作者 | Felix J.S. Bragman, Ryutaro Tanno等
译者 | 李杰
出品 | AI科技大本营(ID:rgznai100)

多任务学习(MTL)的性能表现,很大程度上取决于任务共享的方式,而任务共享方式通常是依靠网络架构的设计。共享方式是由网络深度和任务数量综合决定的,因此如果完全依靠人工设计的组合方式,可能得到的结果是耗时的,而且并不能保证是最优方案。
本文提出了一种用于多任务学习的CNNs中任务特定(task-specific)和共享表示(shared representations)的概率学习方法。具体来说,本文提出了一个随机滤波分组(stochastic filter groups,SFG)的方法,SFG是一种将每一层中的卷积核分配给专有(specialist)或通用(generalist)组的机制,这些组分别针对不同的任务或在不同的任务之间共享。SFG确定了层与网络中特定于任务和共享表示的结构之间的连接性,使用变分推断(variational inference)来学习可能的卷积分组和网络参数分组的后验分布。实验证明,本文所提出的方法适用于多个任务,并且比基准方法有更好的性能。
引言
多任务学习(MTL)
多任务学习旨在通过同时解决多个相关任务,提升学习效率和网络泛化性能。将卷积神经网络(CNNs)嵌入到MTL中已经在广泛的计算机视觉应用中显示出良好的前景,诸如目标识别、检测、分割等等。设计一个成功的MTL模型的关键是学习共享特征和特定任务特征表示的能力。理解任务之间的共性和差异的机制允许模型在任务之间传递信息,同时裁剪预测模型来描述单个任务的不同特征。这些特征表示的质量主要取决于MTL网络架构的设计,如网络中的哪些层是在所有任务之间共享的,哪些层是分开,专门针对于某个子任务的。
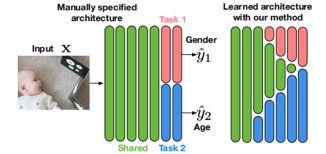
但是,这种组合方式是多样的,如果我们只依靠自己手工设计,效率是非常低下的,而且不能保证得到的组合是最优的。如下图所示,左边的图展示了一个典型的多任务体系结构,它由一个共享的“主干”特征提取器和特定于任务的“分支”网络组成,但实际上,所需的共享和特定于任务的表示,以及它们在体系结构中的交互取决于单个任务的难度和它们之间的关系,在大多数情况下,这两者都不是先验已知的。这说明了手工设计适当的体系结构十分困难。而右边的图展示了一个可以用我们的方法学习的示例体系结构。基于此,本文提出随机滤波分组(SFG),一种学习卷积核分配到特定任务和共享组的原则方法。
随机滤波分组(SFG)
本文提出了随机滤波分组机制(Stochastic Filter Groups SFG),它是一种概率机制,用于学习在MTL结构的每一层中所需的特定于任务和共享表示的数量。如下图所示,SFG学习将每一层中的卷积核分配给专有(specialist)或通用(generalist)组,这些组分别针对不同的任务或在不同的任务之间共享。SFG为网络配备了一种机制来学习层间连接,从而学习特定任务和共享表示的结构。

背景知识
变分推断(variational inference)
我们的任务是根据已有的数据去推断需要的分布P,但是在很多情况下,P不是规则的,不容易表达和直接求解,在这种情况下,我们可以转换思路,寻找一个容易表达和求解的分布Q,我们的目标是不断优化Q,使得Q和原始分布P的差距不断缩小。这种情况下,可以把Q看做P的近似分布,将Q的输出近似作为P的输出。
MTL中网络架构设计
多任务中主要通过设计相应的网络结构,确定哪些特征表示是共享的,哪些特征表示是特定于某个子任务的,主要有两大类方法:
(1)第一类是优化权重分配结构以使任务性能最大化的方法。这些方法旨在学习一组向量,这些向量控制哪些特性在一个层中共享,以及这些特性如何分布,代表性网络有十字绣网络,如下图所示,通过一个参数矩阵,决定特征在每个任务之间的共享程度。

