声明:由于本人也是处于学习阶段,有些理解可能并不深刻,甚至会携带一定错误,因此请以批判的态度来进行阅读,如有错误,请留言或直接联系本人。
Week5摘要:1)Data cleaning;2)Data integration;3)Data transformation; 4)Data reduction; 5)Data discretization & Data Type Conversion
关键词:Dirty Data; Data preprocessing; 1) Data cleaning; Noise Data; Binning method; Clustering; Combined computer and human inspection; Regression; 2) Data integration; schema integration; Redundant Data; correlation analysis; Smoothing; 3) Data transformation;Aggregation; Generalization; Normalization; 4) Data reduction; Dimensionality reduction; Data Compression; Numerosity reduction; Discretization and concept hierarchy generation
本周正式进入Data Mining部分,本周lecture重点内容已在摘要中显示,在此不再赘述。在进入主要内容前,我们先要提出几个问题,来为更好的理解本周内容做个铺垫。
在实际工程环境中,数据来源纷繁复杂,因此造成数据之间的格式、内容之间千差万别,且由于有在数据录入时就录入错误数据,或者由于运输、存储过程中硬盘的损坏、病毒的侵扰,造成数据错误、缺失等情况,所以我们说原始数据一般是脏数据(Dirty),需要经过预处理(preprocessing)才能得到可以供实际操作使用的数据。
问题一:Why Data Preprocessing?
1)在收集到的大数据中,有些数据是不完整的(incomplete),比如:lacking attribute values, lacking certain attributes of interest, or containing only aggregate data(e.g., occupation=“”)。
2)有些数据是含有干扰的(noise),比如,containing errors or outliers(e.g., Salary=“-10”)。
3)有些数据虽为同类数据,但是由于来源不同,输入方式不同,所以造成它们的格式或命名不同,即不一致(inconsistent),比如,containing discrepancies in codes or names(e.g.,Age=“42” Birthday=“03/07/1997”; e.g., Was rating “1,2,3”, now rating “A, B, C”; e.g., discrepancy between duplicate records)
问题二:Why is Data Dirty?
1)Incomplete data comes from
1.1)n/a data value when collected
1.2)different consideration between the time when the data was collected and when it is analyzed.
1.3)human/hardware/software problems
2)Noisy data comes from the process of data
2.1)collection
2.2)entry
2.3)transmission
3)Inconsistent data comes from
3.1)Different data sources
3.2)Functional dependency violation
问题三:Why Is Data Preprocessing Important?
1)No quality data, no quality mining results!
1.1)Quality decisions must be based on quality data(e.g., duplicate or missing data may cause incorrect or even misleading statistics.)
1.2)Data warehouse needs consistent integration of quality data
2)Data extraction, cleaning, and transformation comprises the majority of the work of building a data warehouse.
3)Also a critical step for data mining.
Data cleaning
数据清理的主要任务是:
1)Fill in missing values (填补缺省值,防止在数据处理时由于空缺造成程序报错)
2)Identify outliers and smooth out noisy data(去除异常值,使异常值不影响数据操作以及后面的数据分析及决策)
3)Correct inconsistent data(将不同格式的相同类型的数据统一标准化)
4)Resolve redundancy caused by data integration(删减因数据整合产生的冗余数据,使得数据库或数据仓库更加轻便整洁)
问题四:数据缺失是由哪些原因造成的呢?
1)Data is not always available
E.g., many tuples have no recorded value for several attributes, such as customer income in sales data
- Missing data may be due to
a.equipment malfunction
b.inconsistent with other recorded data and thus deleted
c.data not entered due to misunderstanding
d.certain data may not be considered important at the time of entry
e.not register history or changes of the data
3)Missing data may need to be inferred.
f.Many algorithms need a value for all attributes
g.Tuples with missing values may have different true values
问题五:当数据缺失时,该怎么处理?
1)Ignore the tuple: usually done when class label is missing
2)Fill in the missing value manually
3)Fill in it automatically with
a.a global constant : 例如设置缺省值为“unknown”或者设置一个新类(这个新类可能只有特征参数,但是没有特征值)
b.the attribute mean(如果这一列的attribute是numerical,将所有值相加求出平均值,以平均值作为缺省值的值)
c.the attribute mean for all samples belonging to the same class(数据中的attributes可能还有细分,例如性别年龄等,例如一个叫John的20岁青年的工资为缺省,那么,我们可以通过求出男性,20-30岁的平均收入,以这个平均收入来作为John的收入衡量)
d.the most probable value: inference-based such as Bayesian formula or decision tree(利用机器学习理论来科学推断缺省值)
问题六:什么是干扰数据(Noise Data),它的产生原因是什么?
Noise: random error or variance in a measured variable
Incorrect attribute values may due to
A.faulty data collection instruments
B.data entry problems
C. data transmission problems
D. technology limitation
E. inconsistency in naming convention
问题七:怎么处理干扰数据?
1)Binning method(分箱方法使得值是“相邻”的,可以使得局部平滑)
a.first sort data and partition into (equi-depth) bins
b.then one can (1)smooth by bin means, (2)smooth by bin median, (3)smooth by bin boundaries, etc.
