Chapter 6: CPU Scheduling
Table of Contents
Chapter 6: CPU SCHEDULINGScheduling ConceptsCPU Scheduler(调度器)Process Dispatcher(派遣器)Schedule CriteriaScheduling AlgorithmsFCFSSJFPriority schedulingRRMultilevel Feedback QueueMultiple-Processor SchedulingReal-Time SchedulingAlgorithm Evaluation
Scheduling Concepts
Scheduling Criteria
Scheduling Algorithms
Multiple-Processor Scheduling
Real-Time Scheduling
Scheduling Algorithm Evaluation
Scheduling Concepts
To maximize CPU utilization with multiprogramming
CPU-I/O Brust Cycle: Process execution consists of a sequence of CPU execution and I/O wait.

CPU Scheduler(调度器)
-
CPU scheduler
selects a process from the ready processes and allocates the CPU to it.
-
When to use CPU scheduler?
When a process terminates.
When a process switches from running to waiting state.
When a process switches from running to ready state.
When a process switches from waiting to ready.
-
Scheduling under 1 and 2 only is non-preemptive(非抢占)
Win 3.x
-
Scheduling under all conditions is preemptive(抢占)
Win 9x, Win NT/2K/XP, Linux
Process Dispatcher(派遣器)
Dispatcher module gives the CPU control to the process selected by the short-term scheduler; this involves:
-
switching context (saving context and restoring context)
switching to user mode (from monitor mode => user mode)
jumping to the proper location in the user program to restart this program (PC counter)
Dispatch latency – the time it takes for the dispatcher to stop one process and start another running.
Schedule Criteria
-
CPU utilization:
keep the CPU as busy as possible.
-
CPU throughput:
number of processes that complete their execution per time unit.
-
Process turnaround time:
amount of time to execute a particular process.
-
Process waiting time):
amount of time a process has been waiting in the ready queue.
-
Process response time:
amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment).
Optimization criteria
Maximize CPU utilization.
Maximize CPU throughput.
Minimize process turnaround time.
Minimize process waiting time.
Minimize process response time.
Scheduling Algorithms
Scheduling algorithms
-
First come first served (FCFS)
Shortest job first (SJF)
Priority scheduling
Round robin (RR)
Multilevel queue algorithm
Multilevel feedback queue algorithm
FCFS
Convoy effect : short process behind long process.
The FCFS scheduling algorithm is non_preemptive.
-
The FCFS algorithm is particularly troublesome for time-sharing systems.
It would be disastrous to allow one process to keep the CPU for an extended period.
SJF
Associate with each process the length of its next CPU burst.
-
When the CPU is available, it is assigned to the process that has the smallest next CPU burst.
If two processes have the same length next CPU burst, FCFS scheduling is used to break the tie.
Two schemes:
-
non-preemptive – once CPU given to the process it cannot be preempted until completes its CPU burst.
preemptive – if a new process arrives with CPU burst length less than remaining time of current executing process, preempt. This scheme is know as the Shortest-Remaining-Time-First (SRTF).
SJF is optimal – gives minimum average waiting time for a given set of processes.


Problems:
Can only estimate the length.
Can be done by using the length of previous CPU bursts, using exponential averaging.