(2)第二类侧重于根据任务相似度进行权重聚类。常见的做法是使用迭代算法来构建一个类似于树的深度结构,将类似的任务按层次进行分组,或者根据任务之间的统计相关性来确定权重共享的程度。
本文提出的方法属于第一大类即通过对特定任务和共享特性进行“硬”划分来区分。本文的方法通过对卷积核进行分组来学习层之间连接性的分布。使得模型能够学习有意义的特定于任务的分组和共享特性。
方法
本文引入了一个新的方法来确定在多任务CNN架构中从哪里学习特定任务和共享表示。这就是随机滤波分组(stochastic filter groups SFG),它是一种概率机制,将每个卷积层中的卷积核划分为“专有”组和“共享”组,它们分别针对不同的任务或在不同的任务之间共享。本文使用变分推断来学习可能的内核分组和网络参数的分布,这些参数决定了层与层之间的连接性以及共享的和特定于任务的特征。
随机滤波分组(stochastic filter groups)
SFG将一个稀疏连接结构引入到CNN的多任务学习架构中,从而将特征分离为特定于任务的和共享的组件。滤波器组的结构如下图所示,将每个卷积层中的卷积核划分为组,每个组仅作用于特征上的一个子集。这种稀疏性在不影响精度的情况下降低了计算成本和参数数量。
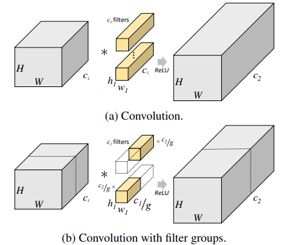
在SFG中,借鉴了滤波器分组的概念,将其引入到MTL中,在此基础上提出一种扩展,使用一种额外的机制来学习最优的卷积核分组,而不是预先指定它们。
为方便表示,我们以两个子任务的多任务学习为例,在一个CNN结构的第 L层,有 K个卷积核,可以用下列集合表示:
SFG可以通过两个步骤完成:
(1)卷积核分配(FilterAssignment):
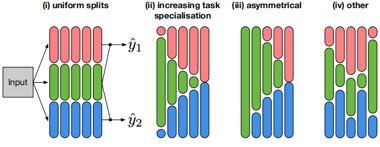
如下图所示,给定卷积层中的每个卷积核 {wk}都根据相关的分类分布样本概率(p1,p2,ps)分配给滤波组G1、G2、Gs中的一个。

如下图所示,卷积核分配完成后,进行各自分组的卷积,得到不同组的特征表示{F1,Fs,F2}。(i)表示所有的卷积核被均匀分组的情况;(ii)和(iii)表示卷积核在更深的层次上变得更加针对特定的任务的情况;(iv)表示一个任务间具有更多异构拆分的情况。
(2)特征路由(FeatureRouting):
如下图所示,第 L层上经卷积核分组卷积得到的特征{F1,Fs,F2}被路由到第L+1层的卷积核分组{G1,Gs,G2}中,然后得到新一层的特征。

具体路由公式为:

其中,h是一个激活函数,进行线性变化。*代表卷积操作。|表示特征图的维度拼接操作。
基于分析这个路由公式可知,当 L等于0时,也就是刚开始输入的时候,输入图片 x会和第一层的分组卷积核进行卷积运算,第一层特征输出的通用表示为:
下图是两个任务的损失L1和L2进行梯度回传的路线,可以看到,特定于任务的卷积核分组G1、G2仅根据自身任务的损失进行更新,而共享组Gs则根据两个任务的损失进行更新。

网络结构
下图是整体架构的示意图,其中每个SFG模块在每个卷积层中随机生成滤波器分组,所得到的特征按上述方式稀疏路由。黑色圆点代表融合模块,通常是对来自特征任务和来自共享任务的特征图进行维度拼接(concat)或者对应元素相加(element-wise add),然后将新的特征图传递到下一层的卷积核分组中。白色圆点表示一些附加的操作,通常是在激活函数前加入额外的卷积或者全连接层。
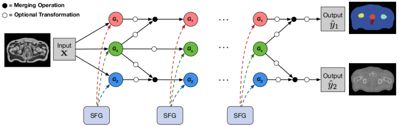
这种稀疏连接是确保任务性能和结构化表示的必要条件。我们可能会感到疑惑的一点是,第L层的共享分特征路由到第L+1层的特定任务的卷积核分组中,会让子任务的loss不能很好的分离。作者在这里的考量是,这种稀疏路由连接方式对于特定任务学到更丰富的特征是有帮助的。举例来说,如下图所示,如果在第一层有很大比例的卷积核被分配到了共享卷积分组中,并且没有路由,那么这会大大减少后续层中应用到特定任务的卷积核数量,在极端情况下,一层中所有的卷积核都被分配到共享卷积分组中去,后续层中的特定于任务的卷积核分组实际上未被使用。

另外一个需要关注的点是在这个过程中,特征图的维度变化。具体来说,在不同分组中卷积核的数量是会随着训练的轮数进行变化的,在这种情况下,每一个卷积核分组的输出特征{F1,F2,Fs}的维度也是在变化。本文不是直接处理不同大小的特性图,而是在SFG模块中,对输入特征,首先和全部卷积核进行卷积,然后根据任务分组,将原始来源于不同卷积核分组的通道置零。在特征融合方面,如果没有额外的转化,进行元素加操作;如果有诸如残差块等复杂转化,进行维度拼接操作,然后对融合特征进行1x1卷积进行升降维,确保融合后的特征与共享特征维度相同。
优化卷积网络参数和分组概率的方法
给定一个有L个SFG模块的网络,每一个模块中包含K个卷积核。SFG模块中卷积核的后验概率可以表示为:
由于SFG模块中的卷积核的后验分布难以直接进行准确的求解,本文采取变分推断的思想,用一个简单的近似分布qφ(W)代替,其中W是所有层的所有卷积核的集合。假定将qφ(W)分布按照卷积层和每一层的卷积核分组进行分解,那么该分布的变分推断可以表示为:

红框部分表示第L层中第k个卷积被路由到不同卷积核分组后的结果,它的详细表示为:

其中,函数z的作用是将第k个卷积核属于哪一个卷积核分组(task1/task2/share)的概率转化为一个one-hot向量,函数M为卷积核的参数。
此时别忘了,我们真正的后验概率是上文中的P,我们提出一个简单的近似分布q来拟合它,怎样优化q让它们的分布更相似呢,我们想到了KL散度,KL散度可以表示两个概率分布之间的相似程度。另一方面,似然函数能够根据输出,推断最有可能产生这种输出的参数,因此,我们定义一个优化函数L,它是由联合似然估计和KL散度综合而来,如下式:

其中,M是batch_size,W表示从近似分布q抽样的一组模型参数。而作者借鉴《Uncertaintyin Deep Learning》一文中的思想,将KL散度进一步表示为:

其中,H函数为分组概率的交叉熵。将(4)式带入(3)式,可以得到最终的损失L为:
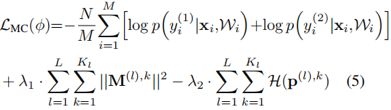
λ1和λ2是正则化系数
实验
本文在两个多任务学习任务上对SFG模块进行实验:(1)基于UTKFace数据集上的人脸图像年龄预测和性别分类;(2)基于医学影像数据集的语义图像合成与分割。
数据集
UTKFace dataset
UTKFace datasets由23703张带年龄和性别标签的人脸图像组成。在训练中分别按照70%,15%,15%的比例划分为训练集,验证集和测试集。同时构建一个次级数据集,其中只包含初始集10%的图像,以便模拟一个数据匮乏的场景。
Medical imaging dataset
在这个实验中,创建15个3D医疗图像扫描,并使用语义3D标签对器官进行扫描。创建了一个包含10名患者的训练集,其余5名用于测试。将网络训练在从轴向切片中随机采样的尺寸为128x128的二维图像上,并在测试时重建尺寸为288x288x62的三维体块。
基准
baseline共有四种,分别是:1)单任务网络,2)硬参数共享的多任务网络,先进行统一的共享特征,然后进行特征分离,3)MT-constantmask,每个任务中分配相同数量的卷积核,4)MT-constantp ,每个卷积核别分配到任务1,任务2或者任务共享分组中的概率相等,都是1/3。
实验结果
年龄预测和性别分类
如下图所示,MAE是预测年龄与真实年龄的平均预测误差,Accuracy是分类正确率。在充足数据集情况下,本文提出的MT-SFG方法在年龄预测和性别分类上都超出了baseline性能表现,这说明了学习分配卷积核的好处。

即使在数据量匮乏的数据集上,MT-SFG依然获得了最佳性能。

医学图像回归和语义分割
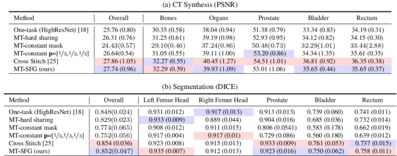
结构分析
通过分析嵌入SFG模块的网络的分组概率,可以将网络连接可视化,从而了解所学习的MTL体系结构,为了分析每一层卷积核的分组方式,计算了每一层卷积核类别概率的和。结果如下图所示,蓝,绿,粉分别代表卷积核分配到task1,task-share和task2中的概率,可以看到,从总体来说,随着网络深度的增加,网络越来越倾向于把卷积核分配到特定任务的分组中去(随着网络层数加深,蓝色和粉色的比例不断增加)。
在第一层,几乎所有的卷积核都被分配到共享卷积核分组中,这是因为,初始的卷积得到的特征是低阶特征,对于所有任务都会适用,但是随着网络层数的加深,特征越来越高阶和抽象,这时候卷积核更容易被分配到特定任务的卷积核分组中去,因为抽象的特征只有加上特定的任务属性才会有意义。

结论
本文提出了随机滤波器分组(SFGs)来区分特定任务和共享任务特征。SFGs在概率上定义了卷积核的分组,从而定义了CNNs中特性的连接性。在训练过程中,我们使用变分推断来近似给定训练数据和可能架构上的样本的连通性分布。本文的方法可以看作是多任务体系结构学习的一种概率形式,通过后验概率,推断出最优的MTL结构。
论文链接:
ICCV2019 Open Access Repositoryopenaccess.thecvf.com
(*本文首发于「AI科技大本营」微信公众号,更多干货内容请在公众号查看。转载请联系微信1092722531)