背景
留存分析(群组分析,cohort analysis)是以一段时间窗内的研究对象,观察其在后续若干个时间窗内有指定行为的比例变化趋势。
留存率是一个与DAU强相关的核心指标,是反映产品生命力的重要风向标,如果留存率高、衰减速度慢,那就说明产品生命力强劲,反之则衰弱。近来在用户增长领域出现一种论调:AARRR已过时,RARRA才是更好的增长模型。也强调了留存率的重要性——如果用户都不留下来,就不会给你机会做运营。
与此同时,留存分析也是一种非常常见的数据分析模型,基本上各个业务线都会研究其特定的用户留存(当然留存分析模型不一定仅限于用户,比如我以前在某自行车公司就研究过自行车的留存,虽然我现在已经忘了当时是在研究啥……),比如:
- 做了一个运营活动,想看参加活动的用户留存
- 做了一个AB试验,想对比实验组和对照组的用户留存
- 产品做了一次改动,想看影响范围下的用户留存
……
如果来一个这样的需求,就跑一次数,那就显得有点不够优雅。正是因为它重要,又常见,且模型本质和计算逻辑比较通用,所以可以把数据处理和计算的部分抽象在数据平台上,以便用户能够快速高效地进行留存分析。
本文的目标在于连通底层明细数据,并支持用户在前端上组合筛选条件来自定义群组,然后自动计算群组的日、周、月留存,并在此基础上拟合一个留存率衰减模型,以此来预测群组在任意一天的留存值。整体思路如下:
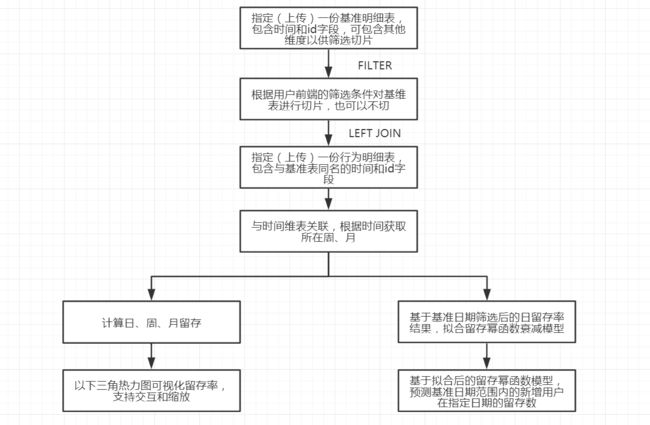
数据分析方法
留存率计算方法
在数据仓库日常生产调度中,有一种计算留存率的方法,即拿1个分区的基准明细数据不断左关联后续N个时间窗分区的明细数据,以计算重合数,进而计算留存率——这是一种稳妥的数据生产调度方法,却有失灵活。
本文计算的方法如下:
基准表与行为表按id关联,日期不作限制,即同id按日期作笛卡尔积,得到的中间表如下示意——
| 基准日 | 用户id | 行为日 | 日期差 |
|---|---|---|---|
| 2019-09-01 | user1 | 2019-09-02 | 1 |
| 2019-09-01 | user1 | 2019-09-03 | 2 |
| 2019-09-01 | user1 | 2019-09-04 | 3 |
| 2019-09-01 | user2 | 2019-09-02 | 2 |
| 2019-09-01 | user3 | 2019-09-05 | 4 |
先去重,然后按基准朱和日期差分组统计行数,得到的中间表如下示意——
| 基准日 | 日期差 | 用户数 |
|---|---|---|
