1. 线性回归
模型
y表示预测结果
n表示特征的个数
xi表示第 i 个特征的值
θj表示第 j 个参数
h表示假设函数
正态方程
实践过程中,最小化MSE更简单
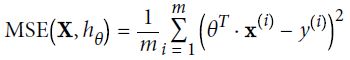
使得MSE最小的解为:
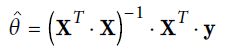
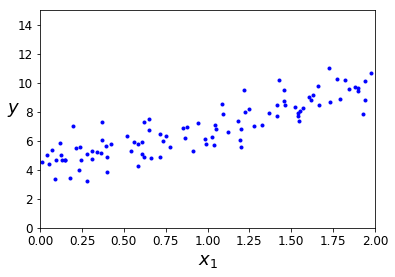
构造数据
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
plt.show()
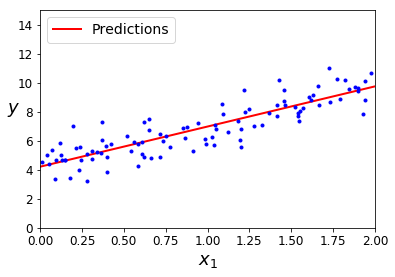
X_b = np.c_[np.ones((100, 1)), X] # add x0 = 1 to each instance
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
theta_best
'''
array([[3.9202609],
[2.9609808]])
'''
X_new = np.array([[0], [2]]) # x坐标轴的两端
X_new_b = np.c_[np.ones((2, 1)), X_new]
# 等同于: X_new_b = np.hstack((np.ones((2, 1)), X_new))
add x0 = 1 to each instance
y_predict = X_new_b.dot(theta_best)
y_predict
plt.plot(X_new, y_predict, "r-", linewidth=2, label="Predictions")
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.legend(loc="upper left", fontsize=14)
plt.axis([0, 2, 0, 15])
plt.show()
Sklearn
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
lin_reg.intercept_, lin_reg.coef_
# (array([3.9202609]), array([[2.9609808]]))
时间复杂度
正态方程需要计算矩阵X^T·X的逆,它是一个的n × n矩阵(n是特征的个数)。这样一个矩阵求逆的运算复杂度大约在到之间。
梯度下降
这种方法适合在特征个数非常多,训练实例非常多,内存无法满足要求的时候使用。
