人不理财,财不理你,码农每个月辛辛苦苦的加班熬夜,为了就是那一点加班费,没办法谁叫现在的房价高的离谱呢,手里捧着窝窝头,菜里没有一滴油!有一天在咖啡店遇到了一个叫彼得高手,聊了一些理财的观念,听完之后茅塞顿开,投资有道!比如70%来定存,30%的钱来买一些基金定投,长期坚持下去,收益会不错!

码农听完,两眼冒光,爬虫数据分析,这些对我是小菜一碟啊,说干就干!立马熬夜写了一个爬虫,把7000多支基金爬个遍。下面我们就爬取一批较好的基金,为下步投资分析做好准备。
01.页面分析
我们的数据来源是东方财富网,在这里可以查看所有开放式基金的基本信息,包括基金代码、基金简称、近两日的单位净值和累计净值、交易手续费等等,这个页面将作为我们的列表页数据来源。
首先我们尝试翻页,发现url是不变的,初步判定该页面数据栏部分是js动态加载。
接着我们寻找数据的 真实地址和页面参数,发现有一个名为“dt”的参数值是一长串数字不知从何获取。
更头疼的是这个数字还是随机 的...这个问题我们暂时搁置,先去分析下详情页情况。

我们随便选一支基金进去详情页,在详情页中间位置有一栏“净值”数据,点进去后就到了下图页面:
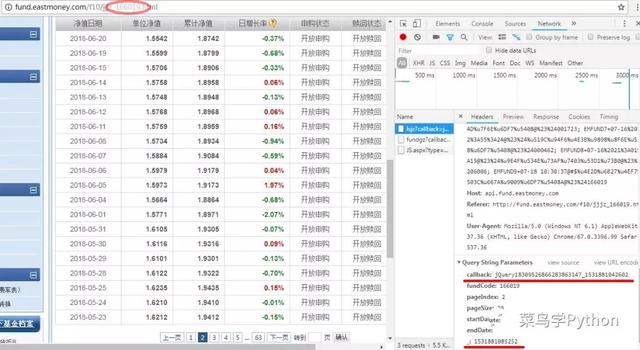
首先来分析下 基金净值详情页的url,经过几次尝试很容易发现不同基金净值详情页的url唯一的差别就在于基金代码,我们可以直接使用拼接字符串的方式获得基金净值详情页url,这就方便了很多。
再来看下这个页面中的历史净值数 据,与列表页一样,详情页的净值数据也是动态加载的,而且参数更加复杂——有两串随机生成的数字序列。
更令人头疼的是callback参数每隔几秒就会更新,初步判定可能是应用了某种基于时间戳的加密算法。对于我这种业余 小白来说,直接破解实在是过于困难,最终决定使用selenium来完成基金数据的爬取。
02.获取列表页信息
确定了基本的爬取思路后正式开始工作,使用selenium爬取列表页数据,通过观察页面可以看到数据栏下面有 一个“一键查看全部”按钮。
可以一次性展示所有开放式基金,点击右上角的“可购”选项,把当前无法交易的基金过 滤掉,最终得出了一张4137支的基金列表。

下面这段代码模拟了以上操作,然后我们使用page_source()方法获取页面的真实html数据,就可以使用常规方式 来解析提取数据并存入csv或excel等文件了。
原始的列表页数据有一些问题不便于直接使用,需要进行简单清洗:
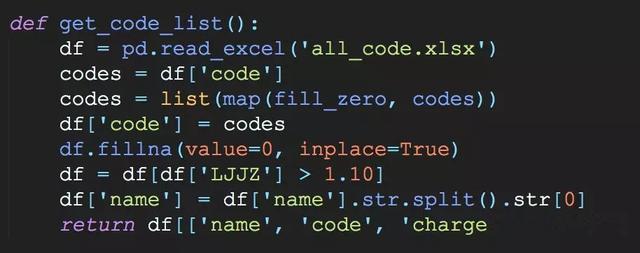
1).excel或csv文件中的基金代码会自动删除数字左侧的“0”。解决办法:左侧填0,补齐6位基金代码。
2).基金质量参差不齐,大量劣质基金没有爬取价值。解决办法:筛选出累计净值不小于1.1(收益不低于10%) 的基金代码进行详情页爬取(共2000多支)。
3).部分数据没有存储价值或重复存储。解决办法:筛选基金代码、基金简称、手续费三列数据传递给详情页爬虫程序。
4).这部分功能实现起来比较简单,我们直接上代码,其中fill_zero为自定义函数,用于基金代码左侧填0。
5).最终我们会 得到一个筛选后的dataframe数据,这份数据将传入爬虫程序用于详情页的爬取
在学习中有迷茫不知如何学习的朋友小编推荐一个学Python的学习裙【639584010】无论你是大牛还是小白,是想转行还是想入行都可以来了解一起进步一起学习!裙内有开发工具,很多干货和技术资料分享!
03.获取详情页信息
详情页的爬取是本次任务的重头戏,也是selenium发挥作用的主战场。
(1)加载导入selenium相关库
建立一个用于驱动chrome浏览器的对象,最长等待时间设置为10秒。

