本博客在http://doc001.com/同步更新。
本文主要内容翻译自MySQL开发者Ulf Wendel在PHP Submmit 2013上所做的报告「Scaling database to million of nodes」。翻译过程中没有全盘照搬原PPT,按照自己的理解进行了部分改写。水平有限,如有错误和疏漏,欢迎指正。
本文是系列的第四篇,本系列所有文章如下:
- 百万节点数据库扩展之道(1): 传统关系型数据库
- 百万节点数据库扩展之道(2): NoSQL理论与Amazon Dynamo
- 百万节点数据库扩展之道(3): Google Bigtable
- 百万节点数据库扩展之道(4): Google Spanner
- 百万节点数据库扩展之道(5): NoSQL再讨论
Google Spanner
概述
Google Spanner是继承自Bigtable的全球分布式数据库。
Bigtable之后,Google设计了MegaStore。MegaStore构建在Bigtable之上,提供数据中心间的同步、强一致性的副本,它还进一步提供了事务支持和SQL查询语言。MegaStore很快变得很流行,开发者们显然很喜欢这种跨数据中心的一致性保证,尽管副本同步并不是很快。这导致Google进一步开发了Spanner。Spanner首先被应用于F1广告系统。在这之前,F1使用的是MySQL数据库。MySQL的分区过于复杂,且副本数据同步是异步进行的,很难故障转移。
Spanner有以下特征:
- 分布式键值存储
- 分布式多维映射表:(key[,timestamp]) -> string
- 格式化的半关系表
- ACID事务
- 声明式SQL查询语言
- MapReduce
- 独一无二的TrueTime API
- 跨数据中心的同步副本
系统视图
一个Spanner部署称为一个宇宙(universe)。universe monitor负责监控和调试系统。
一个universe包含很多地区(zone)。zone是物理隔离的单位,每一个数据中心可以有一个或多个zone,副本操作在zone之间进行。
每一个zone由一个zone master和100~1000个span server组成。zone master有一个热备。
客户端向位置代理(location proxy)查询数据。
GFS分布式文件系统被Colossus取代。一个安置驱动(placement driver)负责均衡数据。

分层数据模型
在分布式系统中,join操作代价昂贵。受限于物理规律,再精细的查询优化也无法避免join操作中的网络数据传输。在全球分布式数据库中,大量数据的传输代价更是极度昂贵。因此,节点之间巧妙的位置协调是必须的,两个经常关联的表在物理上应该存储在一起,以较少甚至消除join操作的网络通信代价。
为了做到这点,Spanner中可以将关联的两个表定义为一个父表和一个派生表,派生表必须将父表的主键作为它自己主键的前缀。下图的例子中,就定义了一个父表——用户表和一个派生表——专辑表。
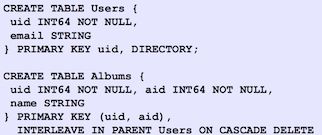
子表和目录
由于Spanner和Bigtable一样,按照行健存储数据,前缀的trick能够保证父表和派生表的关联记录在物理存储层面上紧挨在一起。例如,uid = 1的用户表行后紧跟着所有uid = 1的专辑表行。这使得join操作被转化为更廉价的磁盘扫描操作。
Spanner分区数据时充分尊重数据模型中的分级结构。这些分区被称之为目录(directory)。负载均衡和数据分布以目录为基础。
每一个子表(tablet)是目录的容器,包含多个频繁一起访问的目录。注意,这里的tablet概念不同于Bigtable中的tablet。
ACID事务完全支持
Spanner除支持快照读外,还支持ACID事务读写操作!!!所有的读操作都是非阻塞、无锁的。读操作使用了多版本技术,版本号就是时钟时间。
写操作使用两阶段锁(后面会说明)。这个选择有利于MapReduce作业。纯粹的多版本并发控制机制难以处理长时间运行的事务。因为其验证操作发生在事务结束时,想象一些,你运行了10分钟的MapReduce作业,在完成时才看到冲突,心里肯定会F**K...
