今天,我们将介绍非常重要的一部分:风险的量化。我们会从原理以及Python实战两个角度来学习。
我们开始今天的内容。
一、方差
1952年,Markowitz发表了均值-方差投资组合理论,在这套理论中他正式提出了用方差来描述资产收益不确定性的方法,也就是资产风险的方差度量法。
为什么我们可以用方差来度量风险呢?我解释一下方差的原理你就知道了。
这里R是指所有的收益率序列(真实或预估),E(R)是指收益率的期望。有些朋友可能对期望不太熟悉,所以我们换个表达方式。假如我们有一组已知的长度为n的收益率数据R,那么它们的方差为:
相当于每个收益率数据与平均收益率之间距离的平方的均值。简单来说,我们可以理解为收益率相对于均值的波动情况。方差越大,波动越大,风险也就越大,潜在的收益往往也越高。
随着风险理论的实践与发展,这种方法被发现了很大的弊端。首先,这个定义不能与风险完全等同,因为向上的剧烈波动也会造成方差偏高,但是这种波动是我们所希望发生的,能使我们获益;其次,Markowitz的均值-方差投资组合理论有一个重要假设,那就是收益率是符合正态分布的,但是现实中的金融产品收益率往往具有明显的偏度和峰度,仅仅使用方差来度量有可能会产生较大的误差。
假如我们已经获取到了一组收益率数据R,在Python中,我们可以很多方法来计算方差,这里我们用numpy和pandas来示范一下如何计算方差和标准差(方差的平方根):
# 使用numpy
import numpy as np
R = [0.01, 0.05, 0.02, -0.03]
var1 = np.var(R)
std1 = np.std(R)
# 使用pandas
import pandas as pd
R = pd.Series([0.01, 0.05, 0.02, -0.03])
var2 = R.var()
std2 = R.std()
二、下行风险
同样是1952年,Roy发表了用下行偏差来度量风险的方法。这个方法解决了前边我们提到的方差度量法的问题,它主要关注向下的波动。计算下行偏差时,一个最重要的变量就是目标收益率,通常用可接受的最低收益率代表(MARR,Minimum Acceptable Rate of Return)。我们常用无风险收益率、0或者资产收益率的平均值作为MARR。下行偏差描述的就是低于MARR的收益率的发散程度,其计算方式为:
也就是说,收益率大于MARR的部分全都会被抹平为0,小于MARR的部分会正常进行计算。这样的话,得到的下行偏差中不包含向上波动的成分,仅仅代表了资产价值下行的风险。包括方差度量法的创始人Markowitz都承认下行风险是一个更好的衡量方式。
那么我们来看一下如何用Python计算下行风险,我们先用tushare来获取万科和中国平安近两年的行情数据。
import pandas as pd
import tushare as ts
pro = ts.pro_api()
wanke = pro.daily(ts_code='000002.SZ', start_date='20170101')
pingan = pro.daily(ts_code='601318.SH', start_date='20170101')
wanke.head()

然后,分别计算万科和平安的下行风险:
def cal_downside_risk(r):
_r = r.map(lambda x: x / 100)
mean = _r.mean()
r_adjust = _r.map(lambda x: min(x-mean, 0))
risk = np.sqrt((r_adjust ** 2).mean())
return risk
wanke_risk = cal_downside_risk(wanke.pct_chg)
pingan_risk = cal_downside_risk(pingan.pct_chg)
print('万科下行风险:', wanke_risk)
print('平安下行风险:', pingan_risk)

