的拆分场景。
我们的方案
我们这次的业务对红包金额的随机性要求不高,但是对系统可靠性要求较高,所以我们选用了预算生成方式,并借鉴 微信 的红包拆分算法,作为我们的红包拆分方案。
采用预算生成方式,我们预先生成红包并放入 Redis 的 List 中,当抢红包时只是 Pop List 即可,具体实现将在 抢红包 部分介绍。
拆分算法可以描述为:假设剩余拆分金额为 M,剩余待拆分红包个数为 N,红包最小金额为 1 元,红包最小单位为元,那么定义当前红包的金额为:
$$m = rand(1, floor(M/N*2))$$
其中,floor 表示向下取整,rand(min, max) 表示从 [min, max] 区间随机一个值。$M/N \ast 2$ 表示剩余待拆分金额平均金额的 2 倍,因为 N >= 2,所以 $M/N \ast 2 <= M$,表示一定能保证后续红包能拆分到金额。
代码实现为:
for ($i = 0; $i < $N - 1; $i++) {
$max = (int)floor($M / ($N - $i)) * 2;
$m[$i] = $max ? mt_rand(1, $max) : 0;
$M -= $m[$i];
}
$m[] = $M;
值得一提的是,我们为了保证红包金额差异尽量小,先将总金额平均拆分成 N+1 份,将第 N+1 份红包按照上述的红包拆分算法拆分成 N 份,这 N 份红包加上之前的平均金额才作为最终的红包金额。
抢红包
可选的方案
限流
1、前端限流
前端限制用户在 n 秒之内只能提交一次请求,虽然这种方式只能挡住小白,不过这是 99% 的用户哟,所以也必须得做。
2、后端限流
常用的后端限流方法有 漏桶算法 和 令牌桶算法。漏桶算法 主要目的是控制请求数据注入的速率,如果此时漏桶溢出,后续的请求数据会被丢弃。而 令牌桶算法 是以一个恒定的速度往桶里放入令牌,而如果请求数据需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌时,这些请求才被丢弃,令牌桶算法的一个好处是可以方便地改变应用接受请求的速率。
防超发
1、库存加锁
可以通过加锁的方式解决资源抢占问题,但是加锁会增加系统开销,大流量下更容易拖垮系统,不过可以尝试一下基于版本号的乐观锁。
2、通过高速队列串行化请求
之所会出现超发问题,是因为并发时会出现多个进程同时获取同一资源的现象,如果使用高速队列将并行请求串行化,那么问题就不存在了。高速队列可以使用 Redis 缓存服务器来实现,当然光使用队列还不够,必要保证整个流程调用链要短、要快,否则队列会积压严重,甚至会拖垮整个服务。
我们的方案
在限流方面,由于我们预估的请求量还在系统承受范围,所以没有考虑引入后端限流方案。我们的抢红包系统流程图如下:
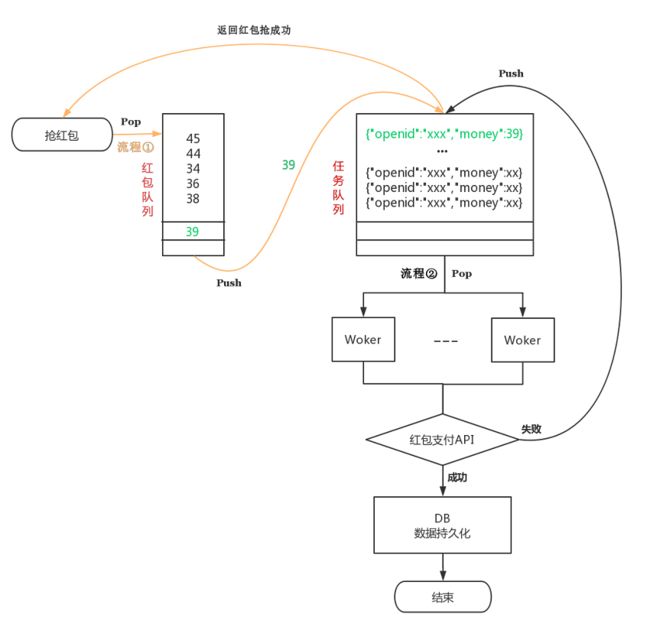
我们将抢红包拆分为 红包占有(流程①,同步) 和 红包发放 (流程②,异步)这两个过程,首先采用高速队列串行化请求,红包发放逻辑由一组 Worker 异步去完成。高速队列只是完成红包占有的过程,实现库存的控制,Worker 则处理耗时较长的红包发放过程。
当然,在实际应用中,红包占用过程还需要加上一些前置规则校验,比如用户是否已经领取过,领取次数是否已经达到上限等?红包占有流程图如下:
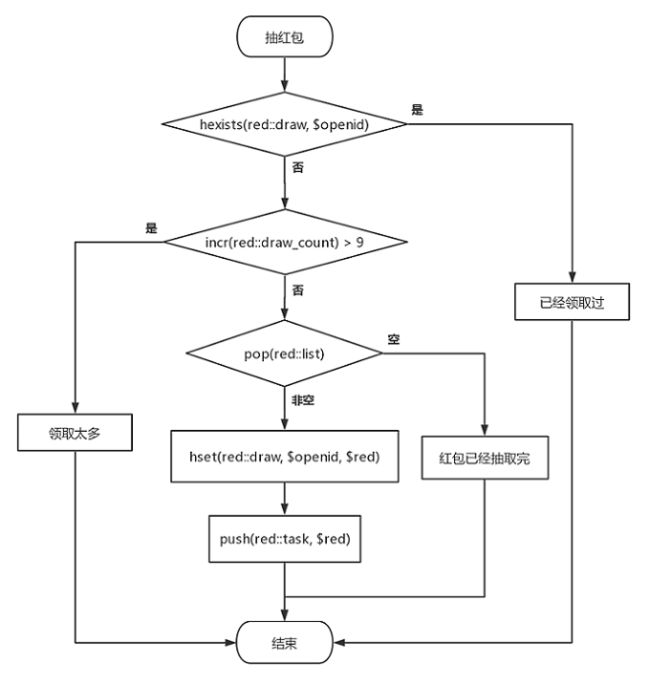