梯度下降的整体思路是通过的迭代来逐渐调整参数使得损失函数达到最小值。它计算误差函数关于参数向量的局部梯度,同时它沿着梯度下降的方向进行下一次迭代。当梯度值为零的时候,就达到了误差函数最小值 。
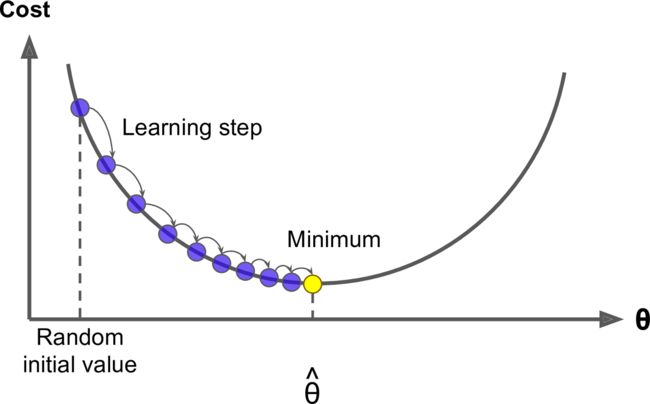
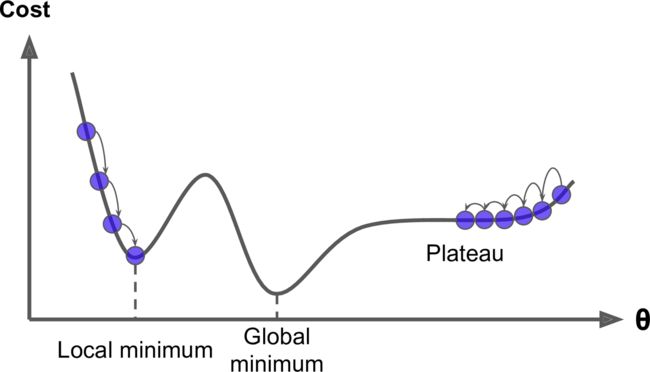
关键点:合理的步长、可能不是全局最优解,如下图。(但是,线性回归的均方差损失函数是凸函数)
下图展示了梯度下降在不同训练集上的表现。在左图中,特征 1 和特征 2 有着相同的数值尺度。在右图中,特征 1 比特征2的取值要小的多。左面的梯度下降可以直接快速地到达最小值,然而在右面的梯度下降第一次前进的方向几乎和全局最小值的方向垂直,并且最后到达一个几乎平坦的山谷,在平坦的山谷走了很长时间。它最终会达到最小值,但它需要很长时间。
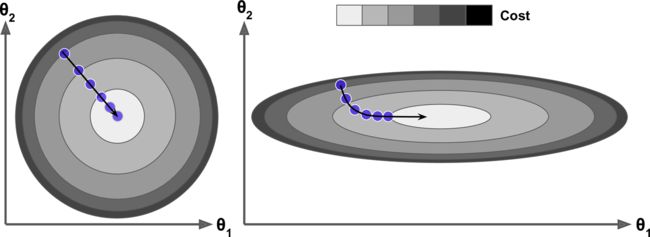 有无特征缩放的梯度下降
有无特征缩放的梯度下降
当使用梯度下降的时候,应该确保所有的特征有着相近的尺度范围(例如:使用Scikit Learn 的 StandardScaler 类),否则它将需要很长的时间才能够收敛。
批量梯度下降
使用梯度下降的过程中,需要计算每一个下损失函数的梯度。换句话说,你需要计算当变化一点点时(即偏导数),损失函数改变了多少。
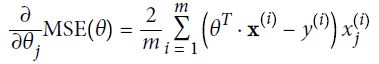
损失函数的梯度向量为:
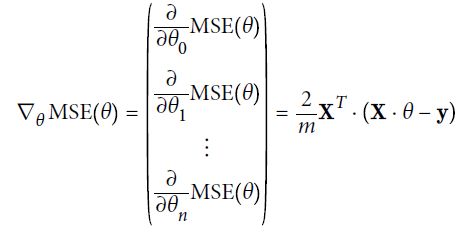
在这个方程中每一步计算时都包含了整个训练集
一旦求得了方向是上山的梯度向量,你就可以向着相反的方向去下山。这意味着从
eta = 0.1 # 步长
n_iterations = 1000 # 迭代次数
m = 100 # 总样本数
theta = np.random.randn(2,1)
for iteration in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
theta
# array([[3.9202609],
# [2.9609808]])
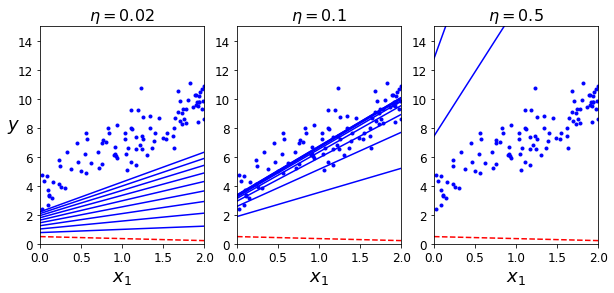
在不同学习率下,迭代前10步的区别:
theta_path_bgd = []
def plot_gradient_descent(theta, eta, theta_path=None):
m = len(X_b)
plt.plot(X, y, "b.")
