声明:由于本人也是处于学习阶段,有些理解可能并不深刻,甚至会携带一定错误,因此请以批判的态度来进行阅读,如有错误,请留言或直接联系本人。
WEEK4 内容摘要(MapReduce):1)Design Pattern 4:Value-to-Key Conversion; 2)Miscellaneous
关键词:Value-to-Key Conversion; composite key; natural key; Boolean Text Retrieva; Inverted Index; Ranked Text Retrieval; TF; IDF; Miscellaneous; Counter; SequenceFile; Input Formats; Methods to Write MapReduce Jobs; Number of Maps and Reduces; MapReduce Advantages
1)Design Pattern 4:Value-to-Key Conversion
问题:如何将mapper output的(Key, list(value))中的value进行排序呢?
由于Reducer不支持对value的自动排序,所以我们有两种方式解决value排序的问题。
1)将拥有共同key的所有values缓存在内存中,然后进行排序。这个方法对于小型数据是可行的,但是对于大型数据,可能会产生内存溢出。
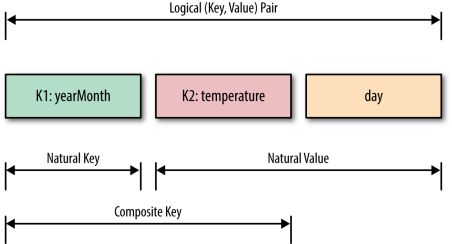
2)通过“Value-to-Key Conversion”这种方式,在Mapper中的pair (key, value)将value 与key相结合形成composite key (K, S),这里原本的key可以我们称为natural key。然后Mapper输出composite key,由MapReduce的Framework 来对这里的(K, S)中的S进行排序(framework sort by using the cluster nodes)。然而,对于multiple key-value pair我们怎么处理呢?通过设置partitioner来根据哈希值将不同的natural key所对应的composite key分派到各个Reducer当中,然而在分派的这个过程中,Framework对composite key进行sorting。
问题,MapReduce在现实生产中可以运用到哪些领域呢?
答:搜索引擎
这里有2中信息检索方式:1) Boolean Text Retrieval; 2) Ranked Text Retrieval
1)Boolean Text Retrieval:
特点:
(1)Each document or query is treated as a “bag” of words or terms. Word sequence is not considered
(2)Query terms are combined logically using the Boolean operators AND, OR, and NOT.
(2.1) E.g., ((data AND mining) AND (NOT text))
(3) Retrieval
(3.1) Given a Boolean query, the system retrieves every document that makes the query logically true.
(3.2) Called exact match
(4) The retrieval results are usually quite poor because term frequency is not considered and results are not ranked.
Boolean Text Retrieval一般是通过“ Inverted Index”来进行检索的, 这里 Inverted Index的特点是:
(1)The inverted index of a document collection is basically a data structure that
1.1)attaches each distinctive term with a list of all documents that contains the term.
1.2)The documents containing a term are sorted in the list
(2)Thus, in retrieval, it takes constant time to
2.1)find the documents that contains a query term.
2.2)multiple query terms are also easy handle as we will see soon.
以下可见Inverted Index的搜索方式,

这里设置一个query语句q,来查询blue,cat,egg ... two这些单词,分为以下3步来实施Inverted Index搜索(即图中的上,左,右三步):
(1)(vocabulary search): find each term/word in q in the inverted index.
(2)(results merging): Merge results to find documents that contain all or some of the words/terms in q.
(3)Step 3 (Rank score computation): To rank the resulting documents/pages, using:
(3.1)content-based ranking
(3.2)link-based ranking
问题,如何构建Inverted Index?
通过将input records (docid, doc)输入,输出(term, list(docid)), 其中list(docid)是排序好的,且即使一个term可能在一个docid中出现多次,只会在list(docid)中出现一次该term所对应的docid。
那么,如何在MapReduce中实现Inverted Index的构建呢?
(1)Mapper将(docid, doc)中的doc的每个term都列出来,然后组合成(term, docid)。记住,这里的term只会记录一次,不会按照出现的次数多少记录(即(1, ‘how long will I love you, as long as you father told you’), 那么只会记录(how, 1), (long , 1), (will, 1), (I, 1), (love, 1), (as, 1), (father, 1), (told, 1))。
(2)在Reducer端,收到的是(term, list(docid)), 然而这里的docid们是未经排序的,所以我们需要给他们排序,然而这里的排序是在Reducer段的memory中进行排序的,所以我们需要注意最长的list(docid)不能大于内存最大容量。
这里有两个缺点:1)Inefficient; 2)docids are sorted in reducers(这里我们可否用value-to-key方法进行改进呢?)
总结:Boolean Text Retrieval 可以从documents中提取出关键字,并将有相同关键字的document id进行整合。当用户通过关键字进行搜索的时候,通过AND, OR和NOT的方式,来筛选出用户所要求的内容,但是这里有一个缺点,就是这种关键字搜索时没有权重的,它只是按照数据库中document存储的顺序(即ID的顺序)来展示出来,因此此种算法对用户而言效率很低。(例如,用户搜索:“张三和李四”, 如果数据库下的document id = (1,7,8,9...119965)含有“张三和李四”的关键词,那么,网页就是按照id顺序来显示。)
2)Ranked Text Retrieval
在说明“Ranked Text Retrieval”之前,需要引入一些名词:
(1)weight: 即term在全文(这里的全文指的时所有的documents的集合)中的权重。
(2)TF: Term frequency,指的是某一个给定的词语在该文件中(即单一的本地文件)出现的频率,所以TF的作用域时local的。
(3)IDF: Inverse document frequency,是一个词语普遍重要性的度量,某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到,因为它的取值是关乎总文件数的,所以IDF的作用域是global的。
在这里,Terms that appear often in a document should get high weights;Terms that appear in many documents should get low weights。

这里我们可以理解为W = TF*IDF。

上式子中分子是该词在文件 dj中的出现次数,而分母则是在文件 dj中所有字词的出现次数之和。
如何在MapReduce中构建Ranked Text Retrieval的Index呢?

