常见运行模式
本地模式
- 也就是一台机器,一个hadoop
伪分布式
- 也就是一台机器,存储用hdfs
集群模式
- 也就是 多台机器,namenode和ResourceManager,做ha配置
下载
到hadoop官网下载对应的包
这里用的src带源码的hadoop2.7.1,因为需要自己编译(如果是32位的系统,直接下载编译的版本也行)
通过命令上传到linux后,解压
在目录下,可以观察对应的BUILDING.txt
(这里用的SecureCRT lrzsz 应用安装已经下载好的文件, 通过 yum -y install lrzsz 安装应用)
Requirements:
* Unix System
* JDK 1.7+
* Maven 3.0 or later
* Findbugs 1.3.9 (if running findbugs)
* ProtocolBuffer 2.5.0
* CMake 2.6 or newer (if compiling native code), must be 3.0 or newer on Mac
* Zlib devel (if compiling native code)
* openssl devel ( if compiling native hadoop-pipes and to get the best HDFS encryption performance )
* Jansson C XML parsing library ( if compiling libwebhdfs )
* Linux FUSE (Filesystem in Userspace) version 2.6 or above ( if compiling fuse_dfs )
* Internet connection for first build (to fetch all Maven and Hadoop dependencies)
所以,下载对应的
- JDK 1.7+
- Maven 3.0 or later
- Findbugs 1.3.9 (if running findbugs)
- ProtocolBuffer 2.5.0
- CMake 2.6 or newer (if compiling native code), must be 3.0 or newer on Mac
- 对应其他的
等文件
并且配置环境变量
(解压的时候: tar -zxf xxx.tar.gz -C ../xxxx/ #注意这里-c 比较方便,自己记录下)
(ProtocolBuffer 只需要运行即可)
(如果提示没有编译工具,需要安装CMake,例如命令:yum -y install autoconf automake libtool cmake ncurses-devel openssl-devel lzo-devel zlib-devel gcc gcc-c++, 再 cmake install安装)
(自己的报错,可能新版本有用了新库,对着hadoop中的BUILDING.txt,自己又补充了些 yum -y install libjansson-dev fuse libfuse-dev snappy libsnappy-dev bzip2 libbz2-dev libprotobuf-dev protobuf-compiler)
(ProtocolBuffer 2.5.0安装, 大体为: (1)./configure (2)make (3)make check (4)make install)
大体步骤:
添加环境变量
- vi /etc/profile
- export XXX_HOME=/home/program/xxxx
- export PATH=$PATH:$XXX_HOME/bin
刷新,启用
- source /etc/profile
注意安装cmake
最后,通过
Build options:
* Use -Pnative to compile/bundle native code #编译native
* Use -Pdocs to generate & bundle the documentation in the distribution (using # 编译文档
-Pdist)
* Use -Psrc to create a project source TAR.GZ # 编译源码
* Use -Dtar to create a TAR with the distribution (using -Pdist) # 编译生成
这里用(也是)
mvn package -Pdist,native,docs -DskipTests -Dtar
根据网络情况,可以编译通过
编译通过后,对应的src的 hadoop-dist 的 target的 hadoop-2.7.1 下面就是对应的编译后的文件
(其实,如果只用这个项目的话,为什么要用maven编译所有的项目,自己也不理解,基本上看过的所有的资料,都是编译所有的项目)
一些工具
ftp工具
可以用 FileZilla, 或者 notepad++(ftp插件)
或者 FlashFXP, xFTP 都行
(方便传输)
配置hadoop
在编译完之后的hadoop文件夹下(自己编译,或者用别人编译好的,都行)
-