n_iterations = 1000
for iteration in range(n_iterations):
if iteration < 10:
y_predict = X_new_b.dot(theta)
style = "b-" if iteration > 0 else "r--"
plt.plot(X_new, y_predict, style)
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
if theta_path is not None:
theta_path.append(theta)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0, 2, 0, 15])
plt.title(r"$\eta = {}$".format(eta), fontsize=16)
np.random.seed(42)
theta = np.random.randn(2,1) # random initialization
plt.figure(figsize=(10,4))
plt.subplot(131); plot_gradient_descent(theta, eta=0.02)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(132); plot_gradient_descent(theta, eta=0.1, theta_path=theta_path_bgd)
plt.subplot(133); plot_gradient_descent(theta, eta=0.5)
随机梯度下降
批量梯度下降的最要问题是计算每一步的梯度时都需要使用整个训练集,这导致在规模较大的数据集上,其会变得非常的慢。与其完全相反的随机梯度下降,在每一步的梯度计算上只随机选取训练集中的一个样本。
由于它的随机性,与批量梯度下降相比,其呈现出更多的不规律性:它到达最小值不是平缓的下降,损失函数会忽高忽低,只是在大体上呈下降趋势。随着时间的推移,它会非常的靠近最小值,但是它不会停止在一个值上,它会一直在这个值附近摆动,如下图。
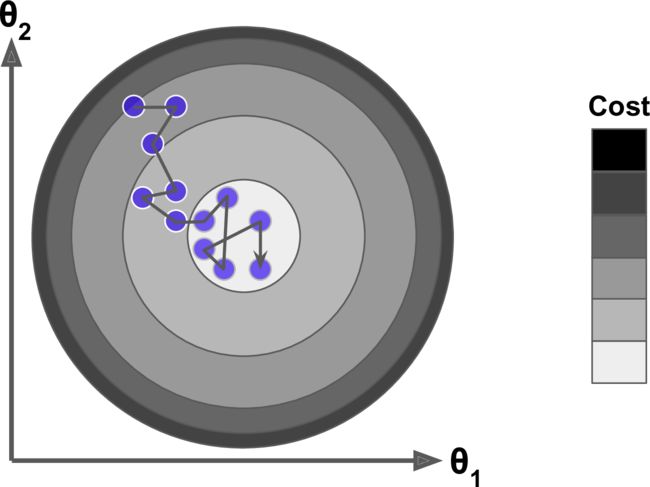
当损失函数很不规则时,随机梯度下降算法能够跳过局部最小值。因此,随机梯度下降在寻找全局最小值上比批量梯度下降表现要好。
虽然随机性可以很好的跳过局部最优值,但同时它却不能达到最小值。解决这个难题的一个办法是逐渐降低学习率。 开始时,走的每一步较大,然后变得越来越小,从而使算法到达全局最小值。 这个过程被称为模拟退火,因为它类似于熔融金属慢慢冷却的冶金学退火过程。 决定每次迭代的学习率的函数称为 learning schedule 。
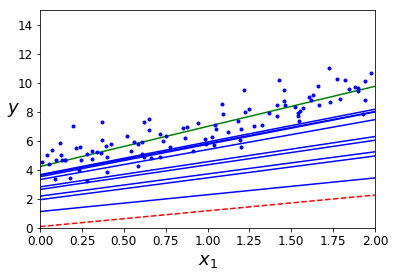
下面是原书的代码,有点奇葩:
theta_path_sgd = []
m = len(X_b)
np.random.seed(42)
n_epochs = 50
t0, t1 = 5, 50 # learning schedule hyperparameters
def learning_schedule(t):
return t0 / (t + t1)
theta = np.random.randn(2,1)
for epoch in range(n_epochs):
for i in range(m):
if epoch == 0 and i < 20:
y_predict = X_new_b.dot(theta)
style = "b-" if i > 0 else "r--"
plt.plot(X_new, y_predict, style)
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(epoch * m + i)
theta = theta - eta * gradients
theta_path_sgd.append(theta)
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
plt.show()
sklearn
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=50, penalty=None, eta0=0.1, random_state=42)
sgd_reg.fit(X, y.ravel())
sgd_reg.intercept_, sgd_reg.coef_
# (array([4.16782089]), array([2.72603052]))
小批量梯度下降
在迭代的每一步,批量梯度使用整个训练集,随机梯度时候用仅仅一个实例,在小批量梯度下降中,它则使用一个随机的小型实例集。
theta_path_mgd = []
n_iterations = 50
minibatch_size = 20
np.random.seed(42)
theta = np.random.randn(2,1) # random initialization
t0, t1 = 200, 1000
def learning_schedule(t):
return t0 / (t + t1)
t = 0
for epoch in range(n_iterations):
shuffled_indices = np.random.permutation(m)
X_b_shuffled = X_b[shuffled_indices]
