Pytorch是一个深度学习框架,适合作为深度学习研究平台。
Pytorch的优点
- 基于GPU的Tensor运算,堪称GPU上的numpy
- 动态神经网络
- 与Python的深度结合
- 容易拓展
Pytorch系列大纲
- Pytorch Basic [本篇文章]
- Pytorch Visualization
- Pytorch Cuda
- Pytorch Training Utils
- Pytorch NLP [CWS待完成]
- Pytorch RL [DQN DRQN待完成]
- Pytorch Recommendation[Dream, NCF]
- Pytorch multi-process & multi-gpu
学习内容
- 基础数据结构
- Tensor
- 计算流图和自动求导
- Variable
- 细粒度自动求导控制
- 深度学习组件
- nn.Module
- 自定义Module
- 网络优化与训练
- 完整的网络
基础数据结构
Tensor
-
Tensor依据不同的数据类型可分为
- LongTensor
- FloatTensor
- ...
-
在创建相应类型的Tensor时注意numpy数据类型与torch的对应关系
data = np.arange(12).reshape(3,4) data = data.astype('float') torch_data = torch.from_numpy(data) torch_data[0] >>> 0 >>> 1 >>> 2 >>> 3 >>> [torch.DoubleTensor of size 4] torch_data.size() # Tensor的形状 >>> torch.Size([3,4]) torch_data.numpy() # 转换为numpy数据 >>> array([[ 0., 1., 2., 3.], >>> [ 4., 5., 6., 7.], >>> [ 8., 9., 10., 11.]]) torch_data.cuda() # 使用GPU计算 >>> 0 1 2 3 >>> 4 5 6 7 >>> 8 9 10 11 >>> [torch.cuda.DoubleTensor of size 3x4 (GPU 0) 查看Tensor的形状,
size返回torch.Size类(继承了tuple,可以直接索引)
x.size()
-
如何改变Tensor的形状?
- 使用view返回具有相同数据但大小不同的新张量。 返回的张量必须有与原张量相同的数据和相同数量的元素,但可以有不同的大小。一个张量必须是连续contiguous()的才能被view。类似于Numpy的np.reshape()
- resize将tensor的大小调整为指定大小,如果元素个数比当前的内存大小大,就将底层存储大小调整为与新元素数目一致的大小。如果元素个数比当前内存小,则底层存储不会被改变。原来tensor中被保存下来的元素将保持不变,但新内存将不会被初始化
- permute维度互换
- unsqueeze插入新维度
-
如何组合多个Tensor?
- 使用cat
-
如何重复一个Tensor?向某个维度扩张
- expand
x = torch.Tensor([[1, 2, 3]])
print(x.expand(3, -1))
1 2 3
1 2 3
1 2 3
[torch.FloatTensor of size 3x3]
- 运算符号类似numpy接口
- 以
_为后缀的操作为Inplace Operation
- 以
torch.mean()
- 区分矩阵运算与非矩阵运算
- mm
- matmul
- Elment-wise Multiplication
batch_size = 2
a = torch.Tensor([1, 2, 3])
a = a.expand([batch_size, a.size()[0]])
w1 = torch.Tensor([1, 2, 3])
batch_size = 2
a = torch.Tensor([1, 2, 3])
a = a.expand([batch_size, a.size()[0]])
w1 = torch.Tensor([1, 2, 3])
a * w1
1 4 9
1 4 9
[torch.FloatTensor of size 2x3]
计算流图和自动求导
Variable
使用深度学习编程框架的一个好处是一旦我们搭建起计算流图(如何由输入得到输出),框架就可以帮我们进行误差反向传播求导运算。这是如何实现的呢?在Pytorch中,我们依靠可以记住历史的Variable
Variable类似Tensor但是它会记得自己是如何被创造的
- 使用
Variable包裹Tensor,这样就可以记得历史
x = autograd.Variable( torch.Tensor([1., 2., 3]), requires_grad=True )
-
data属性查看Variable包裹的具体数据
print x.data
-
Variable的运算类似Tensor
y = autograd.Variable( torch.Tensor([4., 5., 6]), requires_grad=True )
z = x + y
print z.data
- 但是
Variable还可以知道自己是如何被创造的(也是反向传播被求导的函数)
print z.grad_fn
- 调用
backward()从当前变量开始进行反向传播;如果多次调用,则梯度会累加
s.backward()
print x.grad # Tensor
- !!! 如果中途从
Variable取出Tensor再重新包裹,那么历史将会被遗忘,反向传播无法正确运行;反之,如果我们想要将计算流图中的某些结点遗忘,不进行反向传播,可以从Variable取出Tensor再重新包裹。
细粒度的自动求导控制
Variable有两个重要的属性, require_grads和volatile,创建时,二者均默认为False(除了网络中的模型参数)
- require_grads
- 使用场景:pretrain时,要求某些层的参数固定不动,微调某些层;则可将固定层的参数
Variable置为无需计算梯度
- 使用场景:pretrain时,要求某些层的参数固定不动,微调某些层;则可将固定层的参数
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
# Replace the last fully-connected layer
# Parameters of newly constructed modules have requires_grad=True by default
model.fc = nn.Linear(512, 100)
# Optimize only the classifier
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
- volatile
- 使用场景:当模型仅用于推理时,使用
volatile效率高;仅需将模型的输入置为volatile=True即可
- 使用场景:当模型仅用于推理时,使用
深度学习组件
