参考文章001
sqoop操作
1、数据导入
sqoop是sql和hadoop的缩写,表示从数据库中导出数据到hadoop的HDFS中,本教程就是演示在mysql和HDFS之间导入导出数据
1、首先安装sqoop
下载最新包:官网下载
解压到指定目录下
tar -xzvf sqoop-1.4.6.bin__hadoop-0.23.tar.gz -C /home sqoop
2、配置环境变量:
vim /etc/profile
export SQOOP_HOME=/home/sqoop
export PATH=$SQOOP_HOME/bin:$PATH
配置生效source /etc/profile
查看环境变量是否生效:
如上已经生效
3、设置sqoop的环境
cp ${SQOOP_HOME}/conf下
cp sqoop-env-template.sh sqoop-env.sh
编辑sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/home/hadoop/
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/home/hadoop
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
export HIVE_HOME=/home/apache-hive-1.2.2-bin
#Set the path for where zookeper config dir is
#export ZOOCFGDIR=
hbase和zookeeper的没有设置,是因为我没有用到hbase,后期可以考虑设置habase把数据导入到habase中即可
3、在mysql中制造数据便于通过sqoop导入到HDFS中
#创建test数据库
create database test;
#授权任何ip和用户都可以访问test数据库
grant all privileges on test.* to root identified by 'xxxx'
#创建日志表,只有两个主键id和content代表日志id和内容
create table log(`id` int(11) NOT NULL AUTO_INCREMENT,content varchar(500) NOT NULL,PRIMARY KEY (`id`)
)ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
#编写存储过程,往log表中添加10000条记录
drop PROCEDURE add_log;
delimiter //
CREATE PROCEDURE `add_log`()
BEGIN
DECLARE v_max INT UNSIGNED DEFAULT 10000;
DECLARE v_counter INT UNSIGNED DEFAULT 0;
WHILE v_counter < v_max DO
insert into log values(NULL,'test data');
SET v_counter=v_counter+1;
END WHILE;
END;//
delimiter ;
最后进行执行
call add_log();
调用后一直执行,最后看到test.log中有10000条记录;
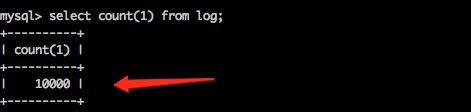
4、在执行导入操作之前,需要把mysql连接数据库的jar包拷贝到${SQOOP_HOME}/lib下面

5、执行导入操作:
sqoop import --connect jdbc:mysql://node3:3306/test --username root --password xxxxx --table log --fields-terminated-by '\t'
对以上参数进行说明:
sqoop ##sqoop命令
import ##表示导入
--connect jdbc:mysql://ip:3306/test ##告诉jdbc,连接mysql的url
--username root ##连接mysql的用户名
--password xxx ##连接mysql的密码
--table log ##从mysql导出的表名称
--fields-terminated-by '\t' ##指定输出文件中的行的字段分隔符
-m 1 ##复制过程使用1个map作业
--hive-import ##把mysql表数据复制到hive空间中。如果不使用该选项,意味着复制到hdfs中
6、验证
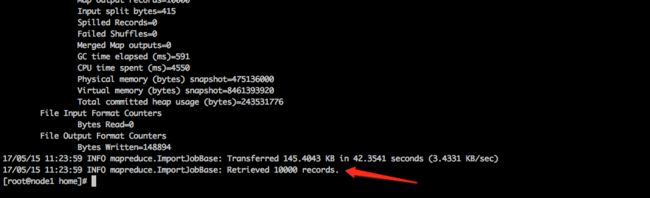
其实就是执行map-reduce程序,往HDFS上写入数据,完整日志可以看最后的执行日志,截图中可以看到接收到10000条数据。
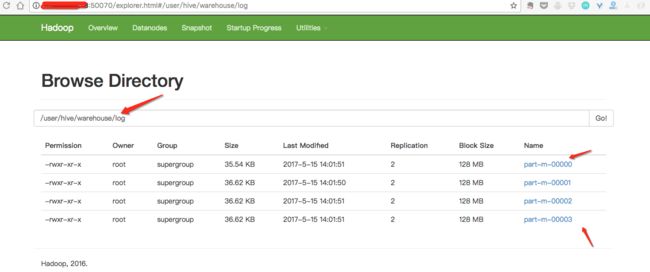
我们看一下HDFS上是否有数据:如图所示,hdfs上有对应的数据,后期会分析为什么会分成4部分!