其中,red::list为 List 结构,存放预先生成的红包金额(流程①中的红包队列);red::task 也为 List 结构,红包异步发放队列(流程②中的任务队列);red::draw为 Hash 结构,存放红包领取记录,field为用户的 openid,value为序列化的红包信息;red::draw_count:u:openid为 K-V 结构,用户领取红包计数器。
下面,我将以以下 3 个问题为中心,来说说我们设计出的抢红包系统。
1、怎么保证不超发
我们需要关注的是红包占有过程,从红包占有流程图可看出,这个过程是很多 Key 操作的组合,那怎么保证原子性?可以使用 Redis 事务,但我们选用了 Lua 方案,一方面是因为首先要保证性能,而 Lua 脚本嵌入 Redis 执行不存在性能瓶颈,另一方面 Lua 脚本执行时本身就是原子性的,满足需求。
红包占有的 Lua 脚本实现如下:
-- 领取人的openid为xxxxxxxxxxx
local openid = 'xxxxxxxxxxx'
local isDraw = redis.call('HEXISTS', 'red::draw', openid)
-- 已经领取
if isDraw ~= 0 then
return true
end
-- 领取太多次了
local times = redis.call('INCR', 'red::draw_count:u:'..openid)
if times and tonumber(times) > 9 then
return 0
end
local number = redis.call('RPOP', 'red::list')
-- 没有红包
if not number then
return {}
end
-- 领取人昵称为Fhb,头像为https://xxxxxxx
local red = {money=number,name='Fhb',pic='https://xxxxxxx'}
-- 领取记录
redis.call('HSET', 'red::draw', openid, cjson.encode(red))
-- 处理队列
red['openid'] = openid
redis.call('RPUSH', 'red::task', cjson.encode(red))
return true
需要注意 Lua 脚本执行过程并不是事务的,脚本中的操作命令在执行时是有先后顺序的,当某个操作执行失败时不会回滚已经执行成功的操作,它的原子性是通过单线程模型实现。
2、怎么提高系统响应速度
如红包占有流程图所示,当用户发起抢红包请求时,若有红包则直接完成红包占有操作,同步告知用户是否抢到红包,这个过程要求快速响应。
但由于微信红包支付属于第三方调用,若抢到红包后同步调用红包支付,系统调用链又长又慢,所以红包占有和红包发放异步拆分是必然。拆分后,红包占有只需操作 Redis,响应性能已不是问题。
3、怎么提高系统处理能力
从上述分析可知,目前系统的压力都会集中在红包发放这个环节,因为用户抢到红包时,我们只是同步告知用户已抢到红包,然后异步去发放红包,因此用户并不会立即收到红包(受红包发放 Worker 处理能力和微信服务压力制约)。若红包发放的 Worker 处理能力较弱,那么红包发放的延迟就会很高,体验较差。