看起来万科的下行风险更大一些,因为它的收益率在均值下方的波动更大一些。在上边的代码中,我们先将收益率转换为小数(tusahre中为了便于观察,提供了百分点数据),然后实现了我们前边提供的下行风险计算公式。这部分如果有不能理解的可以留言。注意,这里函数的输入参数是 一个pandas Series对象。
三、风险价值
1994年,投行巨头摩根大通公开发表了用风险价值(Value at Risk,VaR)度量风险的方法。其定义为:VaR是给定的置信水平和目标时段下预期的最大损失。用公式表达为:
其中,随机变量Xt是金融资产或资产组合在时间段t内的价值变动量,Pr代表概率,这个公式的含义是,在时间段t内,我们的损失比VaR(α,t)还大的的概率为α%。也就是说,想要计算风险价值,我们必须要先清楚收益率的概率分布。那么我们如何计算收益率的概率分布呢?
常见的方法有历史模拟法、协方差矩阵法以及蒙特卡洛模拟法。
1. 历史模拟法
这个方法最为简单。以单日、5%置信区间为例,我们直接取历史上每天的收益率数据,得到其数据分布。然后我们找到95%的置信区间中(在这里取最大的95%即可)最小的那个收益率,然后乘以我们的初始资产价值,就是我们预估的VaR了。
这种方法假定未来的波动与历史波动一致,但事实上金融市场瞬息万变,很多风险因素并不能从历史数据中发掘出来。历史模拟法一般需要至少1500个数据样本,否则会导致VaR不太可靠;另外太过久远的数据意义也不大。
2. 协方差矩阵法
协方差矩阵法主要用于投资组合的风险预估。它假设各资产的收益率服从正态分布,且各资产的收益率与资产组合的收益率之间呈线性关系,这样投资组合的收益率也服从正态分布。然后我们通过历史数据中各资产的收益率均值、方差、协方差矩阵,可以估计出投资组合的均值及方差,这样就得到了投资组合的收益率分布。
这里由于我们只有投资组合的均值和方差,且我们假设投资组合的收益率也符合正态分布,所以我们可以通过正态分布的概率模型来找到VaR。我们对收益率数据做过标准化之后可以将其转化为z分数,z分数是符合标准正态分布的。然后从分布中找到1-α%的置信区间内的最小值(即α%分位数),我们用Zα来表示它,然后将其代入计算z分数的公式求解出对应的收益率。
3. 蒙特卡洛方法
又称随机抽样或统计试验方法,是一种随机模拟方法。蒙特卡洛方法在模型构建合理、参数选择正确时会更加精确可靠,甚至能处理非线性、收益率非正态分布的情况;但是它依赖特定的随机过程和所选择的历史数据,并且产生的随机数据序列是伪随机数,可能会导致结果误差较大,而且计算量大、计算时间长。
如果读者对于自助采样法(Bootstrap)有所了解的话,会发现他们之间有一些关联。蒙特卡洛方法假定了数据的分布,但是自助法不需要有任何数据假设,它直接从原始数据中进行再抽样。这部分我们暂时了解即可,之后会找时间专门讲解。
那么接下来我们就使用刚才万科和平安的数据,用Python来实战一下。
# 历史模拟法
wanke_var = wanke.pct_chg.quantile(0.05) / 100
pingan_var = pingan.pct_chg.quantile(0.05) / 100
print('历史模拟法')
print('万科VaR(0.05,1天):', wanke_var)
print('平安VaR(0.05,1天):', pingan_var)
# 协方差矩阵法
from scipy.stats import norm
wanke_var = norm.ppf(0.05, wanke.pct_chg.mean(),
wanke.pct_chg.std()) / 100
pingan_var = norm.ppf(0.05, pingan.pct_chg.mean(),
pingan.pct_chg.std()) / 100
print('协方差矩阵法')
print('万科VaR(0.05,1天):', wanke_var)
print('平安VaR(0.05,1天):', pingan_var)