y_shuffled = y[shuffled_indices]
for i in range(0, m, minibatch_size):
t += 1
xi = X_b_shuffled[i:i+minibatch_size]
yi = y_shuffled[i:i+minibatch_size]
gradients = 2/minibatch_size * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(t)
theta = theta - eta * gradients
theta_path_mgd.append(theta)
theta_path_bgd = np.array(theta_path_bgd)
theta_path_sgd = np.array(theta_path_sgd)
theta_path_mgd = np.array(theta_path_mgd)
plt.figure(figsize=(7,4))
plt.plot(theta_path_sgd[:, 0], theta_path_sgd[:, 1], "r-s", linewidth=1, label="随机梯度")
plt.plot(theta_path_mgd[:, 0], theta_path_mgd[:, 1], "g-+", linewidth=2, label="小批量梯度")
plt.plot(theta_path_bgd[:, 0], theta_path_bgd[:, 1], "b-o", linewidth=3, label="批量梯度")
plt.legend(loc="upper left", fontsize=16)
plt.xlabel(r"$\theta_0$", fontsize=20)
plt.ylabel(r"$\theta_1$ ", fontsize=20, rotation=0)
plt.axis([2.5, 4.5, 2.3, 3.9])
plt.show()
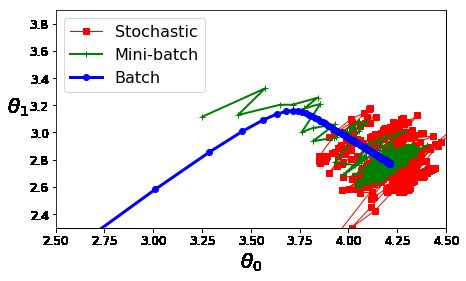
线性回归总结

2. 多项式回归
对于非线性数据,依然可以使用线性模型来拟合。 一个简单的方法是对每个特征进行加权后作为新的特征,然后训练一个线性模型在这个扩展的特征集。 这种方法称为多项式回归。
创建数据
np.random.seed(42)
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 0.5 * X **2 * X + 2 + np.random.randn(m, 1)
plot.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([-3, 3, 0, 10])
plt.show()
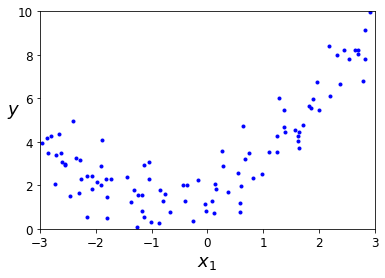
使用 Scikit-Learning的PolynomialFeatures类进行训练数据集的转换,让训练集中每个特征的平方(2 次多项式)作为新特征。
from sklearn.preprocessing import PolynomialFeatures
'''
PolynomialFeatures(degree=2, interaction_only=False, include_bias=True)
Generate a new feature matrix consisting of all polynomial combinations
of the features with degree less than or equal to the specified degree.
For example, if an input sample is two dimensional and of the form
[a, b], the degree-2 polynomial features are [1, a, b, a^2, ab, b^2].
interaction_only 是否包含ab
include_bias 是否包含1
'''
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X)
# X_poly的shape是100*2,[x, x^2]
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
lin_reg.intercept_, lin_reg.coef_
# (array([1.78134581]), array([[0.93366893, 0.56456263]]))
X_new=np.linspace(-3, 3, 100).reshape(100, 1)
X_new_poly = poly_features.transform(X_new)
y_new = lin_reg.predict(X_new_poly)
plt.plot(X, y, "b.")
plt.plot(X_new, y_new, "r-", linewidth=2, label="Predictions")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.legend(loc="upper left", fontsize=14)
plt.axis([-3, 3, 0, 10])
plt.show()
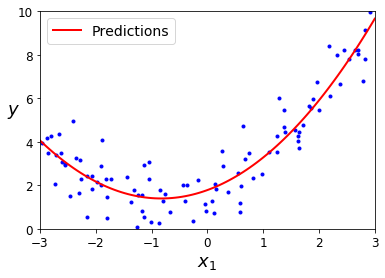
3. 学习曲线
过拟合、欠拟合是很常见的问题,那么我们该如何决定模型的复杂度呢?
