StAX解析
除了DOM和SAX,还有一种解析XML文档的模式StAX。StAX的全称为The Stream API for XML。与SAX类似,StAX也是一边解析,一边处理,一边释放内存资源。
之所以将StAX与DOM、SAX分开来介绍,最重要的原因是,DOM和SAX都是推(PUSH)模式的解析模式,而StAX是拉(PULL)模式的解析模式(因此一般称StAX解析为XML Pull解析)。是推模式还是拉模式,取决于在解析的过程中谁处于主导地位,是服务器还是客户端。在推模式中,解析器自动解析XML文档而不受用户干预,但在拉模式中,用户可以主动控制解析的进行,也就是主动控制事件的处理,主动调用相应的方法。理解了什么是推模式和拉模式后,StAX解析的思想也不难理解:XML文档传递给解析器,通过next()方法触发文档解析事件,用户可以获取当前事件 ,也可以调用相应的方法 :
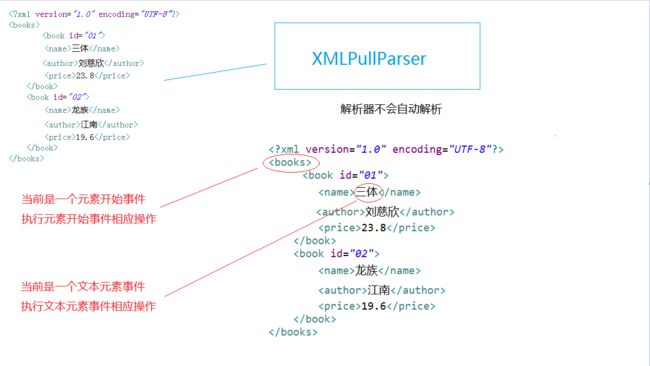
与SAX不同的是,XML Pull中用int型数据表示不同的事件:

如果想要查找龙族这本书的价格,代码为:
@Test
public void demo1() throws Exception {
XmlPullParserFactory xppFactory = XmlPullParserFactory.newInstance();//构建解析器工厂
XmlPullParser xpp = xppFactory.newPullParser();//构建解析器
xpp.setInput(new FileInputStream("books.xml"), "utf-8");//将XML文档和XML文档的编码方式传递给解析器
int event;
boolean isFound = false;//定义boolean变量用于标记
while ((event = xpp.getEventType()) != XmlPullParser.END_DOCUMENT) {//判断当前事件是否为文档结束事件
if (event == XmlPullParser.START_TAG && xpp.getName().equals("name")) {//找到name元素
String bookName = xpp.nextText();//获取name元素的文本内容
if (bookName.equals("龙族")) {
isFound = true;//若这本书为《龙族》,将标记变量isFound置为true
}
if (event == XmlPullParser.START_TAG && xpp.getName().equals("price") && isFound == true) {//利用标记变量检验price元素是否为所要找的
System.out.println(xpp.nextText());//输出《龙族》的价格
break;//跳出循环
}
xpp.next();// 触发下一事件
}
}
用JUnit进行单体测试:
结果是正确的。
当然还有一种更简单的方法,先通过name元素找到龙族这本书,再调用next()方法找到price元素,输出价格。代码实现相对容易,这里不再演示。
XML Pull解析还可以生成XML文档,这个过程又称为序列化。和单纯地解析XML文档相比,序列化的代码有所不同:
XmlPullParserFactory xppFactory = XmlPullParserFactory.newInstance();//构建解析器工厂
XmlSerializer xs = xppFactory.newSerializer();//构建序列化器
xs.setOutput(new FileOutputStream("books2.xml"), "utf-8");//将需要生成的XML文档和XML文档的编码方式传递给序列化器
下面生成一个简单的XML文档:
@Test
public void demo2() throws Exception {
XmlPullParserFactory xppFactory = XmlPullParserFactory.newInstance();
XmlSerializer xs = xppFactory.newSerializer();
xs.setOutput(new FileOutputStream("personal_info.xml"), "utf-8");
xs.startDocument("utf-8", true);//设置XML文档的编码格式和standalone属性
xs.startTag(null, "personal_info");//为personal_info元素设置元素开始事件
xs.startTag(null, "name");//为name元素设置元素开始事件
xs.text("超哥");//为name元素设置文本元素事件
xs.endTag(null, "name");//为name元素设置元素结束事件
xs.endTag(null, "personal_info");//为personal_info元素设置元素结束事件
xs.endDocument();//设置文档结束事件
}
用JUnit进行单体测试,格式化personal_info.xml文档后查看:

操作成功。
在startTag()和endTag()方法中,第一个参数为名称空间,一般为0或null,建议整个Java程序中统一为0或null。
在XML Pull解析中有一个非常重要的思想:这种解析模式决定了在解析的过程中是不能对数据进行修改的,但如果不立即释放数据而是将其保存在内存中,那么就能对数据进行修改了。而对于这些数据,可以将它们封装成List集合对象:

对于文档books.xml,很显然数据是根据书来存放的,那么就可以定一个book类,类中定义name、author和price三个属性并生成Getters和Setters方法 :
public class Book{
private String name;
private String author;
private double price;
public String getName(){
return name;
}
public void setName(String name){
this.name = name;
}
public String getAuthor(){
return author;
}
public void setAuthor(String author){
this.author = author;
}
public double getPrice(){
return price;
}
public void setPrice(double price){
this.price = price;
}
}
再将数据序列化生成XML文档:
@Test
public void demo3() throws Exception{
Book book = new Book();
book.setName("天龙八部");
book.setAuthor("金庸");
book.setPrice(108.0);
XmlPullParserFactory xppFactory = XmlPullParserFactory.newInstance();
XmlSerializer xs = xppFactory.newSerializer();
xs.setOutput(new FileOutputStream("books3.xml"), "utf-8");
xs.startDocument("utf-8", true);
xs.startTag(null, "books");
xs.startTag(null, "book");
xs.startTag(null, "name");
xs.text(book.getName());
xs.endTag(null, "name");
xs.startTag(null, "author");
xs.text(book.getAuthor());
xs.endTag(null, "author");
xs.startTag(null, "price");
xs.text(String.valueOf(book.getPrice()));
xs.endTag(null, "price");
xs.endTag(null, "book");
xs.endTag(null, "books");
xs.endDocument();
}
用JUnit进行单体测试,格式化books3.xml文档后查看:

操作成功。
为了方便解析XML文档和序列化生成XML文档,可以定义一个工具类PullMethod,类中定义这两个方法(当然这个工具类只对book对象生效,可以根据XML文档的内容对类和方法进行修改):
public class PullMethod{
public static List parseXMLtoList(String fileName) throws Exception{//接收XML文档,将文档中的数据封装成List集合对象
List books = new ArrayList();
Book book = null;
XmlPullParserFactory xppFactory = XmlPullParserFactory.newInstance();
XmlPullParser xpp = xppFactory.newPullParser();
xpp.setInput(new FileInputStream(fileName), "utf-8");
int event;
while ((event = xpp.getEventType()) != XmlPullParser.END_DOCUMENT){
if (event == XmlPullParser.START_TAG && xpp.getName().equals("book")){
book = new Book();定义Book类对象book
}
if (event == XmlPullParser.START_TAG && xpp.getName().equals("name")){
book.setName(xpp.nextText());//为book设置name属性
}
if (event == XmlPullParser.START_TAG && xpp.getName().equals("author")){
book.setAuthor(xpp.nextText());//为book设置author属性
}
if (event == XmlPullParser.START_TAG && xpp.getName().equals("price")){
book.setPrice(Double.parseDouble(xpp.nextText()));//为book设置price属性
}
if (event == XmlPullParser.END_TAG && xpp.getName().equals("book")){
books.add(book);//将book添加至集合中
}
xpp.next();
}
return books;//返回List集合对象
}
public static void serializeListtoXML(List books, String fileName) throws Exception{//接收List集合对象,将集合对象序列化成XML文档
XmlPullParserFactory xppFactory = XmlPullParserFactory.newInstance();
XmlSerializer xs = xppFactory.newSerializer();
xs.setOutput(new FileOutputStream(fileName), "utf-8");
xs.startDocument("utf-8", true);
xs.startTag(null, "books");
for (Book book : books){//foreach语句遍历集合
xs.startTag(null, "book");
xs.startTag(null, "name");
xs.text(book.getName());
xs.endTag(null, "name");
xs.startTag(null, "author");
xs.text(book.getAuthor());
xs.endTag(null, "author");
xs.startTag(null, "price");
xs.text(String.valueOf(book.getPrice()));
xs.endTag(null, "price");
xs.endTag(null, "book");
}
xs.endTag(null, "books");
xs.endDocument();
}
}
可以这样测试这两个方法是否正确:
@Test
public void demo4() throws Exception{
List books = PullMethod.parseXMLtoList("books.xml");
PullMethod.serializeListtoXML(books, "books3.xml");
}
原理很简单,就是将books.xml文档先解析再生成,如果序列化后的文档和原文档完全一样,则证明工具类中的两个方法是正确的:

有了工具类的两个方法,就能够很方便地对XML文档中的数据进行修改了:
@Test
public void demo5() throws Exception{//增加数据
List books = PullMethod.parseXMLtoList("books.xml");
Book book = new Book();
book.setName("三国演义");
book.setAuthor("罗贯中");
book.setPrice(39.6);
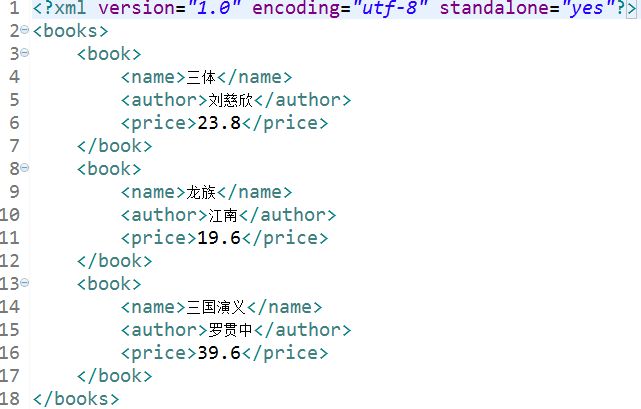
books.add(book);
PullMethod.serializeListtoXML(books, "books3.xml");
}
@Test
public void demo6() throws Exception{//修改数据
List books = PullMethod.parseXMLtoList("books.xml");
for(Book book:books){
if(book.getName().equals("三体")){
book.setPrice(book.getPrice() * 0.5);
}
}
PullMethod.serializeListtoXML(books, "books3.xml");
}

@Test
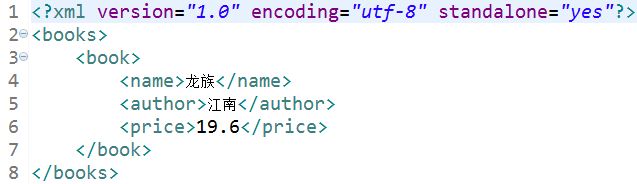
public void demo7() throws Exception{//删除数据
List books = PullMethod.parseXMLtoList("books.xml");
for(Book book:books){
if(book.getName().equals("三体")){
books.remove(book);//从集合中删除book
break;
}
}
PullMethod.serializeListtoXML(books, "books3.xml");
}
学习提示
这就是XML的三种解析模式,无论是DOM、SAX还是StAX,实际上都不难掌握,关键是要记住各自的思想和解析时调用的方法。在学习的过程中一定要善于查阅API文档,这样才能更好地理解与运用它们。