可以看到,两种方法都表明万科的VaR更高,即在95%的置信区间下,万科的最大损失更高。
我们来解释一下代码,pandas Series对象的quantile()方法会返回分位数,在前边我们已经明确,历史模拟法计算VaR直接求0.05分位数即可;pandas Series对象的mean()方法和std()方法分别返回其均值和标准差;scipy.stats.norm函数可以根据我们输入的置信区间、均值和标准差来求得对应的分位数。
四、期望亏空
期望亏空(Expected)是VaR(风险价值)的变体,是学术界提出来用于弥补VaR理论上的缺点。前边我们提到,风险价值是1-α%置信区间内最大的亏损,也就是从小到大第α%百分位数。
那么期望亏空不是第α%位置对应的收益率,而是最小的α%中所有收益率的均值。
我们仍然以万科近两年的收益率数据为例:
VaR_wanke = wanke.pct_chg.quantile(0.05)
ES_wanke = wanke.query('pct_chg <= @VaR_wanke')['pct_chg'].mean()
print('万科近两年风险价值:', VaR_wanke)
print('万科近两年期望亏空:', ES_wanke)
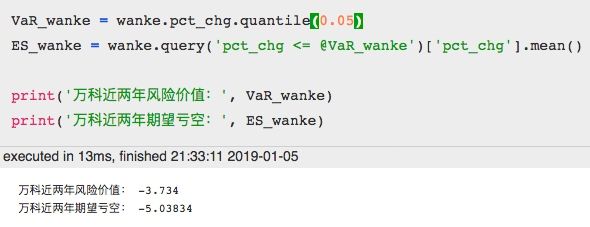
可以看到,期望亏空是比风险价值更低的。理论上,期望亏空≤风险价值永远成立。
五、最大回撤
最大回撤(Maximum Drawdown,MDD)是非常常用的用来衡量投资(尤其是基金)表现的手段,它代表了投资人可能遇到的最大亏损。最大回撤非常好理解,首先,资产在时刻t的回撤是指在(0,t)期间的最高峰值到T时刻的资产价值Pt之间的回落值;而最大回撤,就是在最高峰值之后一直到T时刻,中间有一个最低点,从峰值到最低点的回落值就是最大回撤。回撤值占最高价值的比例就是回撤率。
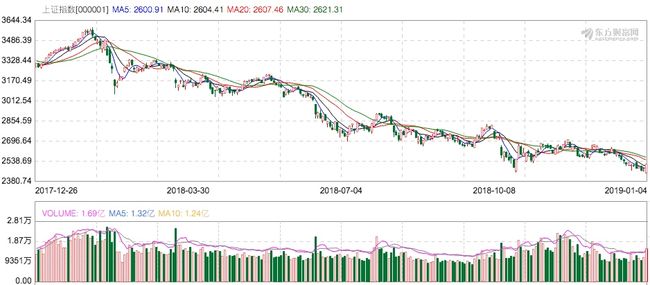
比如说,2018年以来A股的最高点是3587.03,上一个交易日(2019-01-04)的收盘价为2514.87,那么2019-01-04的回撤率为:(3587.03-2514.87)/3587.03=29.89%,刚好最低点也出现在2019-01-04,所以最大回撤率为(3587.03-2440.91)/3587.03=31.95%。
但是有些时候我们拿到的数据并不是资产价值的数据序列,而是收益率的序列,那我们应该如何计算最大回撤呢?
从时刻0到时刻T的回撤值(这里的回撤值类似基金净值的回撤值)为:
相应的回撤率为:
用LaTeX手打一个公式太慢了……所以最大回撤即最大回撤率的公式就不给大家展示了,留给大家自己练习一下。其算法是找到毛收益率(1+Rt)累乘的最大值,这里就是峰值了,假设这一时刻是k,那么我们就接着找从k到T之间毛利率累乘的最小值,然后计算两者的差异占最高值的比例,就是最大回撤率了。
多说无益,我们直接来看代码实战,还是以上证综指18年以来的数据为例,先获取数据:
import pandas as pd
import tushare as ts
pro = ts.pro_api()
index_sh = pro.index_daily(ts_code='000001.SH', start_date='20180101')
index_sh.index = pd.to_datetime(index_sh.trade_date)
index_sh = index_sh.sort_index(ascending=True)
index_sh.head()

在这里我们将交易日期转换为了时间序列数据,并且作为了我们DataFrame的索引。然后我们开始求18年以来的收益趋势:
value = (index_sh.pct_chg / 100 + 1).cumprod()
value.plot();

可以看到,几乎从头跌到尾……
然后我们开始计算最大回撤率:
MDD = (value.cummax() - value).max()
print('最大回撤:', MDD)
mdd = ((value.cummax() - value) / value.cummax()).max()
print('最大回撤率:', mdd)

可以看到,这里我们计算的最大回撤率是30.77%,与刚才我们手动计算的31.95%并不一致,为什么呢?
这是因为,这里我们是使用的收益率数据,而收益率数据都是以收盘价计算的,这里我们损耗了最高价、最低价的信息,所以我们看到的最大回撤率比实际情况稍低。不过对于基金净值、组合资产等,我们一般也更关注收盘价数据,对于盘中的波动相对来说没有那么重视。