如抢红包流程图中所示,我们采用一组 Worker 去消费任务队列,并调用红包支付 API,以及数据持久化操作(后续对账)。尽管红包发放调用链又长又慢,但是注意到这些 Worker 是 无状态 的,所以可以通过增加 Worker 数量,以横向扩展提高系统的处理能力。
4、怎么保证数据一致性
其实,红包发放延时我们可以做到用户无感知,但是若红包发放(流程②)失败了,已经告知用户抢到红包,但是却木有发,估计他杀人的心都有了。根据 CAP 原理,我们无法同时满足数据一致性、数据可用性、分区耐受性,通常只需做到数据最终一致性。
为了达到数据最终一致性,我们就引入了重试机制,生成一个全局唯一的外部订单号,当某单红包发放失败,就会放回任务队列,使得有机会进行发放重试,当然这一切都需要 API 做幂等处理。
Worker可靠性保障
这里必须将 Worker 可靠性单独说,因为它实在太重要了。Worker 的实现如下:
$maxTask = 1000;
$sleepTime = 1000;
while (true) {
while ($red = RedLogic::getTask()) {
RedLogic::doTask($red);
//处理多少个任务主动退出
$maxTask--;
if ($maxTask < 0) {
return EXIT_CODE_NORMAL;
}
}
//等待任务
usleep($sleepTime);
}
由于 Worker 需要常驻内存运行,难免会出现异常退出的情况(也有主动退出), 所以需要保持 Worker 一直处于运行状态。我们使用进程管理工具 Supervisor 来监控 Worker 的运行状态,同时管理 Worker 的数量,当任务队列出现堆积时,增加 Worker 数量即可。Supervisor 的监控后台如下:
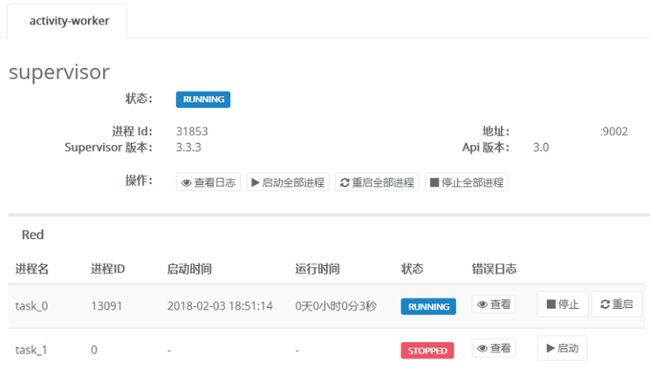
员工系统号散列
公司员工都用唯一一个系统号 emp_code(自增字段)标识,登录成功后返回 emp_code,系统后续所有交互流程都基于 emp_code,分享出去的红包也会携带 emp_code,为了保护员工敏感信息和防止恶意碰撞攻击,我们不能直接将 emp_code 暴露给前端,需要借助一个 token(无规律)的中间者来完成交互。
可选的方案
1、储存映射关系,时时查询
预先生成一个随机串 token,然后跟 emp_code 绑定,每次请求都根据 token 时时查询 emp_code。优点是可以定期更新,相对安全,缺点是性能不高。
2、建立映射关系函数,实时计算
建立一个映射关系函数,如 hash 散列或者加密解密算法,能够根据 emp_code 生成一个无规律的字符串 token,并且要能够根据 token 反映射出 emp_code。优点是需要存储介质存储关系,性能较高,缺点是很难做到定期失效并更新。
我们的方案
由于我们的红包活动只进行几天,所以我们选用了方案 2。对 emp_code 做了 hashids 散列算法,暴露的只是一串无规律的散列字符串。
hashids 是一个开源且轻量的唯一 id 生成器,支持 Java、PHP、C/C++、Python 等主流语言,PHP 想使用 hashids,只需composer require hashids/hashids命令安装即可。
然后,如下方式使用:
use Hashids\Hashids;
