多目标优化简介
多目标优化问题
在很多实际工程问题中,我们的优化目标不止一个,而是对多个目标函数求一个综合最优解。例如在物流配送问题中,不仅要求配送路径最短,还可能需要参与运输车辆最少等。
多目标优化问题的数学模型可以表达为:
多目标优化问题通常具有如下特点:
- 各目标函数往往相互冲突,无法同时取到最优解。这种冲突使得解的搜索变得更加复杂;
- 各目标函数的单位不同,不能简单比较。因此多目标优化问题的合理解集通常是Pareto最优解。
多目标优化求解思路
对于多目标优化问题,传统方法是将原问题通过加权方式变换为单目标优化问题,进而求得最优解。该方法具有两大问题:
- 权重的量化设定困难;
- 多目标优化问题的求解结果是包含一组非支配解的解集,用这种方法每次只能求得一个不同解(运气好的话),要求解具有足够多样性的Pareto最优解集非常困难。
遗传算法具有多点多方向搜索的特征,在一次搜索中可以得到多个Pareto最优解,因此更适合求解多目标优化问题。
而当前用于求解多目标优化问题的遗传算法一般有两种思路:
- Pareto排序评价方法:其思想是构造基于解的优劣关系排序的适应值函数;在子代中更多保留非支配解,从而在迭代一定次数后获得Pareto前沿。最经典的是Glodberg提出的Pareto ranking genetic algorithm,另外我们这里介绍的NSGA-II也是基于Pareto排序评价的方法。
- 多目标函数加权方法:给多目标函数加以各种权重,转化为单目标优化问题;相对于传统方法中的固定权重,这类方法通常会在遗传操作前以一定规律生成权重,指导个体的多方向搜索。代表性的算法有Ishibuchi的random weight GA和Gen-Cheng的adaptive weight GA等。
NSGA-II算法解析
NSGA-II(nondominated sorting genetic algorithm II)是2002年Deb教授提出的NSGA的改进型,这个算法主要解决了第一版NSGA的三个痛点:
- 非支配排序的高计算复杂度
- 共享参数难以确定
- 缺少保存精英策略
针对这三个问题,在NSGA-II中,Deb提出了快速非支配排序算子,引入了保存精英策略,并用“拥挤距离”(crowding distance)替代了共享(sharing)。
在介绍NSGA-II的整体流程之前,我们需要先了解快速非支配排序和拥挤距离的定义。
快速非支配排序(Fast non-dominated sort)
解的支配关系与Pareto最优解
在最小化问题中,对于两个解,如果对于任意的目标函数,都有,称支配。
如果对于任意的目标函数,都有,称强支配。
下图表示了解之间的支配和强支配关系:

若解空间中不存在强支配的解,则称为弱Pareto最优解。
若解空间中不存在支配的解,则称为Pareto最优解。
下图表示了一个最小化问题解集中的Pareto最优解和Pareto弱最优解:

快速非支配排序步骤
快速非支配排序就是将解集分解为不同次序的Pareto前沿的过程。
它可以描述为:
- 为每个解分配两个关键量:支配的解个数以及被支配的解集;
- 设置,将的个体归入;
- 对于中的个体,遍历每个解的,将其中每个解的减1;
- ,将中的解归入;
- 重复3、4,直到解集中所有个体都被归入某一个。