etc/hadoop/hadoop-env.sh
- 配置JAVA_HOME
-
etc/hadoop/core-site.xml
fs.defaultFS
hdfs://localhost:9000
localhost代表本地, 可以用 ip, 最好用 之前hosts中配置过的 名字,这里用的 hadoop161
对应的端口,最好用8020, 一般hadoop1.x采用9000 (这个自己不太清楚)
查看core-default.xml配置
修改core-default.xml,因为对应的tmp.dir在 /tmp文件夹下,缓存会定期删除
-
etc/hadoop/hdfs-site.xml
- 伪分布式设置为1 即可
- 默认是3
ssh 免密码登录
之前有做过,所以,这里略
命令
- bin/hadoop
- fs
- version
- jar
- checknative
- distcp
需要执行的
-
bin/hdfs
- bin/hdfs namenode -format
- 执行后,可以启动dfs
-
sbin/start-dfs.sh
- 也就是启动 NameNode(原数据) 和 DataNode(数据)
logs日志查看 以及 监控
在 logs文件夹下面,会有对应的日志文件
可以通过查看日志,查看原因
- http://${ip}:50070
- 访问监控页面
- 注意关闭防火墙(systemctl stop firewalld.service, 老版本自己查)
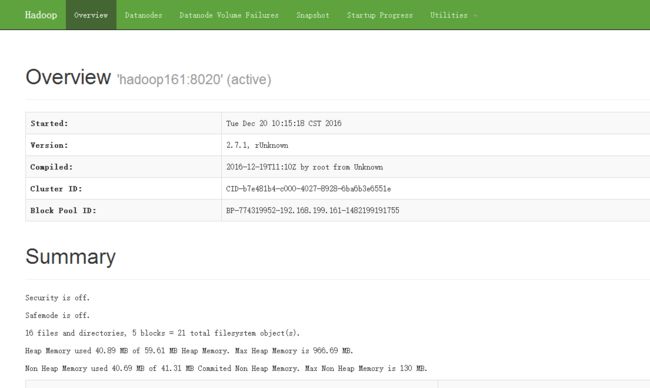
- 有一些信息
- 启动信息, 版本
- Cluster ID(在/data/dfs/data/current/VERSION中也可以查看)
- Block Pool ID(在/data/dfs/data/current/ 中也可以查看)
安装yarn(资源调度)
也就是 hadoop1.x中对应的 JobTracker及TaskTracker 等的管理
(单独出来了,解耦了)
对应的配置
单结点yarn配置
配置参数
- etc/hadoop/mapred-site.xml(注意修改名字)
- 应该是通过名字来判断,是否启动配置
- 将对应后面的.template 去掉即可
mapreduce.framework.name
yarn
注意: 2.7.2,会需要多配置几个参数
-
etc/hadoop/yarn-site.xml
- mapreduce_shuffle 比较复杂,先不管
yarn.nodemanager.aux-services
mapreduce_shuffle
开启 ResourceManager(总资源分配) 和 NodeManager(某结点资源)
- sbin/start-yarn.sh
- 启动后,可以通过 jps 查看下java进程
- yarn的监控界面 : http://${ip}:8088
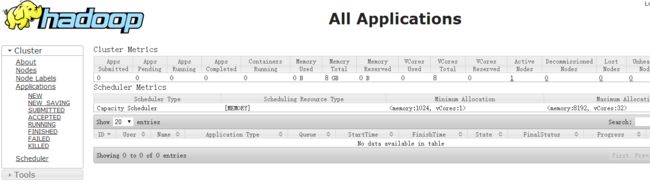
测试一些数据
到对应的目录,新建文件,输入一些数据
将文件放入 hdfs中(因为hadoop是读取hdfs中的数据的)
- hadoop的 fs 命令
- bin/hadoop fs -help #查案对应的帮助
- fs的put命令上传到hdfs
- bin/hadoop fs -put ${文件绝对路径} ${hadoop相对路径}
- put之后,可以在 【端口50070 的监控页面,查看文件】
- 这里可以发现,占用128M(文件再小,至少也占一个块,默认128M一个块)
- 点击下载文件(找不到文件,这里用的hosts配置名称,需要在访问的主机,配置hosts文件,win和linux都需要配置【做过开发半年的,应该都知道,这里略】)
- hadoop的jar命令
- 这里简单先用hadoop例子中的jar文件
-
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar #可以查看对应的说明
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
- 我们用 wordcout命令
- bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount ${hadoop中文件路径} ${hadoop中结果路径}
- 这里会分片去计算,生成job
- 也可以通过yarn界面,查看

-
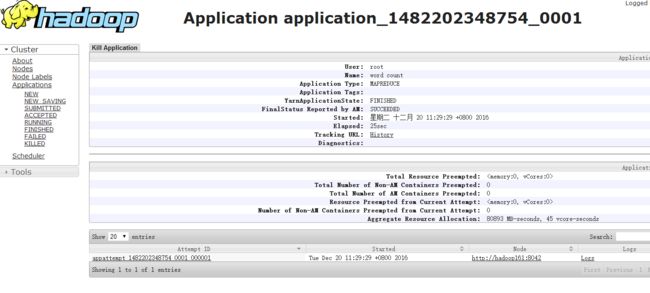
- 我们可以通过job的id,去确认是不是同一个job
- 可以通过 bin/hadoop fs -ls / #查看hadoop相对路径下,根目录的文件
- 可以通过 hadoop fs -cat 查看对应的文件
- 自己的是(bin/hadoop fs -cat /out_words/part-r-00000)

简单小节
目的是复习并且记录下过程
默认对应的2个界面端口
- 监控页面:50070
- yarn的监控界面 : 8088
之前自己搭建的版本比较老,和新的方式有些方法不太一样
只是简单记录下遇到的问题
(想想,之前遇到的问题比现在多很多,坑走的多了,自然会考虑到原来遇到过的坑)
这里也只是相当于简单的环境
hadoop重要的是实践和算法, 有时间再弄弄