$hashids = new Hashids('salt', 6, 'abcdefghijk1234567890');
$hashids->encode(11002); //994k2kk
$hashids->decode('994k2kk'); //[11002]
需要说明的是,其中salt是非常重要的散列加密盐串,6表示散列值最小长度,abcde...7890为散列字典,太长影响效率,太短不安全。由于默认的散列字典比较长,decode 效率并不高,所以这里移除了大写字母部分。
语音点赞
语音点赞就是用户以语音的形式助力好友,核心技术其实是语音识别,而我们一般都会使用第三方语音识别服务。
可选的方案
1、客户端调用第三方服务识别
客户端直接调用第三方语音识别服务,如微信提供了 JS-SDK 的语音识别 API ,返回识别的语音文本的信息,并且已经经过语义化。优点是识别较快,且不许关注语音存储问题,缺点是不安全,识别结果提交到服务端之前可能被恶意篡改。
2、服务端调用第三方服务识别
先将录制的语音上传至存储平台,然后服务端调用第三方语音识别服务,第三方语音识别服务去获取语音信息并识别,返回识别的语音文本的信息。优点是识别结果较安全,缺点是系统交互较多,识别效率不高。
我们的方案
我们业务场景的特殊性,存在用户可助力次数的限制,所以无需担心恶意刷赞的情况,因此可以选用方案 1,语音识别的交互流程如下:
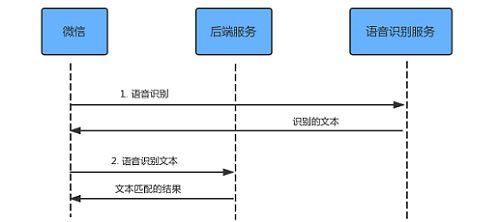
此时,整个语音识别流程如下:
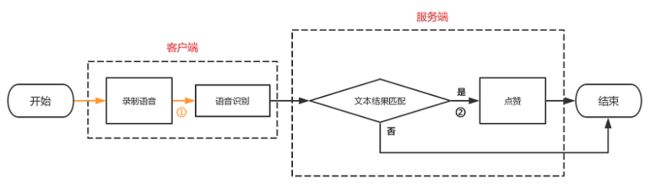
当然中国文字博大精深,语音识别的文本在匹配时,需要考虑容错处理,可以将文本转化为拼音,然后匹配拼音,或者设置一个匹配百分比,达到匹配值则认为语音口令正确。
需要注意的是,微信只提供 3 天的语音存储服务,若语音播放周期较长,则要考虑实现语音的存储。
其他
红包发放测试
我们使用了线上公账号进行红包发放测试,为了让线上公众号能够授权到测试环境,在线上的微信授权回调地址新增一个参数,将带有to=feature参数的请求引流到测试环境,其他线上流量还是保持不变,匹配规则如下:
# Nginx不支持if嵌套,所以就这样变通实现
set $auth_redirect "";
if ($args ~* "r=auth/redirect") {
set $auth_redirect "prod";
}
if ($args ~* "to=feature") {
set $auth_redirect "feature";
}
if ($auth_redirect ~ "feature") {
rewrite ^(.*)$ http://wx.t.ziroom.com/index.php last;
}
if ($auth_redirect ~ "prod") {
rewrite ^(.*)$ http://wx.ziroom.com/index.php last;
}
CDN缓存
由于本次活动力度较大,预估流量会比以往增加不少(不能再出现机房带宽打满的情况了,不然 >﹏<),静态页面占流量的很大一部分,所以静态页面在发布时都会放置一份在 CDN 上,这样回源的流量就很小了。
灾备方案
尽管做了很多准备,还是无法确保万无一失,我们在每个关键节点都增加了开关,一点出现异常,通过配置中心可以人工介入做降级处理。