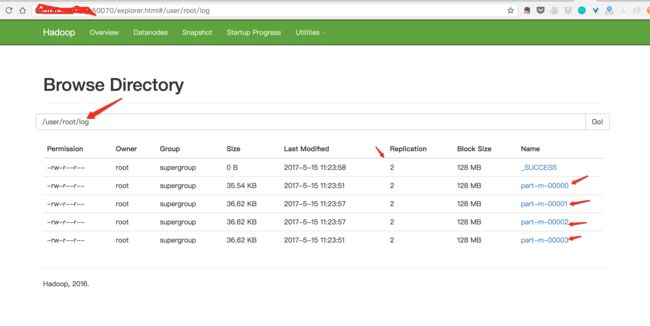
可以看到一共分为四个部分,每一个部分应该是2500条数据,我们下载part-m-0000打开以后可以看到是2500条,格式如下:
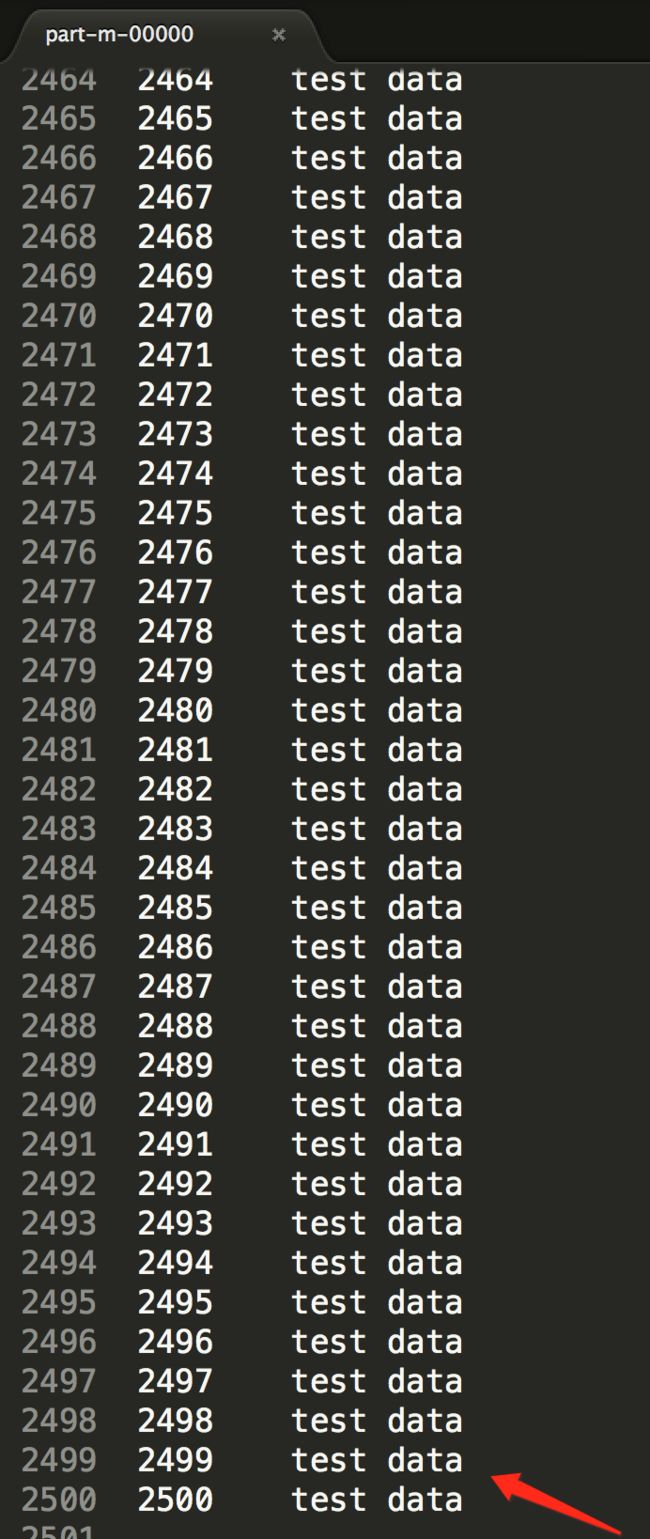
执行结果:
将mysql数据导入到hive中
首先删除掉导入到HDFS的数据
hadoop fs -rmr /user/root/*
然后再通过命令导入到hive中:
sqoop import --connect jdbc:mysql://node3:3306/test --username root --password xxxx --table log --fields-terminated-by '\t' --hive-import
执行完成以后可以看到hive中有对应的数据
2、数据导出
sqoop
export ##表示数据从hive复制到mysql中
--connect jdbc:mysql://ip:3306/test ##告诉jdbc,连接mysql的url
--username root ##连接mysql的用户名
--password xxxx ##连接mysql的密码
--table log_2 ##mysql中的表,即将被导入的表名称
--export-dir '/user/root/warehouse/log' ##hive中被导出的文件目录
--fields-terminated-by '\t' ##hive中被导出的文件字段的分隔符
注意:导出的数据表必须是事先存在的
首先在mysql数据库中新建表log_2,将第一次导入的10000条数据导出到log_2中,创建表log_2;
CREATE TABLE `log_2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`content` varchar(500) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
执行导出
sqoop export --connect jdbc:mysql://node3:3306/test --username root --password xxxx --table log_2 --fields-terminated-by '\t' --export-dir '/user/root/log' --input-fields-terminated-by '\0000'
其中--input-fields-terminated-by '\0000'代表需要导出的文件的文件名匹配格式
验证:
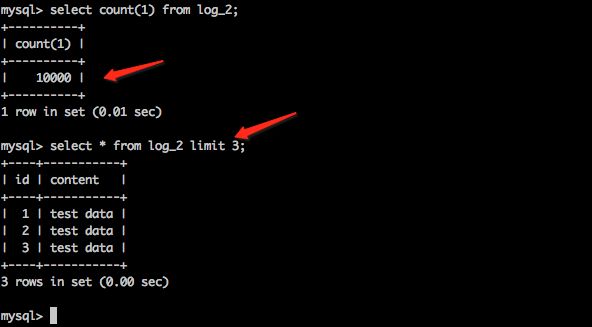
查看mysql中的表log_2; 如下图,执行结果,log_2中有10000条数据,就是刚才导入的!