| 2019-09-01 | 0 | 1000 |
| 2019-09-01 | 1 | 500 |
| 2019-09-01 | 2 | 300 |
| 2019-09-02 | 0 | 900 |
| 2019-09-02 | 1 | 400 |
再作行列转换——
| 基准日 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 2019-09-01 | 1000 | 500 | 300 | 200 | 100 |
| 2019-09-02 | 900 | 400 | 250 | 150 | 90 |
| 2019-09-03 | 1200 | 600 | 400 | 200 | 100 |
其中0那一列则是基准值,也是分母,后面各列除以基准值则可得到留存率;例如1列除以0列则是次日留存率,7列除以0列则是7日留存率。向量化计算,则可快速得出每一天的留存率。
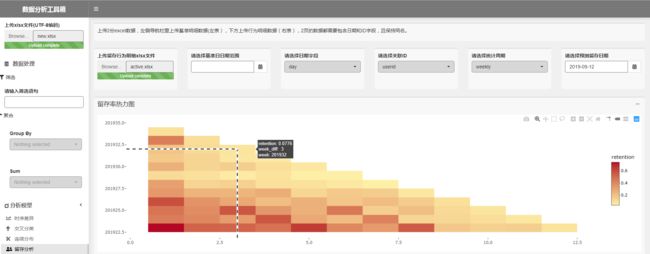
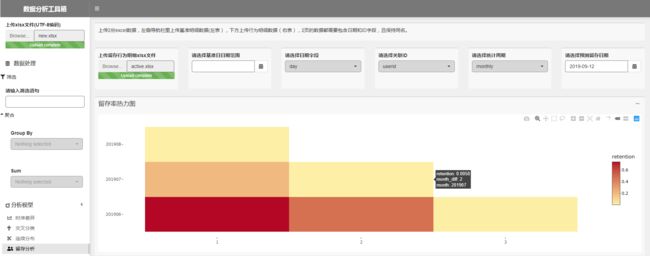
周、月留存率计算同理。
留存幂函数拟合
就拿新增活跃举例,一个正常的互联网产品,观察某一天的新增用户,在后续N天的留存率,它总体上一定是以斜率逐步下降的速率在逐步衰减,然后到达平衡——如果把散点图画出来看,很容易看到长得很像幂小于0的函数曲线。

于是就可以用幂函数来拟合留存率模型,然后就可以用户预测留存率了。
其中y是留存率,x是往后的天数,a是次日留存率(当x=1时,y = a),b是衰减幂。
从这个公式中可以看出:
- 次日留存率很重要,它决定了留存衰减曲线的起点和整体高度
- 衰减幂b小于0,b越大(越接近0)则衰减越慢,留存越稳定;b越小(绝对值越大),则衰减越快,越容易流失。
在这个公式中,x,y和a在训练集中都是已知的,就只需要拟合b;两边取对数,就能把这个幂函数模型转化成线性模型,然后用线性模型的拟合方法即可,十分简单。
> get_fit_power <- function(x,y){
+ a <- log(x)
+ b <- log(y) - log(y[1])
+ fit <- lm(b~a)
+ return(fit$coefficients[2])
+ }
>
> # 构造样例数据来验证一下
> x <- 1:100
> y <- rnorm(1)*x^(-0.56234) # 系数怎么取不重要,幂随便瞎写一个
> get_fit_power(x,y)
a
-0.56234