这里Reducer input的是(term, list(docid, term_frequency)), 输出的是(term, list(docid, weight))

在这里,有两个缺点显而易见:
(1)所有的document id是在Reducer中排序的(占用大量内存);
(2)因为要计算weight,所以先要计算IDF,然而要计算IDF就需要知道所有包含该term的文件的数(即document frequency)和总的document的数量,所以内存需要buffer所有的(term, (docid, term_frequency))来计算document frequency(占用大量内存,可能会造成溢出导致任务失败)。
要解决以上两个问题,分作两步:
第一步:使用value-to-key方法将(term, docid)组合为composite key,使得docid不在Reducer中被排序。
第二步:在这里我们形成了新的(list(term, docid), list(term_frequency ))我们姑且称之为bag,由于partitioner的设置,所有相同term的bag被同一个Reducer索取(假设一个Reducer只处理一个关键词term的数据)。但是,在Reducer我需要知道所有包含该term的document的数量和总的document的数量,于是,我们仿照order-inversion的方式,设置一个special pair,预先将所有被遍历的文件数,以及包含该term的文件数都打包起来,最先发给对应的Reducer。这样的话IDF的计算就方便了。
总结:使用Ranked Text Retrieval方便点在于搜索会有权重比较,权重高的会优先显示,这样的话用户搜索到其想要的东西的概率会更高,增加用户体验,且改进方法使得处理速率更高。
2)Miscellaneous
这里介绍几个MapReduce的几个功能:
(1)Counter:
1)Hadoop maintains some built-in counters for every job.
2)Several groups for built-in counters
2.1)File System Counters – number of bytes read and written
2.2)Job Counters – documents number of map and reduce tasks launched, number of failed tasks
2.3)Map-Reduce Task Counters– mapper, reducer, combiner input and output records counts, time and memory statistics
(2)SequenceFile:
1)File operations based on binary format rather than text format
2)SequenceFile class prvoides a persistent data structure for binary key-value pairs, e.g.,
2.1)Key: timestamp represented by a LongWritable
2.2)Value: quantity being logged represented by a Writable
3)Use SequenceFile in MapReduce:
3.1)job.setinputFormatClass(SequenceFileOutputFormat.class);
3.2)job.setOutputFormatClass(SequenceFileOutputFormat.class);
3.3)In Mapreduce by default TextInputFormat
(3)Input Formats:
1)InputSplit
1.1)A chunk of the input processed by a single map
1.2)Each split is divided into records
1.3)Split is just a reference to the data (doesn’t contain the input data)
2)RecordReader
2.1)Iterate over records
2.2)Used by the map task to generate record key-value pairs
3)As a MapReduce application programmer, we do not need to deal with InputSplit directly, as they are created in InputFormat
4)In MapReduce, by default TextInputFormat and LineRecordReader
(4)Methods to Write MapReduce Jobs:
1)Typical – usually written in Java
1.1)MapReduce 2.0 API
1.2MapReduce 1.0 API
2)Streaming
2.1)Uses stdin and stdout
2.2)Can use any language to write Map and Reduce Functions(C#, Python, JavaScript, etc…)
3)Pipes
3.1Often used with C++
4)Abstraction libraries
4.1Hive, Pig, etc… write in a higher level language, generate one or more MapReduce jobs
(5)Number of Maps and Reduces
1)Maps
1.1)The number of maps is usually driven by the total size of the inputs, that is, the total number of blocks of the input files.
1.2The right level of parallelism for maps seems to be around 10-100 maps per-node, although it has been set up to 300 maps for very cpu-light map tasks.
1.3)If you expect 10TB of input data and have a blocksize of 128MB, you’ll end up with 82,000 maps, unless Configuration.set(MRJobConfig.NUM_MAPS, int) (which only provides a hint to the framework) is used to set it even higher.
2)Reduces
2.1)The right number of reduces seems to be 0.95 or 1.75 multiplied by (
2.2)With 0.95 all of the reduces can launch immediately and start transferring map outputs as the maps finish. With 1.75 the faster nodes will finish their first round of reduces and launch a second wave of reduces doing a much better job of load balancing.
2.3)Use job.setNumReduceTasks(int) to set the number
(6)MapReduce Advantages:
1)Automatic Parallelization:
1.1)Depending on the size of RAW INPUT DATA instantiate multiple MAP tasks
1.2)Similarly, depending upon the number of intermediate
2)Run-time:
2.1)Data partitioning
2.2)Task scheduling
2.3)Handling machine failures
2.4)Managing inter-machine communication
3)Completely transparent to the programmer/analyst/user