命名实体识别(Named Entity Recognition, NER)是NLP领域一个非常非常重要的方向,比如人名、地名通用性的实体识别,还有像车型名、车款名这些垂直领域的实体,在这借着实体识别的案例整理下相关的模型以及如何结合这些模型与深度神经网络实现效果更好的NER。
相关知识梳理(HMM, MEMM, CRF)
NER、分词都可以看作是序列的标注问题,而这一类问题比较传统的方法是以以马尔科夫模型(HMM)、条件随机场(CRF)为代表的概率图模型,还有最大熵隐马尔可夫模型(MEMM),这三者在之前都取得了非常不错的结果,近几年随着深度学习的兴起,深度神经网络也加入到NLP的任务中,跟CV一样,网络层起到的作用依然是特征提取的过程,深度神经网络+概率图模型成为处理NLP任务的一个非常好的解决方案。在这粗略的梳理下HMM, MEMM,CRF三个概率图模型。(MEMM 需要先理解最大熵模型,在李航老师的《统计学习方法》中,最大熵模型是跟逻辑斯蒂回归放到了统一章节中,理解该节的时候不妨参照着概率图模型中的条件随机场一块理解)
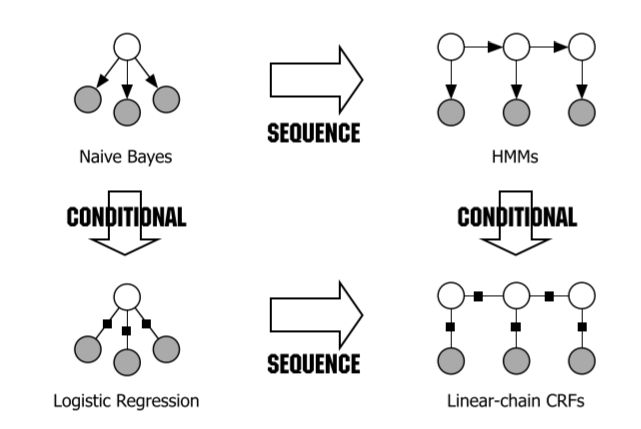
- HMM(generative model)
齐次马尔科夫性:即某时刻的状态只跟前一状态有关;
观测独立性假设:t时刻的观测结果只与该时刻的状态有关;
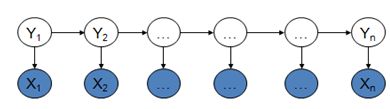
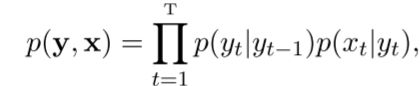
jieba分词工具,其中对未收录词的处理就使用HMM来实现的,通过viterbi算法,有兴趣的可以看下jieba的源码。
- MEMM(discriminative model)
最大熵马尔科夫模型,是对最大熵模型以及隐马尔可夫模型的扩展,最大熵模型是在符合所有约束条件下作出最不偏倚的假设,而这些约束条件就是我们所说的特征函数(特征函数的权重w是在通过拉格朗日乘子法求解过程中引入的权重)
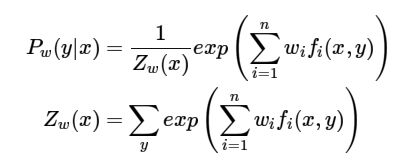 最大熵模型,与CRF极其相似,前者特征函数中并没有状态之间的相互关系
最大熵模型,与CRF极其相似,前者特征函数中并没有状态之间的相互关系

MEMM 抛弃了HMM中的观测独立性假设,保留了齐次马尔科夫性,是对HMM的一个改进。
- CRF(discriminative model)

