- 理解Gunicorn:Python WSGI服务器的基石
范范0825
ipythonlinux运维
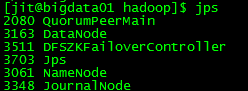
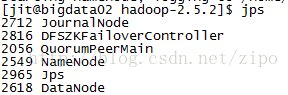
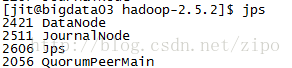
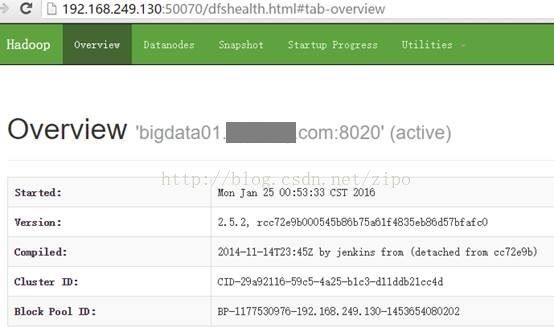
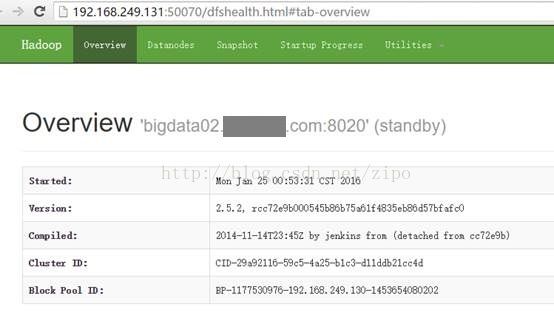
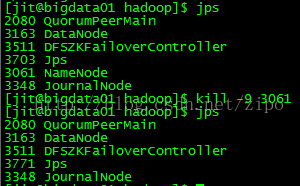
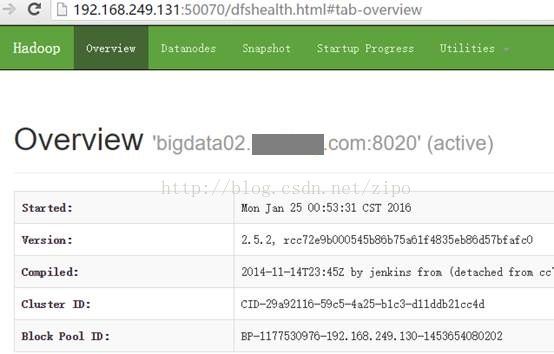
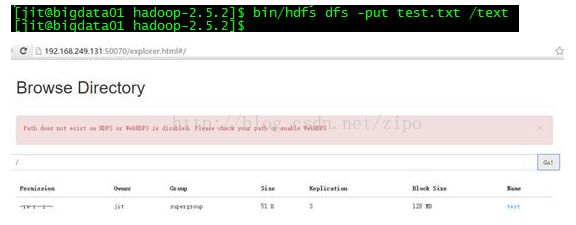
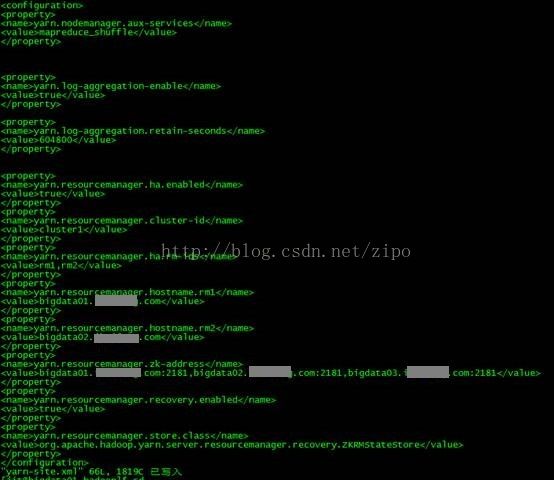
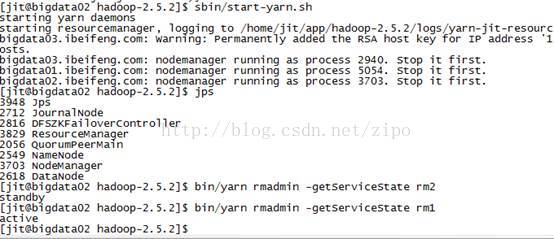
理解Gunicorn:PythonWSGI服务器的基石介绍Gunicorn,全称GreenUnicorn,是一个为PythonWSGI(WebServerGatewayInterface)应用设计的高效、轻量级HTTP服务器。作为PythonWeb应用部署的常用工具,Gunicorn以其高性能和易用性著称。本文将介绍Gunicorn的基本概念、安装和配置,帮助初学者快速上手。1.什么是Gunico
- 瑶池防线
谜影梦蝶
冥华虽然逃过了影梦的军队,但他是一个忠臣,他选择上报战况。败给影梦后成逃兵,高层亡尔还活着,七重天失守......随便一条,即可处死冥华。冥华自然是知道以仙界高层的习性此信一发自己必死无疑,但他还选择上报实情,因为责任。同样此信送到仙宫后,知道此事的人,大多数人都认定冥华要完了,所以上到仙界高层,下到扫大街的,包括冥华自己,全都准备好迎接冥华之死。如果仙界现在还属于两方之争的话,冥华必死无疑。然而
- swagger访问路径
igotyback
swagger
Swagger2.x版本访问地址:http://{ip}:{port}/{context-path}/swagger-ui.html{ip}是你的服务器IP地址。{port}是你的应用服务端口,通常为8080。{context-path}是你的应用上下文路径,如果应用部署在根路径下,则为空。Swagger3.x版本对于Swagger3.x版本(也称为OpenAPI3)访问地址:http://{ip
