GMapping开辟了2D激光SLAM的里程碑,时至今日,其思想依然熠熠生辉。本文就来详细剖析一下,GMapping到底做了什么。
从粒子滤波谈起
我假设读者都或多或少了解过粒子滤波的原理。不过,保险起见,还是再解释一遍比较好。
简单来说,在机器人定位问题中,我们想要估计机器人的位置和姿态。最初,我们完全不知道机器人在哪,那就索性假设机器人以同等的概率出现在地图上的任意一个位置。比如,假如地图是整个中国,那么机器人就等可能地出现在北京、上海、广州、哈尔滨等地。于是我们就可以用一个粒子代表一个机器人可能出现的位置。现在,机器人说话了,它说它感觉特别冷,雪落在了它洁白的脖子上。于是,我当即排除了长江以南的城市,南方怎么可能下雪呢!机器人系上围脖,继续向前走。没走几步,它又抱怨道,“今天空气质量可真不怎么样,我的双目都要失明了。”显然,它是遇到了雾霾天,这种天气在北方某帝都倒是挺常见的。它点亮了IR主动光探测,雾霾天上路多加小心总没有错。转眼间,机器人来到一个庞大的建筑物面前,这里人声鼎沸,还有遍地的商贩在叫卖着不知什么东西。它借助自身廉价的激光雷达小心翼翼地在人群中穿梭。突然,它若有所思地停了下来,似乎发现了一个美丽的秘密。虽然外面寒冬凌冽,这里却如春天般富有生机,到处洋溢着绿色的海洋。人声此起彼伏,它依稀听出了五个字,“国安是冠军”...
在上面的例子中,“我”作为机器人的大脑,根据机器人的感受,可以得出如下推理。机器人发现下雪了,那么可以确定机器人应该在北方的某个城市。接着,机器人遇到了雾霾天,那么说明该城市的空气质量很差,这就进一步把搜索范围缩小到了某几个重点空气污染城市。最后,机器人听到的五个字“国安是冠军”,彻底让我锁定了它所在的城市——“北京”。
这就是一个形象的粒子滤波案例。机器人不断地通过运动、观测的方式,获取周围环境信息,逐步降低自身位置的不确定度,最终得到准确的定位结果。
现在,我们把注意力从定位转移到SLAM问题中来。
Rao-Blackwellized 粒子滤波
在定位问题中,每个粒子只需要表示一个可能的姿态。但在SLAM中,姿态和地图都是状态变量,所以一个粒子需要同时保存所有历史时刻的机器人位姿和整个地图。
根据条件贝叶斯法则,有

这一分解相当于把SLAM分离为定位和建图两步,大大降低的SLAM问题的复杂度。该处理方法称为Rao-Blackwellized粒子滤波(RBPF)。
本文无意深究这里的细节,无非是用上一时刻的地图和运动模型预测当前时刻的位姿,然后计算权重,重采样,更新粒子的地图,如此往复。
致命缺陷
上面介绍的RBPF方法理论上可行,但实际却没法用。主要存在两个问题。
一是建图对机器人位姿有较高的要求,对任意一个粒子,仅仅依靠运动模型采样的结果构建地图,误差将会非常大。如果粒子数量足够多,也许会有若干个粒子得到准确的地图,但整体上看,通过运动模型得到的提议分布(proposal distribution)太过于分散,与真实分布相差过大。要想提高真实分布附近的粒子数,就必须整体增加粒子,导致计算代价上升。
二是频繁的重采样导致粒子耗散。每个粒子都包含了历史上所有的位姿和整个地图,频繁的重采样会使历史久远的位姿丧失多样性,因为重采样依赖的权重更多取决于当前观测,而不是十分钟前的某次观测。
GMapping正是针对这两处缺陷,提出了针对性的解决方案,从而一举成名。
方案一:改善提议分布
粒子滤波采用里程计运动模型作为提议分布,导致大部分粒子都偏离真实位置。与运动模型相反,激光雷达的观测模型则可以给出一个相对集中的分布。如下图所示,如果把粒子采样范围从又扁又宽的区域更改到激光雷达观测模型所代表的尖峰区域L,新的粒子分布就可以更贴近于真实分布。
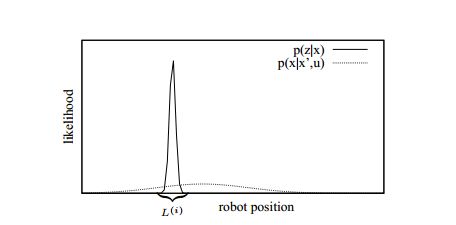
实现的方案是,在里程计运动模型给出预测后,以该预测为初值进行一次扫描匹配。扫描匹配的实现方式不限,只要能找到一个使当前观测最贴合地图的位姿即可。扫描匹配之后,我们就找到了L所代表的尖峰区域,接下来的任务是确定该尖峰区域所代表的高斯分布的均值和方差。作者的方法是,在L中随机采样K个点,根据这K个点的里程计和观测模型计算均值和方差,如下式所示。