拿完全的幂函数样本数据去拟合,拟合的结果完全吻合样本上的幂,毫无误差,哈哈哈。
有了上述2个数据分析方法,就可以进行数据产品建设了。
数据产品示意
(本文中的示例数据来自于网络上某产品的数据,其中用户id作去隐私处理。)
上传基准明细数据
第一步没有别的,还是上传数据。上传一份用户粒度的新增明细数据,其中日期和用户id必备,其他维度可加可不加,主要用来筛选用。
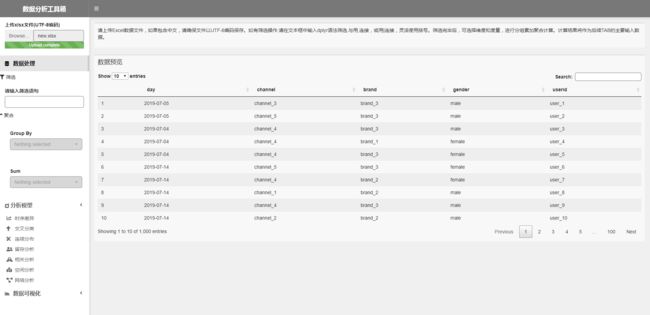
控件说明
- 第1个上传框用于上传行为明细数据
- 第2个日期区间选择器用于选定一段基准日期,即只看这一段日期以内新增的留存率情况
- 第3个和第4个下拉框只有当2份数据都上传后才能筛选,取值范围为2个表列名的交集(所以2个表的日期和ID必须同名),通过用户筛选,用来告诉用户哪个字段是日期,哪个字段是ID,才能让系统正确地关联计算
- 第5个是统计周期,有
daily(默认)、weekly和monthly3个值可选,分别对应日留存、周留存和月留存 - 最后一个日期单选器,用于在留存幂函数模型拟合出来以后,指定1天,计算基准日期内的新增在指定天的留存预测值

留存率热力图
2份数据都上传后,指定日期字段为day,关联ID为userid,统计周期为daily,则可自动计算并以热图形式可视化出统计周期内每1天的新增在后续的逐日留存率。这是一个标准的下三角形,每一个热块代表着某一个基准日在后续时间窗的留存率,颜色从浅到深表示留存率从小到大,鼠标移到一个热块上,可以显示对应的基准日期、时间窗间隔,以及对应的留存率。
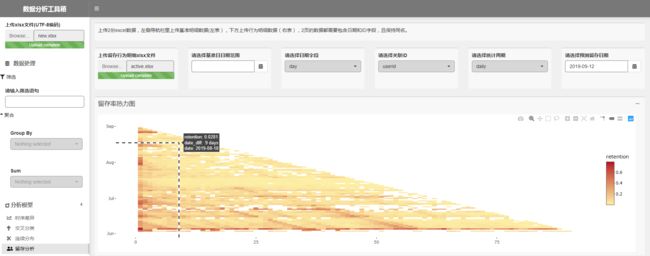
当然你可能觉得这样会逼死密集恐惧症,没有关系,可以缩小要观察的基准日期范围,比如我只想看8月内的留存率——
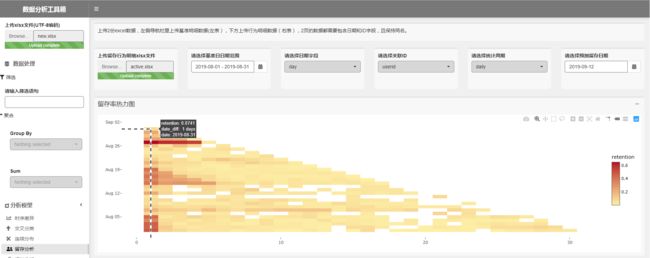
当然你可能还是觉得密集,不想看那么多天,没有关系,可以在图上通过缩放截取,只看你关心范围内的留存情况——
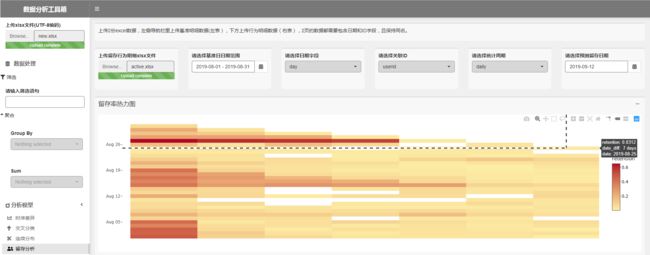
同样地,你可以通过切换统计周期,来观察周留存和月留存。
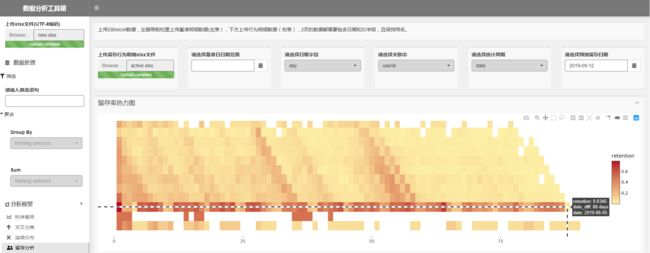
通过这几个功能,可以对留存率作全局分析,也可以发现一些异常的现象。比如下图所示,这款产品整体留存率偏低,6月5号这一天的新增用户,在80+天内留存率都很高(约40%+以上的水平),在88天后骤然恢复到正常水平,所以这一天的新增用户是什么情况?是数据出问题了,还是持续活跃了80+天的水军?