Priority scheduling
A priority number (integer) is associated with each process.
The CPU is allocated to the process with the highest priority (smallest integer ≡ highest priority).
-
Preemptive.
Non-preemptive.
SJF is a priority scheduling where priority is the predicted next CPU burst time.
Problem:Starvation — low priority processes may never execute.
Solution:Aging — A process will increase its priority with time.
RR
Each process gets a small unit of CPU time (time quantum, 时间片段), usually 10 - 100 milliseconds. After this time has elapsed, the process is preempted and added to the end of the ready queue.
-
Keep the ready queue as a FIFO queue of processes, and new processes are added to the tail of the ready queue.
The CPU scheduler picks the first process from the ready queue, sets a timer to interrupt after 1 time quantum, and dispatches the process.
-
If the process has a CPU burst:
-
less than 1 time quantum
The process itself will release the CPU voluntarily.
The scheduler will then proceed to the next process in the ready queue.
-
longer than 1 time quantum
The timer will go off and will cause an interrupt to the OS.
Execute the context switch, and the process will be put at the tail of the ready queue.
The CPU scheduler will then select the next process in the ready queue.
-
-
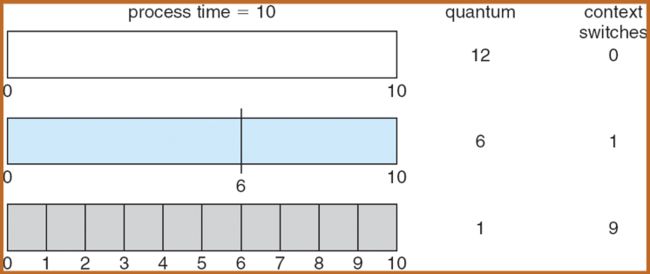
If there are n processes in the ready queue and the time quantum is q, them
Each process gets 1/n time of the CPU time in the chunks of at most q time units at once.
No process wait more than (n - 1)q time units.
-
Perfomance
q large => FCFS
q small => q must be large with respect to the context switch time, otherwidth overhead is too high.
-
Time Quantum and Context Switch Time
 ch6_8.png
ch6_8.png
Multilevel Feedback Queue
-
Ready queue is partitioned into separate queues:
foreground(interactive)
background(bath)
-
Each queue has its own scheduling algorithm:
foreground — RR
background — FCFS
-
Scheduling must be done between the queues.
Fixed priority scheduling; (i.e., serve all from foreground then from background). Possibility of starvation.
Time slice — each process gets a certain amount of CPU time which it can schedule amongst its processes; i.e., 80% to foreground in RR and 20% to background in FCFS.
MULTILEVEL FEEDBACK QUEUE
A process can move between the various queues; aging can be implemented this way.
-
The idea is to separate processes with different CPU-burst characteristics.
If a process uses too much CPU time, it will be moved to a lower-priority queue.
A process that waits too long in a lower-priority queue may be moved to a higher-priority queue.
-
Multilevel-feedback-queue scheduler defined by the following parameters:
number of queue.
scheduling algorithms for each queue.
method used to determine which queue a process will enter when that process needs service.
method used to determine when to upgrade/downgrade a process.
-
EXAMPLR:
-
Three queues:
— time quantum 8 milliseconds
— time quantum 16 milliseconds
— FCFS
-
Scheduling
A new job enters which is served RR. When it gains CPU, job receives 8 milliseconds. If it does not finished in 8 milliseconds, job is moved to .
At , job is again served RR and receives additional 16 milliseconds. If it still does mot complete, it is preempted and moved to queue .
 ch6_10_mfq.png
ch6_10_mfq.png
-
Multiple-Processor Scheduling
When multiple CPUs are available, the scheduling problem is more complex.
-
For multiple CPUs:
Homogeneous vs heterogeneous CPUs
Uniform memory access(UMA) vs Non-uniform memory access(NUMA).
-
Scheduling
Master/slave vs peer/peer
Separate queues vs common queue (sharing)
Asymmetric multiprocessing — only one processor accesses the system data structure, alleviating the need for data sharing.
Symmetric multiprocessing.
Real-Time Scheduling
-
Hard real-time system — required a critical task within a guaranteed amount of time.
- Hard real-time system are composed of software special-purpose running on hardware deficated to their critical process, and lacks of the fullfunctions of morden computers and operating systems.
-
Soft real-time computing — requires that critical processes receive priority over less fortunate ones.
Priority scheduling
Lower dispatch latency.
Algorithm Evaluation
Deterministic modeling
Queueing models
Simulations
-
Implementation
Deterministic modeling
-
Takes a particular predetermined workload and defines the performance of each algorithms for that workload.
To describe scheduling algorithms and provide examples,
Simple and fast,
But, too special to be useful.
Queueing models
-
Queueing-network analysis
The computer is described as a network of servers. Each server has a queue of waiting process. The CPU is server with its ready queue, as is the I/O system with its device queues.
Knowing arrival rates and service rates, we can compute utilization, average queue length, average wait time, and so on.
Useful for comparing scheduling algorithms.
Real distributions are difficult to work with.
Simulations
-
Involve programming a model of the computer system.
Software data structure represent the components of the computer system.
The simulation has a variable representing as a clock; as this variable's value was increased, the simulator modifies the system to reflect the activities of the device, the processes, and the scheduler.
As the simulator executes, statistics that indicate the algorithm performance are gathered and printed.
Useful but expensive.
Implementation
-
Code
To code the algorithm,
To put it in the OS, and
To see how it works.
-
Costly
To sum up:
- A Perfect Scheduling algorithm is not easy to found.
- In practice, we don't really need the perfect scheduling algorithm.