备注
1、导入mysql数据到Hadoop HDFS中日志
执行日志:
[root@node1 home]# sqoop import --connect jdbc:mysql://106.75.62.162:3306/test --username root --password xxxxx --table log --fields-terminated-by '\t'
Warning: /home/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
17/05/15 11:23:05 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
17/05/15 11:23:05 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
17/05/15 11:23:05 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/05/15 11:23:05 INFO tool.CodeGenTool: Beginning code generation
17/05/15 11:23:12 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `log` AS t LIMIT 1
17/05/15 11:23:12 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `log` AS t LIMIT 1
17/05/15 11:23:12 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop
注: /tmp/sqoop-root/compile/3d774b871b1067fdc69f6e08612e3e64/log.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
17/05/15 11:23:15 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/3d774b871b1067fdc69f6e08612e3e64/log.jar
17/05/15 11:23:15 WARN manager.MySQLManager: It looks like you are importing from mysql.
17/05/15 11:23:15 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
17/05/15 11:23:15 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
17/05/15 11:23:15 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
17/05/15 11:23:15 INFO mapreduce.ImportJobBase: Beginning import of log
17/05/15 11:23:16 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/05/15 11:23:17 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/05/15 11:23:17 INFO client.RMProxy: Connecting to ResourceManager at node1/10.9.167.99:8032
17/05/15 11:23:19 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1249)
at java.lang.Thread.join(Thread.java:1323)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:609)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:370)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:546)
17/05/15 11:23:19 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1249)
at java.lang.Thread.join(Thread.java:1323)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:609)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:370)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:546)
17/05/15 11:23:19 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1249)
at java.lang.Thread.join(Thread.java:1323)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:609)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:370)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:546)
17/05/15 11:23:26 INFO db.DBInputFormat: Using read commited transaction isolation
17/05/15 11:23:26 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`id`), MAX(`id`) FROM `log`
17/05/15 11:23:26 INFO mapreduce.JobSubmitter: number of splits:4
17/05/15 11:23:27 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1492235323762_0002
17/05/15 11:23:27 INFO impl.YarnClientImpl: Submitted application application_1492235323762_0002
17/05/15 11:23:27 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1492235323762_0002/
17/05/15 11:23:27 INFO mapreduce.Job: Running job: job_1492235323762_0002
17/05/15 11:23:37 INFO mapreduce.Job: Job job_1492235323762_0002 running in uber mode : false
17/05/15 11:23:38 INFO mapreduce.Job: map 0% reduce 0%
17/05/15 11:23:53 INFO mapreduce.Job: map 50% reduce 0%
17/05/15 11:23:59 INFO mapreduce.Job: map 100% reduce 0%
17/05/15 11:23:59 INFO mapreduce.Job: Job job_1492235323762_0002 completed successfully
17/05/15 11:23:59 INFO mapreduce.Job: Counters: 31
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=542612
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=415
HDFS: Number of bytes written=148894
HDFS: Number of read operations=16
HDFS: Number of large read operations=0
HDFS: Number of write operations=8
Job Counters
Killed map tasks=1
Launched map tasks=4
Other local map tasks=4
Total time spent by all maps in occupied slots (ms)=60923
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=60923
Total vcore-milliseconds taken by all map tasks=60923
Total megabyte-milliseconds taken by all map tasks=62385152
Map-Reduce Framework
Map input records=10000
Map output records=10000
Input split bytes=415
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=591
CPU time spent (ms)=4550
Physical memory (bytes) snapshot=475136000
Virtual memory (bytes) snapshot=8461393920
Total committed heap usage (bytes)=243531776
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=148894
17/05/15 11:23:59 INFO mapreduce.ImportJobBase: Transferred 145.4043 KB in 42.3541 seconds (3.4331 KB/sec)
17/05/15 11:23:59 INFO mapreduce.ImportJobBase: Retrieved 10000 records.
[root@node1 home]#