对比CRF与MEMM两个模型,会发现二者在归一化存在差异,MEMM对每一项进行局部归一化后连乘,而CRF则是对全局归一化,也正因为这一项改进,CRF克服了标注偏移的问题。在这的特征函数f(),包括转移特征以及状态特征,在tensorflow的contrib.crf.crf_log_likelihood中的实现方式跟上边说的这些不太一致,后边会有解释。
NeuroNER 网络结构分析
假设大家对上边的内容都已经熟悉了,在这看下NeuroNER的网络结构
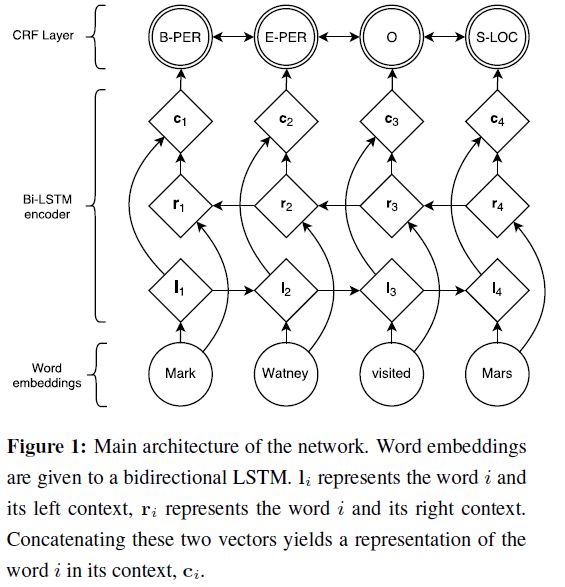

有两点需要说一下
- 来看下tensorflow中 crf.py目标函数的实现,跟《统计学习方法》中介绍的以及crf++中的实现完全不一样,为什么要这么定义呢?
#crf_sequence_score函数定义:
def crf_log_likelihood(inputs,
tag_indices,
sequence_lengths,
transition_params=None):
num_tags = inputs.get_shape()[2].value
if transition_params is None:
transition_params = vs.get_variable("transitions", [num_tags, num_tags])
sequence_scores = crf_sequence_score(inputs, tag_indices, sequence_lengths,
transition_params)
log_norm = crf_log_norm(inputs, sequence_lengths, transition_params)
# Normalize the scores to get the log-likelihood.
log_likelihood = sequence_scores - log_norm
return log_likelihood, transition_params
#crf_sequence_score函数定义:
def crf_sequence_score(inputs, tag_indices, sequence_lengths,
transition_params):
unary_scores = crf_unary_score(tag_indices, sequence_lengths, inputs)
binary_scores = crf_binary_score(tag_indices, sequence_lengths,
transition_params)
sequence_scores = unary_scores + binary_scores
return sequence_scores
tf中crf的损失函数定义使用了一元损失值、二元损失值的和,分别代表了标签以及跳转矩阵的误差值。在论文中有介绍[1]:

- crf 的定义中即有状态特征函数,又有转移特征函数,但是在lstm+crf的模块中没有体现出来? 在看NeuroNER的时候也按照之前的理论去理解,一直不吻合。其实在项目中的crf layer,并不是完整的crf过程,在前边的NN网络中,包含了特征函数的自学习过程!除此外,转移概率矩阵也是通过模型主动学习得到,属于模型输出,称之为full-rank NeuroNER。个人感觉NeuroCRF整体的思路更贴近HMM,最终将模型拆分成为发射概率以及转移概率,区别,其一是NeuroCRF针对条件概率建模[p(y|x)],其二是模型的输出—发射概率矩阵其实也包含了上下文信息,而这正好是HMM两个本质假设之一的观测独立性假设!
low-rank NeuroNER: 用NN来学习label emissions[4]
full-rank NeuroNER: 用NN来学习transitions,以及emissions

在这两篇论文中找到了解释 [2][3], 通过一些变换将条件概率转化为emission function 与 transition function的乘积形式,最终的公式形式中,G为lstm网络的outputs, F为状态之间的跳转概率矩阵。这个地方也不难理解,作者通过lstm神经网络去自动的学习特征函数,并且由于引入了循环神经网络,发射概率也充分包含了上下文信息。
结束
NLP不是主要的方向,最近用到了所以多关注了一下,有一些地方没有很好的理解,但大致的思路应该就是这样了,后边是以上四篇论文的出处,感兴趣的可以看下。
【1】Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.
【2】Rondeau M A, Su Y. Full-rank linear-chain neurocrf for sequence labeling[C]//Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on. IEEE, 2015: 5281-5285.
【3】Rondeau M A, Su Y. LSTM-Based NeuroCRFs for Named Entity Recognition[C]//INTERSPEECH. 2016: 665-669.
【4】Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv preprint arXiv:1508.01991, 2015.
欢迎一块交流讨论,文中有错误的地方,还请指正,谢谢~
email: [email protected]