(2)翻页
我们模拟文本框中填写页数然后点击“确认”按钮的方式来实现翻页操作。
实现翻页操作的基本思路是等待文本框和“确认”按钮加载完成,清空文本框数据并向其中注入页码,点击执行翻页 操作、调用页面解析函数,如果遇到网络故障或其他原因导致响应超时,则继续调用本函数直到成功翻页为止,核心代码如下:
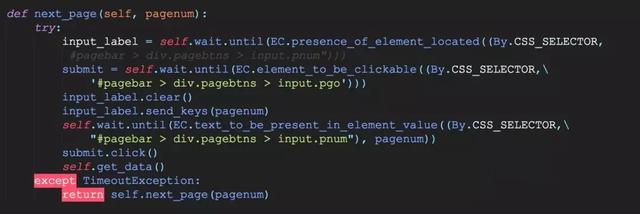
使用这种方式翻页必须要提前该基金净值数据的最大页数,这个数据可以从页面栏最后一页的text值来获取。

在这个环节我们还可以做一些筛选操作,比如最大页数小于13说明这支基金的运行时间不足一年,数据太少缺乏分 析价值,则该基金数据暂时不予爬取。
(3)解析
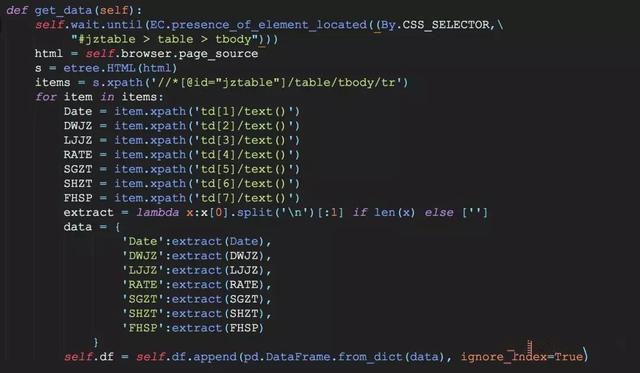
通过观察上面的图片我们发现,详情页的数据排列非常规整,在使用selenium获取了当前页面的html源代码后, 可以很方便地使用常规方式提取想要的全部数据,包括:净值日期、单位净值、累计净值、日增长率、申购状态、 赎回状态和分红配送
随后将数据添加到一个dataframe数据中,以基金为单位进行存储。不过我在爬取过程中遇 到了一个奇怪现象——使用pyquery无法定位目标数据,只好使用xpath来完成数据提取部分的操作。
04.多线程和去重
上述功能实现后,再来一个入口函数把它们组织起来,这个爬虫就基本完成了。但是使用selenium爬取数据有一个 致命缺陷就是——慢、非常慢!
一支基金的详情数据少则几十页,多则近两百页,平均爬取一支基金的所有数据大 概需要100秒,2000多支基金就需要20多万秒,一天一夜都爬不完,所以必须对爬虫进行提速,首先想到的就是使用多线程。
这里提供一个思路,将待爬取的基金代码列表平凡为N份(N为建立的线程数),然后通过下面这段代码建立多线程,其中start_multi_work为爬虫的入口函数,我在操作中设置了10个线程,提速效果还是非常明显的。

还有一个问题就是url去重了(实际上就是待爬取的基金代码去重),试想一下如果遇到网络故障或其他什么原因,爬取过程突然中断还要重头再来岂不很郁闷,所以我们要在每次启动爬虫之前对已经爬过的基金代码进行过滤。
对于本次任务来说使用redis比较合适,但是由于去重需求比较低我就粗暴地使用了txt文本来存储爬取过的基金代码,去重过程的核心代码如下,codes_left既为筛选后的待爬取基金列表。
当然,爬取过程中需要实时地讲已经爬取过的基金代码写入'check_already.txt'文件中。

05.关于后期分析
首先还是展示一下爬取成果吧,每个文件都是一支基金的历史数据。

基金的筛选其实就是收益与风险的综合考量过程,本人在这方面未入门径,不敢过多置喙,这里简单提两点:
1).计算基金的年化收益率
在我看来,年化收益10%已经算比较高的了,至少比市面上多数的理财产品收益要高,代码如下,其中df中包含了每支基金的历史数据。
def annual_return(df):
total_days = (df['交易日期'].iloc[-1] - df['交易日期'].iloc[0]).days total_value = df['累计净值'].iloc[-1] - df['累计净值'].iloc[0] principal = df['累计净值'].iloc[0]
return pow((total_value/principal), 365.0/total_days) - 1
2).计算基金的上涨概率
比如某支基金经历了500个交易日,其中400个交易日都是上涨的,那么它的历史上 涨概率就是0.8。
def rase_porp(df):
rase_num = df[df['涨跌幅'] >= 0].shape[0] all_num = df.shape[0]
return rase_num/all_num
以上两个参数并不专业,只是我个人的一些想法,至于选取哪些指标作为评价参数、每个指标达到什么水平才值得持有基金,这些问题就因人而异了。
最后强调一点,历史数据不能代表未来,在根据以往的数据预测未来方面,没有万无一失的方法,尤其是资本市场涉及变数太多,未来很难预测,收益与风险永远是成正比的。