DEAP实现
DEAP内置了实现快速非支配排序操作的函数tools.emo.sortNondominated
tools.emo.sortNondominated(individuals, k, first_front_only=False)
参数:
- individuals:被排序的个体列表
- k:需要选择的个体个数。注意这里不一定会返回正好k个个体,需要看pareto前沿的个体个数:假设设置
k=100,而selectedPop+len(Front[i-1])<100,返回的个数会是selectedPop+len(Front[i-1])+len(Front[i]),应该是一个大于100的值。 - first_front_only:如果设为'True'则对次序为1的前沿排序之后就返回
返回:
- Pareto前沿的列表
拥挤距离计算(Crowding distance assignment)
拥挤距离的定义
在NSGA II中,为了衡量在同一个前沿中各个解质量的优劣,作者为每个解分配了一个拥挤距离。其背后的思想是让求得的Pareto最优解在objective space中尽量分散。也就有更大可能让解在Pareto最优前沿上均匀分布。
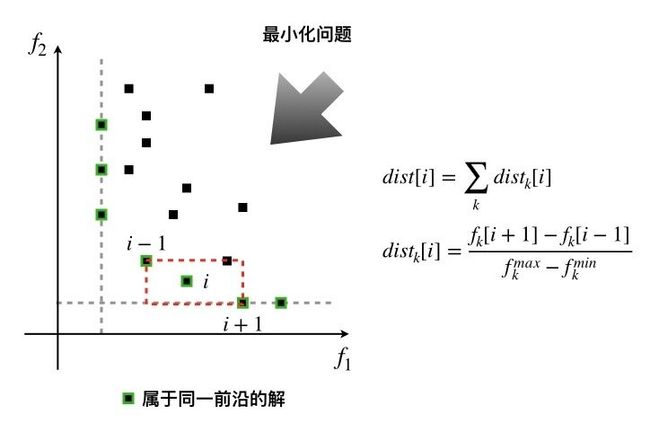
DEAP实现
DEAP中内置了计算拥挤距离的函数tools.emo.assignCrowdingDist
tools.emo.assignCrowdingDist(individuals)
参数:
- individuals:用来计算拥挤距离的个体列表
返回:
- 没有返回值,拥挤距离保存在传入的individuals中的每个个体的individual.fitness.crowding_dist属性中
精英保存策略(Elitism)
比较操作
根据快速非支配排序和拥挤距离计算的结果,对族群中的个体进行排序:
对两个解,
- 如果,那么解较更优;
- 如果,而,那么解较更优;
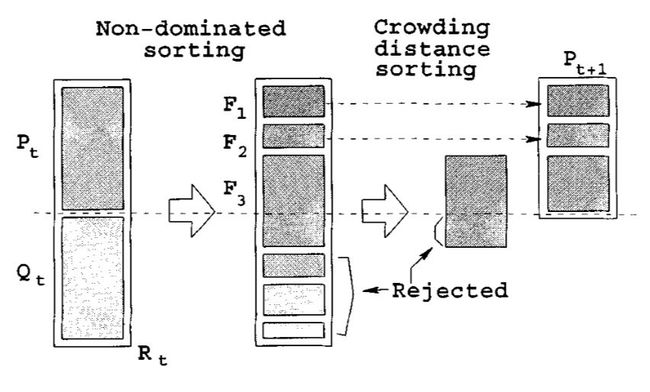
在每个迭代步的最后,将父代与子代合为一个族群,依照比较操作对合并后族群中的个体进行排序,然后从中选取数量等同于父代规模的优秀子代,这就是NSGA-II算法中的精英保存策略。
DEAP实现
DEAP内置了实现NSGA-II中的基于拥挤度的选择函数tools.selNSGA2用来实现精英保存策略:
tools.selNSGA2(individuals, k, nd='standard')
参数:
- individuals:被选择的个体列表,在NSGA-II中是父代与子代的并集
- k:需要选择的个体个数,通常要比被选择的个体数量小;如果与被选择的个体数量相同,那么效果等同于基于pareto前沿的排序
- nd:选择使用的非支配(non-dominated)算法,可以设置为'standard'或'log'
返回:
- 被选择的个体列表
NSGA算法实现
测试函数
这里选用ZDT3函数作为测试函数,函数可表达为:
其Pareto最优解集为
这里为了方便可视化取。
下图给出了该函数在Decision Space和Objective Space中的对应:

其pareto最优解在Objective Space中如下图红点所示:

代码实现
#-------------- NSGA-II 算法实现-----------
## 问题定义
creator.create('MultiObjMin', base.Fitness, weights=(-1.0, -1.0))
creator.create('Individual', list, fitness=creator.MultiObjMin)
## 个体编码
def uniform(low, up):
# 用均匀分布生成个体
return [random.uniform(a,b) for a,b in zip(low, up)]
toolbox = base.Toolbox()
NDim = 2 # 变量数为2
low = [0]*NDim # 变量下界
up = [1]*NDim # 变量上界
toolbox.register('attr_float', uniform, low, up)
toolbox.register('individual', tools.initIterate, creator.Individual, toolbox.attr_float)
toolbox.register('population', tools.initRepeat, list, toolbox.individual)
## 评价函数
def ZDT3(ind):
# ZDT3评价函数,ind长度为2
n = len(ind)
f1 = ind[0]
g = 1 + 9 * np.sum(ind[1:]) / (n-1)
f2 = g * (1 - np.sqrt(ind[0]/g) - ind[0]/g * np.sin(10*np.pi*ind[0]))
return f1, f2
toolbox.register('evaluate', ZDT3)
## 注册工具
toolbox.register('selectGen1', tools.selTournament, tournsize=2)
toolbox.register('select', tools.emo.selTournamentDCD) # 该函数是binary tournament,不需要tournsize
toolbox.register('mate', tools.cxSimulatedBinaryBounded, eta=20.0, low=low, up=up)
toolbox.register('mutate', tools.mutPolynomialBounded, eta=20.0, low=low, up=up, indpb=1.0/NDim)
## 遗传算法主程序
# 参数设置
toolbox.popSize = 100
toolbox.maxGen = 200
toolbox.cxProb = 0.7
toolbox.mutateProb = 0.2
# 迭代部分
# 第一代
pop = toolbox.population(toolbox.popSize) # 父代
fitnesses = toolbox.map(toolbox.evaluate, pop)
for ind, fit in zip(pop,fitnesses):
ind.fitness.values = fit
fronts = tools.emo.sortNondominated(pop, k=toolbox.popSize)
# 将每个个体的适应度设置为pareto前沿的次序
for idx, front in enumerate(fronts):
for ind in front:
ind.fitness.values = (idx+1),
# 创建子代
offspring = toolbox.selectGen1(pop, toolbox.popSize) # binary Tournament选择
offspring = algorithms.varAnd(offspring, toolbox, toolbox.cxProb, toolbox.mutateProb)
# 第二代之后的迭代
for gen in range(1, toolbox.maxGen):
combinedPop = pop + offspring # 合并父代与子代
# 评价族群
fitnesses = toolbox.map(toolbox.evaluate, combinedPop)
for ind, fit in zip(combinedPop,fitnesses):
ind.fitness.values = fit
# 快速非支配排序
fronts = tools.emo.sortNondominated(combinedPop, k=toolbox.popSize, first_front_only=False)
# 拥挤距离计算
for front in fronts:
tools.emo.assignCrowdingDist(front)
# 环境选择 -- 精英保留
pop = []
for front in fronts:
pop += front
pop = toolbox.clone(pop)
pop = tools.selNSGA2(pop, k=toolbox.popSize, nd='standard')
# 创建子代
offspring = toolbox.select(pop, toolbox.popSize)
offspring = toolbox.clone(offspring)
offspring = algorithms.varAnd(offspring, toolbox, toolbox.cxProb, toolbox.mutateProb)
将结果可视化:
# front = tools.emo.sortNondominated(pop, len(pop))[0]
for ind in front:
plt.plot(ind.fitness.values[0], ind.fitness.values[1], 'r.', ms=2)
for ind in gridPop:
plt.plot(ind.fitness.values[0], ind.fitness.values[1], 'b.', ms=1)
plt.title('Pareto optimal front derived with NSGA-II', fontsize=12)
plt.xlabel('$f_1$')
plt.ylabel('$f_2$')
plt.tight_layout()
plt.savefig('Pareto_optimal_front_derived_with_NSGA-II.png')
得到:

可以看到NSGA-II算法得到的Pareto最优前沿质量很高:最优解均匀分布在不连续前沿的各个线段上;同时在最优前沿以外没有个体存在。