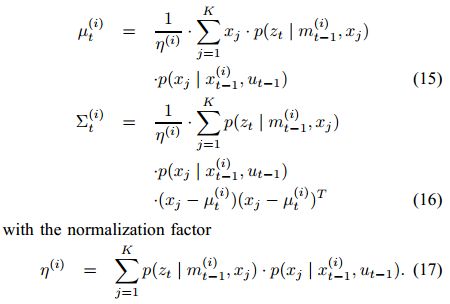
如此就得到了对真实分布的最佳近似,因此,新的粒子从该高斯分布中采样得到。
此外,对于每个粒子,我们还需要赋予它一个权重,以供后续的重采样步骤使用。权重的计算方式如下
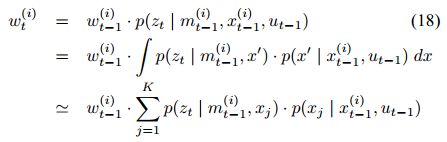
这其实是一个全概率公式,考虑了K个可能出现在当前时刻的位姿,计算它们对当前观测的贡献的加权平均。
方案二:限制重采样次数
为了避免粒子耗散,作者提出限制重采样次数的策略。我们可以想象,当机器人持续探索未知区域,且尚未发生回环的时候,由于方案一中提议分布的改善,粒子的多样性和准确性都维持在一个较高的水平。虽然累计误差始终在叠加,但在局部区域,可以认为粒子保持了较高的精度。此时,如果频繁执行重采样,粒子的多样性将会消失,历史久远的位姿将变得越来越单一。
何时执行重采样,是一个值得思考的问题。应当明确,重采样的目的是抛弃那些明显远离真实值的粒子,增强那些离真实值近的粒子。如果所有粒子都在真实值附近,且分布均匀,那么我们就没有理由执行重采样。在回环发生之前,即使有些粒子已经远离了真实值,但现有的观测不足以区分开正确的粒子和错误的粒子,因此这时候的重采样是没有意义的。只有在回环发生之后,新的观测彻底拉开正确粒子和错误粒子的权重差距,此时的重采样才能起到应有的效果。
那么,如何才能知道回环是否发生呢。显然,GMapping中没有回环检测的算法,但机智的作者给出了更巧妙的实现方式。直接通过下式评估所有粒子权重的分散程度。

Neff越大,粒子权重差距越小。想象极端情况,当所有粒子权重都一样的时候(比如重采样之后),这些粒子恰好可以表示真实分布(类似于按照某个分布随机采样的结果)。当Neff降低到某个阈值以下,说明粒子的分布与真实分布差距很大,在粒子层面表现为某些粒子离真实值很近,而很多粒子离真实值较远。这正是回环发生时经常出现的情况,重采样就应该在此时进行。
复杂度分析
整个算法完成后,我们来看看计算量的瓶颈在哪里。下表是各部分的时间复杂度。
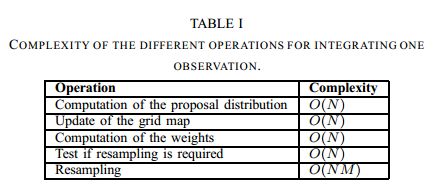
只有重采样的时间复杂度较高,与粒子数N和地图大小M的乘积成正比。这是因为重采样后,需要把某些粒子的全部数据复制一份,复制的数据中包含了整个地图M。在最差情况下,需要复制N-1个粒子,因此用O(NM)表示重采样的上界。
此时才更能意识到降低重采样次数的重要性。
从理论到实践
如何建好一张地图,是我们实际应用GMapping时更关心的问题。当场景很大,特征不足的时候,如何规划建图路线,才能建出高质量的地图呢?
首先,回环很重要。GMapping虽然没有优化,但依靠粒子的多样性,在回环时仍能消除累计误差。但需要注意的是,要尽量走小回环,回环越大,粒子耗尽的可能性就越高,越难在回环时修正回来。所以规划建图路径时,应先走一个小回环,当回环成功后,可以再多走几圈,消除粒子在这个回环的多样性。接下来走下一个回环,直到把整个地图连通成一个大的回环。
机器人起始位置也很重要,应选在特征丰富的地方,这样在回环发生时更容易提高正确粒子的权重。
场景越大,需要的粒子数越多。如果建图失败,可以提高粒子数量试试看。
最后,GMapping不是万能的,它只是在特定历史时期提出的当时最好的方案。今天,Cartographer的表现已经远远超出GMapping。但GMapping从没有过时,它的简洁,它的内涵,将始终在SLAM的舞台上屹立下去,供后人借鉴。
笔者藉以本文,向读者描摹激光SLAM之一瞥。其中万千景象,留待各位细细品味。
参考资料
Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters Giorgio Grisetti, Cyrill Stachniss, Wolfram Burgard