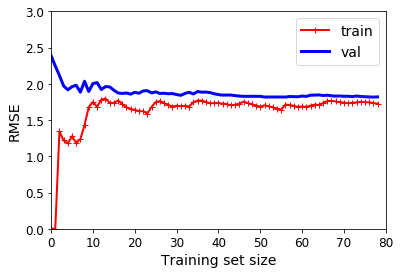
一种方法是观察学习曲线:画出在不同规模的训练集上,模型在所有训练集和测试集上的表现。为了得到图像,需要在训练集的不同规模子集上进行多次训练。
关于学习曲线很好的博文
线性回归的学习曲线:
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def plot_learning_curves(model, X, y):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=10)
train_errors, val_errors = [], []
for m in range(1, len(X_train)):
model.fit(X_train[:m], y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_val_predict = model.predict(X_val)
train_errors.append(mean_squared_error(y_train[:m], y_train_predict))
val_errors.append(mean_squared_error(y_val, y_val_predict))
plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train")
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")
plt.legend(loc="upper right", fontsize=14)
plt.xlabel("Training set size", fontsize=14)
plt.ylabel("RMSE", fontsize=14)
lin_reg = LinearRegression()
plot_learning_curves(lin_reg, X, y)
plt.axis([0, 80, 0, 3])
plt.show()
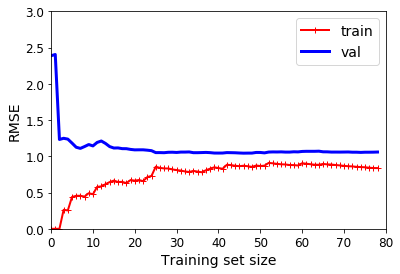
10阶多项式模型拟合的学习曲线
from sklearn.pipeline import Pipeline
polynomial_regression = Pipeline([
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("lin_reg", LinearRegression()),
])
plot_learning_curves(polynomial_regression, X, y)
plt.axis([0, 80, 0, 3])
plt.show()
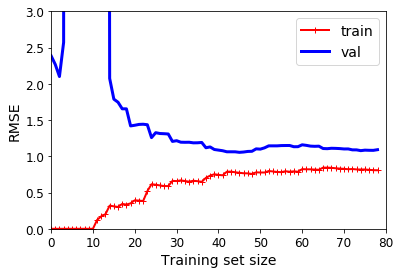
2阶多项式模型拟合的学习曲线
from sklearn.pipeline import Pipeline
polynomial_regression = Pipeline([
("poly_features", PolynomialFeatures(degree=2, include_bias=False)),
("lin_reg", LinearRegression()),
])
plot_learning_curves(polynomial_regression, X, y)
plt.axis([0, 80, 0, 3])
plt.show()
改善模型过拟合的一种方法是提供更多的训练数据,直到训练误差和验证误差相等。
偏差和方差的权衡
在统计和机器学习领域有个重要的理论:一个模型的泛化误差由三个不同误差的和决定:
- 偏差:泛化误差的这部分误差是由于错误的假设决定的。例如实际是一个二次模型,你却假设了一个线性模型。一个高偏差的模型最容易出现欠拟合。
- 方差:这部分误差是由于模型对训练数据的微小变化较为敏感,一个多自由度的模型更容易有高的方差(例如一个高阶多项式模型),因此会导致模型过拟合。
- 不可约误差:这部分误差是由于数据本身的噪声决定的。降低这部分误差的唯一方法就是进行数据清洗(例如:修复数据源,修复坏的传感器,识别和剔除异常值)。
4. 线性模型正则化 Regularized
过拟合的解决办法一个是减少特征,另一个是正则化。对于一个线性模型,正则化的典型实现就是约束模型中参数的权重(的大小)。 接下来我们将介绍三种不同约束权重的方法:Ridge 回归,Lasso 回归和 Elastic Net。