留存衰减幂函数模型
留存热力图下方有2部分,左下方是留存幂函数拟合曲线,这个是基于用户所筛选(如果没有选则不筛选)的基准日日期范围内的新增用户的留存率数据作拟合,蓝色的点为实际留存率数值,黑色的虚线为拟合的幂函数模型曲线,图上有拟合的模型结果;右下方是预测留存数,是基于拟合后的幂函数模型,在用户指定的预测留存日期(上方最后一个日期选择器控件筛选结果)预测的数值,比如第1行的结果表示,2019-07-17这1天有999个新增用户,在经过57天之后(即2019-09-12)将会衰减至3.78个。从曲线图中可以看到散点的分布并不是严格符合幂函数模型,所以拟合的模型效果不会很好。
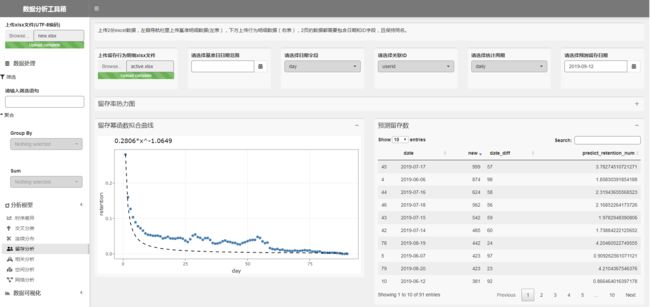
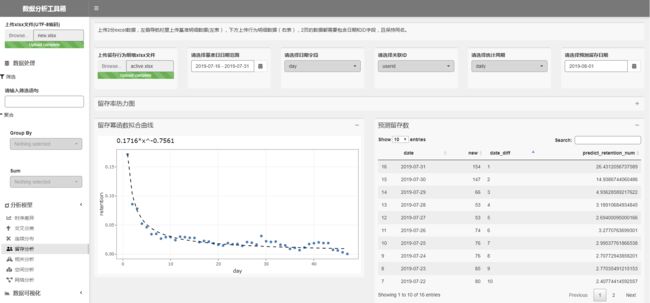
当然,用户切换基准日日期范围后,训练集会变化,拟合的模型结果也会跟着变。比如我这里限定基准日期范围为7月下半月(2019-07-16 - 2019-07-31),来预测这一段时期内的新增用户在8.1号的留存值。
从下面的曲线来看,这次的拟合结果较好。基于新拟合的模型预测结果,可以看到7.30号新增了147个用户,预期2天后能留存15个。
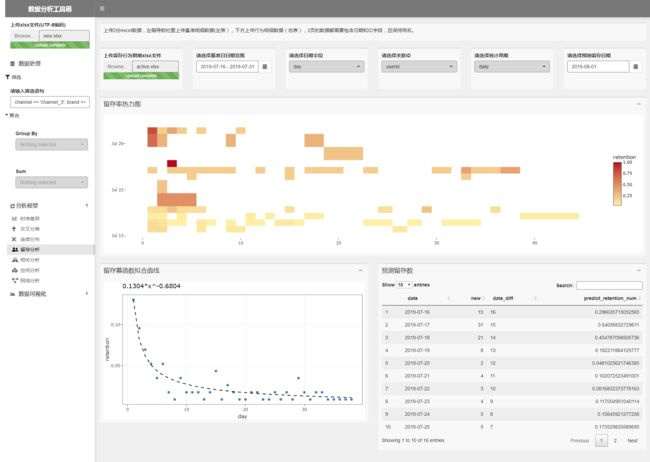
切片留存分析
我把数据处理放在左侧导航栏,表示着数据处理结果可以适用于任何模型,包括这里的筛选,就意味着任何一个模型不仅能作用于全体数据,还能作用于用户任意自定义的切片。比如我只想观察“来自于渠道3,用brand_2品牌的男性用户”的留存情况,只需在左侧输入筛选条件channel == 'channel_3', brand == 'brand_2', gender == 'male',系统则会自动计算展现这个群组的留存率和留存模型。
总结
本文以留存分析为主题,提供了一种高效的留存率计算逻辑和留存率幂函数拟合方法,并将之产品化——只需要指定2份数据集,即可自动计算出日、周和月留存,并支持自由筛选群体范围、观测周期、以及时间窗长度,同时还能基于留存率数据自动拟合留存率幂函数衰减模型,并基于这个模型预测一段时间的群组在任意1天的留存情况、
不过后续仍有2个问题需要考虑——
- 由于这套系统是在单机内存上运行,所以试验用的是小样本量数据。但在一款成熟产品的数据仓库中,用户明细数据可是很庞大的,且关于日期作笛卡尔运算,会很消耗集群计算资源——所以真正在生产环境中,系统的稳定性、计算效率是需要考虑的问题。
- 其实留存幂函数衰减模型再往下挖,就应该是DAU预测模型了,不过这个我现在还拿不准,所以这次先不搞。
参考文档
- 这套烧脑的数学模型,教你如何预测一个互联网产品的未来