TrueTime
想象一下,你正在运行一个广告系统,该系统有一张竞价表和一张点击表。为了提高性能,你应该将点击表按照区域进行分区。来自欧洲用户的点击应该被欧洲的服务器记录,同理,美国用户的点击应该被美国的服务器记录。
进一步,我们构造一个两个事务需要被正确排序的场景。这两个事务在不同的大陆由不同的服务器执行。第一个事务新建了一个竞价,第二个事务记录这个竞价的一次点击。紧接着,第三个事务需要去读取第二个事务的结果,显然它也需要知道第一个事务的结果。因此,这些事务的顺序必须是一定的,只能是事务一、事务二、事务三,不能乱套。
在Dynamo中,我们无法简单地使用墙上时间(wall clock),因为这些时间并不是完全同步的。Dynamo为此选择了向量钟。
向量钟的问题在于它们必须被每一个消息捎带,以检测依赖关系,在这个场景中是这样的:
- 事务T1执行,竞价在美国的服务器被创建
- 广告出现,用户在欧洲点击广告
浏览器中的广告必须包含T1的向量钟
JavaScript点击记录必须将向量钟发送给欧洲服务器的数据库 - 欧洲服务器使用事务T2写入点击信息
数据库将T2、T1的向量钟、自己的向量钟一起存储 - 读取T2事务也必须读取T1事务结果,因为T1发生在T2前
数据库必须检查向量钟之间的关系
你会发现,到处都是向量钟,整个过程的向量钟处理不能有一丁点出错。太糟糕了!
由于向量钟存在的问题,Google决定承担同步墙上时间的代价。如果墙上时间是单调递增(不允许出现跳跃)、全球可用的,那它可以被用于在全球范围内可靠地序列化事务。为了做到这一点,Google综合使用GPS和原子时钟开发了TrueTime服务,能够给出精确时间的精准估计。
TrueTime接口并不返回一个准确的时间,相反,返回一个准确时间的估计范围。这个时间误差在0~6ms间,90%的情况下小于2ms。
Spanner提供三个TrueTime接口:
- $TT.now()$:准确时间的估计区间[earliest,latest]
- $TT.after(t)$:如果t肯定已经过去了,返回真
- $TT.before(t)$:如果t时间还未到来,返回真
使用函数$t_{abs}(e)$标示事件e的绝对时间。TrueTime可以保证,对于一个调用$tt=TT.now()$,有$tt.earliest≤tabs(e_{now})≤tt.latest$,其中,e_{now}是现在调用的事件。
TrueTime在底层使用了GPS和原子时钟。TrueTime使用两种形式的计时方式是因为它们有不同的失败模式。GPS参考时间会受到天线、接收器失效等因素的影响。原子时钟与GPS、其它原子时钟无关,但是频率错误可能导致长时间的时间偏移。
TrueTime由每个数据中心的一组time master机器和每个机器上的timeslave saemon组成。大部分time master装有专用天线的GPS,其它的time master(Armageddon master)装备有原子时钟。所有master的时间参考值都会进行彼此校对。每个master也会交叉检查时间参考值和本地时间的比值,如果二者差别太大,就会把自己驱逐出系统。在同步期间,Armageddon master会表现出一个逐渐增加的时间不确定性,这是由时钟漂移引起的。而GPS master表现出的时间不确定性几乎接近于0。
每个机器使用一个本地的daemon从多个master校时,部分GPS master选自较远的数据中心,部分选择附近的数据中心,部分来自Armageddon master。为了受到错误的本地时钟干扰,那些时间误差频繁高于容忍限度的机器将会被系统驱逐。
在两次同步期间,一个daemon也会表现出逐渐增加的时间不确定性。本身deamon校准得到是一个时间范围,而deamon以最坏的情况估计时间,所以,时间范围不断在扩大。
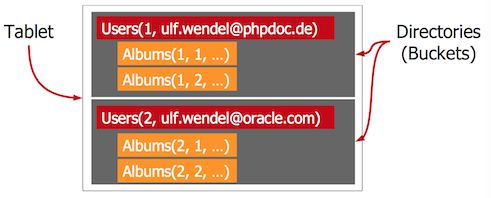
两阶段提交(two-phase commit,2PC)
Spanner的事务提交机制与2PC类似。2PC是一个分布式事务提交协议,包含准备、提交/终止两个阶段。