正则化好文
L1, L2 物理意义
Ridge回归(Tikhonov 正则化、L2正则化)
Ridge回归是线性回归的正则化版,在损失函数上直接加上一个正则项(的L2范数),使得学习算法不仅能够拟合数据,而且能够使模型的参数权重尽量的小。注意到,是没有被正则化的。
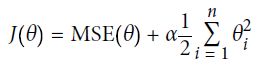
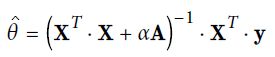
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver="cholesky", random_state=42)
ridge_reg.fit(X, y)
ridge_reg.predict([[1.5]])
# array([[1.55071465]])
'''
penalty 参数指的是正则项的惩罚类型。指定“l2”表明你要在损失函数上添加一项:权重向量L2范数平方的一半,这就是简单的岭回归。
'''
sgd_reg = SGDRegressor(max_iter=5, penalty="l2", random_state=42)
sgd_reg.fit(X, y.ravel())
sgd_reg.predict([[1.5]])
# array([1.13500145])
Lasso回归(L1正则化)
在损失函数上添加了一个正则化项,权重向量的 L1范数。
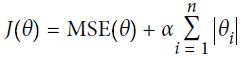
Lasso 回归的一个重要特征是它倾向于完全消除最不重要的特征的权重,Lasso回归自动的进行特征选择同时输出一个稀疏模型(即,具有很少的非零权重),有特征选择、降维的作用。
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
lasso_reg.predict([[1.5]])
# array([1.53788174])
弹性网络(ElasticNet)
弹性网络介于 Ridge 回归和 Lasso 回归之间。它的正则项是 Ridge 回归和 Lasso 回归正则项的简单混合。
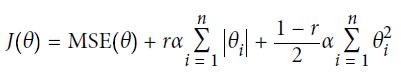
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5, random_state=42)
elastic_net.fit(X, y)
elastic_net.predict([[1.5]])
# array([1.54333232])
5. 逻辑回归
逻辑回归博文
逻辑回归的输出是概率估计,是在线性回归的基础上再加上一层logistic函数。
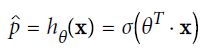
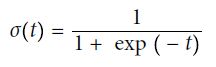
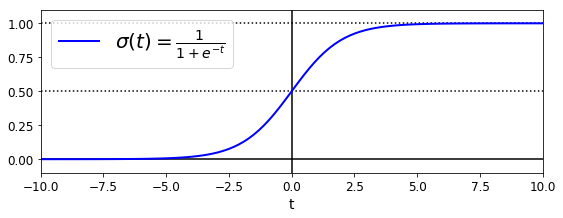
概率估计
损失函数
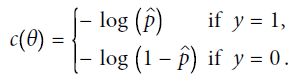
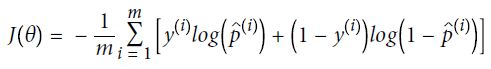
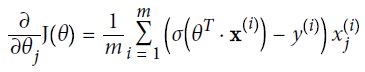
决策边界
iris数据集分析
from sklearn import datasets
iris = datasets.load_iris()
list(iris.keys())
# ['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename']
iris['data'].shape
# (150, 4)
# 四个特征分别是 花萼长度、花萼宽度、花瓣长度、花瓣宽度
pd.Series(iris['target']).value_counts()
# 2 50
# 1 50
# 0 50
# dtype: int64
print(iris.DESCR)
'''
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%[email protected])
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
- Many, many more ...