2)Clustering(即将相似的聚类在一起)
a.detect and remove outliers
3)Combined computer and human inspection
a.detect suspicious values and check by human (e.g., deal with possible outliers)
4)Regression
a.smooth by fitting the data into regression functions
其他还有需要进行数据清洗的情况:1)duplicate records; 2)incomplete data: 3)inconsistent data
Data Integration
定义:combines data from multiple sources into a coherent store
这里介绍一种schema integration,它是针对relational data而设计的。由于数据来源的纷繁复杂,所以同种数据可能采用不同命名方式,因此会产生冗余,通过correlation analysis来对不同schema的相类似的table部分进行检测,来确定是否为相同的数据(因为schema 和ER diagram是可以相互转化的,而同一个ER diagram根据设计者的不同可以设计成多种schema,因此笔者猜测,将schema还原成ER diagram然后通过correlation analysis对相同的table进行检测)。
对于冗余的来源和检测:
1)Redundant data occur often when integration of multiple databases
a.The same attribute may have different names in different databases
b.One attribute may be a “derived” attribute in another table, e.g., annual revenue
2)n Redundant data may be able to be detected by
a.correlational analysis
Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality
Data transformation
通过数据转换,使得数据更加利于后续的挖掘、分析过程,具体操作包括:
1)Smoothing: remove noise from data(操作包括,分箱,聚类,Combined computer and human inspection,回归)
2)Aggregation: summarization, data cube construction
3)Generalization: concept hierarchy climbing
4)Normalization: scaled to fall within a small, specified range
a.min-max normalization

b.z-score normalization
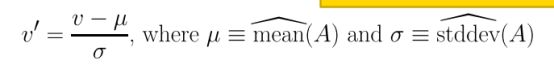
c.normalization by decimal scaling
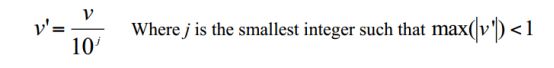
5)Attribute/feature construction
a.New attributes constructed from the given ones
Data Reduction
由于在大数据时代下,数据量十分巨大,且数据趋向于多维度发展。如果对这些数据不加任何预处理的情况西进行数据挖掘,那么任务量将会十分巨大。因此,需要对一些无足轻重的数据进行筛减。
定义:Data reduction:Obtain a reduced representation of the data set that is much smaller in volume but yet produce the same (or almost the same) analytical results
策略:
1)Dimensionality reduction—remove unimportant attributes
2)Data Compression
3)Numerosity reduction—fit data into models
4)Discretization and concept hierarchy generation
1)Dimensionality reduction:
即使数据量十分庞大,但是随着维度的增长,数据密度也会变得越来越稀疏,进而产生维度灾难(curse of dimensionality)。因此,Reduce dimensionality of the data, yet still maintain the meaningfulness of the data。
Dimensionality reduction methods:
(1)eature selection: choose a subset of the features
(1.1)Feature selection (i.e., attribute subset selection):
(1.1.1)Select a minimum set of features such that the probability distribution of different classes given the values for those features is as close as possible to the original distribution given the values of all features
(1.1.2)reduce # of patterns in the patterns, easier to understand
(1.2)Heuristic methods (due to exponential # of choices):
(1.2.1)step-wise forward selection
(1.2.2)step-wise backward elimination
(1.2.3)combining forward selection and backward elimination
(1.2.4)decision-tree induction
(2) Feature extraction: create new features by combining new ones
2)Data Compression:
(1)String compression
(1.1) There are extensive theories and well-tuned algorithms
(1.2) Typically lossless
(1.3) But only limited manipulation is possible without expansion
(2) Audio/video compression
(2.1) Typically lossy compression, with progressive refinement
(2.2) Sometimes small fragments of signal can be reconstructed without reconstructing the whole
(3) Time sequence is not audio
(3.1) Typically short and vary slowly with time
3)Numerosity reduction—fit data into models
(1)Parametric methods
(1.1) Assume the data fits some model, estimate model parameters, store only the parameters, and discard the data (except possible outliers)
(1.2) Log-linear analysis: obtain value at a point in m-D space as the product on appropriate marginal subspaces
(2) Non-parametric methods
(2.1) Do not assume models
(2.2) Major families: histograms (binning), clustering, sampling
4)Discretization and concept hierarchy generation
离散化针对哪些数据类型呢?
1)Nominal/categorical — values from an unordered set
1.1)Profession: clerk, driver, teacher, …
2)Ordinal — values from an ordered set
2.1)WAM: HD, D, CR, PASS, FAIL
3)Continuous — real numbers, including Boolean values
4)Array
5)String
6)Objects
一般的数据预处理,涉及的离散数据到连续数据,以及连续数据到离散数据比较多,因此:
- Continuous values -> discrete values
1.1) Removes noise
1.2) Some ML methods only work with discrete valued features
1.3) Reduce the number of distinct values on features, which may improve the performance of some ML models
1.4) Reduce data size - Discrete values -> continuous values
2.1) Smooth the distribution
2.2) Reconstruct probability density distribution from samples, which helps generalization
具体的连续数据离散化方式是,reduce the number of values for a given continuous attribute by dividing the range of the attribute into intervals. Interval labels can then be used to replace actual data values。
采用的方法有:1)Binning/Histogram analysis; 2)Clustering analysis; 3)Entropy-based discretization
分箱法有两种指导思想:
1)Equal-width (distance) partitioning:
1.1)Divides the range into N intervals of equal size: uniform grid
1.2)n if A and B are the lowest and highest values of the attribute, the width of intervals will be: W = (B –A)/N.
1.3)The most straightforward, but outliers may dominate presentation
1.4)Skewed data is not handled well.
2)Equal-depth (frequency) partitioning:
2.1)approximately same number of samples
2.2)Good data scaling
2.3)Managing categorical attributes can be tricky.
分箱法有两种算法范式:
1)Recursive Formulation
2)Dynamic Programming