考虑一个多节点参与的事务。为了决定事务的结果,协调者(coordinator)发送一个准备请求给所有的参与者。参与者分别检查它们可以提交事务,还是需要终止事务。一旦参与者做出可以提交的决定,就回复可以提交,同时进入准备提交状态,这个状态就是不可逆转的。理想情况下,所有参与者都回复说可以提交,然后协调者就发送一个全局提交消息;否则,就发送全局终止消息。这就是2PC的执行过程。
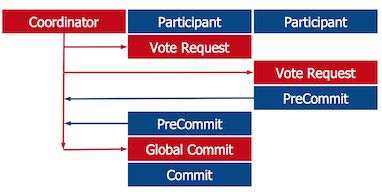
2PC是一个阻塞协议,在异步环境下会导致很多问题。
最严重的情况就是协调者在所有参与者都进入准备提交状态后崩溃了。参与者们在协调者恢复之前无法离开准备提交状态,因为它们不知道最终的决定是提交还是终止。并且,没有一个参与者收到了投票结果,因此,也无法互相通信进行询问。
2PC的一个改进协议是三阶段提交(three-phase commit,3PC)。3PC为事务设置了一个超时时间,超过这个时间直接终止事务。
写事务
Spanner使用TrueTime和Paxos对2PC进行了改进。写事务的流程如下:
- 请求锁
- 执行读操作,和幻影写(即先写数据但不提交)
- 获取事务启动时间$ctime_{now}=TT.now()=[t_{earliest},t_{latest}]$
- 使用Paxos多副本写
- 等待,直到$t_{latest}
- 确认提交
- 执行写操作
- 释放锁
当一个写事务启动,它会对获取一些锁,然后才进行读写。Spanner为事务获取一个启动时间戳的估计范围。写操作使用Paxos来写多个副本。如果一切顺利,再次检查时间,一直等待到估计的启动时间肯定过去了,才能确认提交。通常情况下,同步副本变化的时间肯定要比启动事件戳的估计范围要长,因此,实际上Spanner很少等待。这个设计其实保证了,同一个时间只存在一个事务提交数据,所有事务的提交时间严格递增。
另外一点就是,这个2PC运行在Paxos之上。Paxos至少需要三个节点才能达成提议,因此该系统至少有三个副本。既然Paxos能自动处理故障,2PC也不再需要额外的故障处理协议。Paxos最多能够承受1/3的节点失败,不超过这个数量,2PC不会阻塞。
写事务执行的系统视图
2PC中最棘手的问题是coordinator失败。在Spanner中,客户端充当了coordinator的角色。
在一个写事务的开始,客户端将读请求发送给tablet的leader,这个leader是Paxos选举出来的。每一个tablet的副本是一个paxos组。leader获取必要的锁,然后客户端执行读操作。
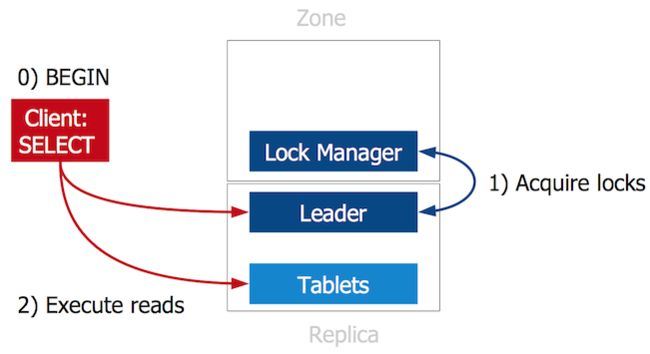
每一个span server包含一个participant leader组件,该组件和客户端交换心跳信息。
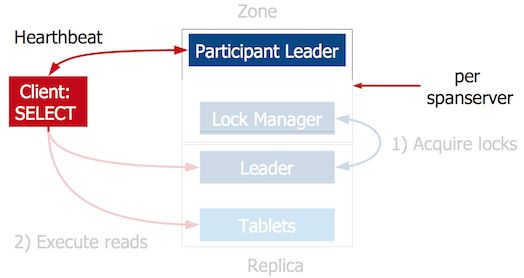
当客户端准备提交数据,就发起2PC,并成为coordinator。
如果客户端未成功发送keep alive消息,就可以认为coordinator已经失效,participant leader介入,解决阻塞。
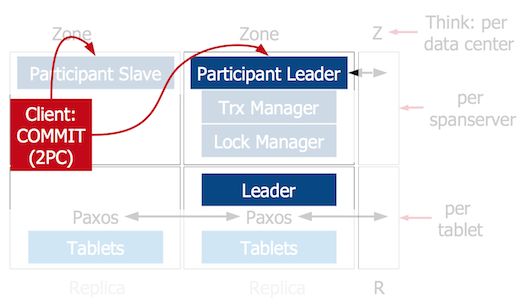
更多详细的细节请参见Spanner论文。
总结
Spanner并没有打破CAP理论,但是证明了,正确的工程设计能够将明显地推进CAP的边界,做到一致性、可用性和足够的分区容忍性。
Spanner实现的CAP程度如下(强>高>好):
- 一致性
- 强:显式同步副本
- 强:ACID事务
- 强:使用了Colossus文件系统
- 可用性
- 高:跨数据中心备份
- 高:可以实现全球分布
- 高:单分区副本延时性能很好
- 好:分区数高达50时延时仍然在可接受范围内
- 分区容忍性
- 高:Paxos
- 高:会话亚协议(session sub protocol)
未完待续...
接下来将是本系列的最后一篇,参见:
- 百万节点数据库扩展之道(5): NoSQL再讨论