'''
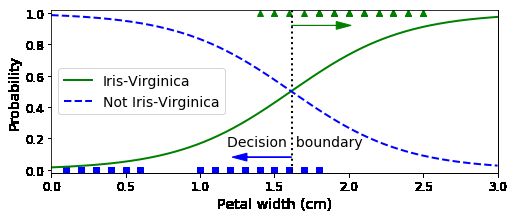
###### 首先用花瓣宽度进行逻辑回归
X = iris["data"][:, 3:] # petal width
y = (iris["target"] == 2).astype(np.int) # 1 if Iris-Virginica, else 0
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression(random_state=42)
log_reg.fit(X, y)
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
y_proba = log_reg.predict_proba(X_new)
decision_boundary = X_new[y_proba[:, 1] >= 0.5][0]
plt.figure(figsize=(8, 3))
plt.plot(X[y==0], y[y==0], "bs")
plt.plot(X[y==1], y[y==1], "g^")
plt.plot([decision_boundary, decision_boundary], [-1, 2], "k:", linewidth=2)
plt.plot(X_new, y_proba[:, 1], "g-", linewidth=2, label="Iris-Virginica")
plt.plot(X_new, y_proba[:, 0], "b--", linewidth=2, label="Not Iris-Virginica")
plt.text(decision_boundary+0.02, 0.15, "Decision boundary", fontsize=14, color="k", ha="center")
plt.arrow(decision_boundary, 0.08, -0.3, 0, head_width=0.05, head_length=0.1, fc='b', ec='b')
plt.arrow(decision_boundary, 0.92, 0.3, 0, head_width=0.05, head_length=0.1, fc='g', ec='g')
plt.xlabel("Petal width (cm)", fontsize=14)
plt.ylabel("Probability", fontsize=14)
plt.legend(loc="center left", fontsize=14)
plt.axis([0, 3, -0.02, 1.02])
plt.show()
decision_boundary
# array([1.61561562])
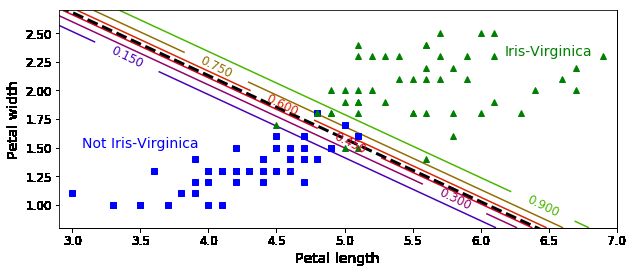
######用花瓣长度和宽度两个来特征进行判断
from sklearn.linear_model import LogisticRegression
X = iris["data"][:, (2, 3)] # petal length, petal width
y = (iris["target"] == 2).astype(np.int)
# C: 正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数。越小的数值表示越强的正则化
log_reg = LogisticRegression(C=10**10, random_state=42)
log_reg.fit(X, y)
x0, x1 = np.meshgrid(
np.linspace(2.9, 7, 500).reshape(-1, 1),
np.linspace(0.8, 2.7, 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_proba = log_reg.predict_proba(X_new)
plt.figure(figsize=(10, 4))
plt.plot(X[y==0, 0], X[y==0, 1], "bs")
plt.plot(X[y==1, 0], X[y==1, 1], "g^")
zz = y_proba[:, 1].reshape(x0.shape)
contour = plt.contour(x0, x1, zz, cmap=plt.cm.brg)
# contour的用法: https://blog.csdn.net/cymy001/article/details/78513712
left_right = np.array([2.9, 7])
boundary = -(log_reg.coef_[0][0] * left_right + log_reg.intercept_[0]) / log_reg.coef_[0][1]
plt.clabel(contour, inline=1, fontsize=12)