对于大型的神经网络模型来说,自动求导机制是远远不够的——仅仅是底层的操作。我们需要一些深度学习组件——例如将底层计算包裹成layers。Pytorch的nn包定义了一系列相当于layers的Modules,一个Module通常包括
- input Variable
- output Variable
- internal states, like learnable parameters
# -*- coding: utf-8 -*-
import torch
from torch.autograd import Variable
# N is batch size; D_in is input dimension;
# H is hidden dimension; D_out is output dimension.
N, D_in, H, D_out = 64, 1000, 100, 10
# Create random Tensors to hold inputs and outputs, and wrap them in Variables.
x = Variable(torch.randn(N, D_in))
y = Variable(torch.randn(N, D_out), requires_grad=False)
# Use the nn package to define our model as a sequence of layers. nn.Sequential
# is a Module which contains other Modules, and applies them in sequence to
# produce its output. Each Linear Module computes output from input using a
# linear function, and holds internal Variables for its weight and bias.
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
# The nn package also contains definitions of popular loss functions; in this
# case we will use Mean Squared Error (MSE) as our loss function.
loss_fn = torch.nn.MSELoss(size_average=False)
learning_rate = 1e-4
for t in range(500):
# Forward pass: compute predicted y by passing x to the model. Module objects
# override the __call__ operator so you can call them like functions. When
# doing so you pass a Variable of input data to the Module and it produces
# a Variable of output data.
y_pred = model(x)
# Compute and print loss. We pass Variables containing the predicted and true
# values of y, and the loss function returns a Variable containing the
# loss.
loss = loss_fn(y_pred, y)
print(t, loss.data[0])
# Zero the gradients before running the backward pass.
model.zero_grad()
# Backward pass: compute gradient of the loss with respect to all the learnable
# parameters of the model. Internally, the parameters of each Module are stored
# in Variables with requires_grad=True, so this call will compute gradients for
# all learnable parameters in the model.
loss.backward()
# Update the weights using gradient descent. Each parameter is a Variable, so
# we can access its data and gradients like we did before.
for param in model.parameters():
param.data -= learning_rate * param.grad.data
nn包也提供了一些损失函数
-
线性变换
-
不同于传统的线性代数,深度学习框架一般采取行变换的形式,也就是说x中的每一行是一个样本,x的每一列是一个特征维度
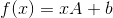
-
-
非线性变换
-
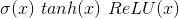
- 梯度好求且提供了非线性
torch.nn.functional.relu torch.nn.functional.softmax torch.nn.functional.log_softmax -
-
目标函数
- 负对数似然 = 最大似然
自定义Module
继承nn.Module,定义forward
优化与训练
torch.optim
- 最简单的方法:SGD
- Adam和RMSProp可能会提供算法表现
- 需要尝试不同优化算法和参数设置
Pytorch 完整的网络
网络组件应继承torch.nn.Module
class MyNN(torch.nn.module):
def __init__(self, ):# 定义参数
def forward(self): # 前向传播
输入和target应为Variable
def make_input()
def make_target()
训练
loss_function = torch.nn.NLLLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in xrange(100):
for instance, label in data:
model.zero_grad() # Pytorch会累积梯度,在使用新样本更新前需要先清空前面样本的梯度
input = make_input()
target = make_target()
output = model(input) # 前向传播
loss = loss_function(output, target) # 损失函数
optimizer.step()