plt.plot(left_right, boundary, "k--", linewidth=3)
plt.text(3.5, 1.5, "Not Iris-Virginica", fontsize=14, color="b", ha="center")
plt.text(6.5, 2.3, "Iris-Virginica", fontsize=14, color="g", ha="center")
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.axis([2.9, 7, 0.8, 2.7])
plt.show()
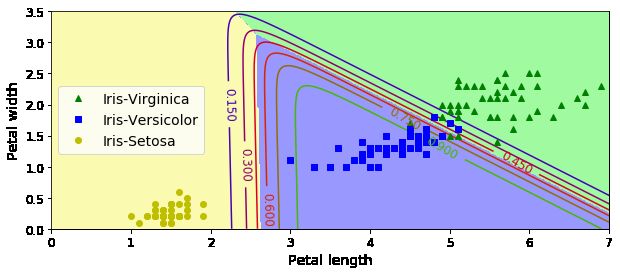
Softmax回归
Logistic 回归模型可以直接推广到支持多类别分类,不必组合和训练多个二分类器,其称为 Softmax 回归或多类别 Logistic 回归。
当给定一个实例时,Softmax 回归模型首先计算类的分数,然后将分数应用在Softmax函数(也称为归一化指数)上,估计出每类的概率。
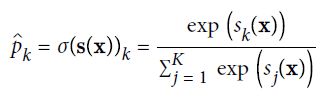
- 表示有多少类
- 表示包含样本x每一类得分的向量
- 表示给定每一类分数之后,实例属于第类的概率
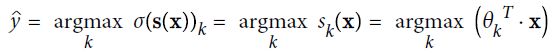
argmax 运算返回一个函数取到最大值的变量值。返回使最大时的的值。
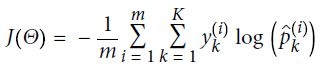
交叉熵博文
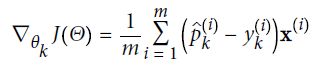
X = iris["data"][:, (2, 3)] # petal length, petal width
y = iris["target"]
softmax_reg = LogisticRegression(multi_class="multinomial",solver="lbfgs", C=10, random_state=42)
softmax_reg.fit(X, y)
x0, x1 = np.meshgrid(
np.linspace(0, 8, 500).reshape(-1, 1),
np.linspace(0, 3.5, 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_proba = softmax_reg.predict_proba(X_new)
y_predict = softmax_reg.predict(X_new)
zz1 = y_proba[:, 1].reshape(x0.shape)
zz = y_predict.reshape(x0.shape)
plt.figure(figsize=(10, 4))
plt.plot(X[y==2, 0], X[y==2, 1], "g^", label="Iris-Virginica")
plt.plot(X[y==1, 0], X[y==1, 1], "bs", label="Iris-Versicolor")
plt.plot(X[y==0, 0], X[y==0, 1], "yo", label="Iris-Setosa")
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
contour = plt.contour(x0, x1, zz1, cmap=plt.cm.brg)
plt.clabel(contour, inline=1, fontsize=12)
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.legend(loc="center left", fontsize=14)
plt.axis([0, 7, 0, 3.5])
plt.show()
练习
如果有一个数百万特征的训练集,应该选择哪种线性回归训练算法?
随机梯度下降、小批量梯度下降
如果内存够,也可以使用批量梯度下降
如果训练集中特征的尺度(scale)差异很大,那种算法会受到影响?
损失函数的形状会变得很细长,梯度下降算法收敛会很慢。训练之前应该应该将尺度归一化。
在有足够的训练时间下,是否所有的梯度下降都会得到相同的模型参数?
随机梯度和小批量梯度的结果会有略微区别,其他的区别不大。
假设使用批量梯度下降法,画出每一迭代的验证误差。当发现验证误差一直增大,接下来会发生什么?你怎么解决这个问题?
说明学习率太大了,减小学习率
当验证误差升高时,立即停止小批量梯度下降是否是一个好主意?
应该保留那个值,如果长时间没有更好的值,则停止。
假设使用多项式回归,画出学习曲线,在图上发现学习误差和验证误差之间有着很大的间隙。这表示发生了什么?什么方法可以解决这个问题?
过拟合了。减小多项式的最高项,或者正则化模型,即添加惩罚项。
假设使用岭回归,并发现训练误差和验证误差都很高,并且几乎相等。你的模型表现是高偏差还是高方差?这时你应该增大正则化参数 ,还是降低它?
高偏差,降低正则化参数。