- 绘本讲师训练营【24期】8/21阅读原创《独生小孩》
1784e22615e0
24016-孟娟《独生小孩》图片发自App今天我想分享一个蛮特别的绘本,讲的是一个特殊的群体,我也是属于这个群体,80后的独生小孩。这是一本中国绘本,作者郭婧,也是一个80厚。全书一百多页,均为铅笔绘制,虽然为黑白色调,但并不显得沉闷。全书没有文字,犹如“默片”,但并不影响读者对该作品的理解,反而显得神秘,梦幻,給读者留下想象的空间。作者在前蝴蝶页这样写到:“我更希望父母和孩子一起分享这本书,使他
- 放下是一段成长的修行
小莳玥
人来到这个世界上,只有两件事:生和死。一件事已经做完了,另一件你还急什么呢?是人,都有七情六欲。是心,都有喜怒哀乐,这些再正常不过了。别总抱怨自己活得累,过得辛苦。永远记住:舒坦是留给死人的。苦,才是生活;累,才是工作;变,才是命运;忍,才是历练;容,才是智慧;静,才是修养;舍,才会得到;做,才会拥有。人生,活得太清楚,才是最大的不明白。有些事,看得很清,却说不清;有些人,了解很深,却猜不透;有些
- 使用 FinalShell 进行远程连接(ssh 远程连接 Linux 服务器)
编程经验分享
开发工具服务器sshlinux
目录前言基本使用教程新建远程连接连接主机自定义命令路由追踪前言后端开发,必然需要和服务器打交道,部署应用,排查问题,查看运行日志等等。一般服务器都是集中部署在机房中,也有一些直接是云服务器,总而言之,程序员不可能直接和服务器直接操作,一般都是通过ssh连接来登录服务器。刚接触远程连接时,使用的是XSHELL来远程连接服务器,连接上就能够操作远程服务器了,但是仅用XSHELL并没有上传下载文件的功能
- 如果做到轻松在股市赚钱?只要坚持这三个原则。
履霜之人
大A股里向来就有七亏二平一赚的说法,能赚钱的都是少数人。否则股市就成了慈善机构,人人都有钱赚,谁还要上班?所以说亏钱是正常的,或者说是应该的。那么那些赚钱的人又是如何做到的呢?普通人能不能找到捷径去分一杯羹呢?方法是有的,但要做到需要你有极高的自律。第一,控制仓位,散户最大的问题是追涨杀跌,只要涨起来,就把钱往股票上砸,然后被套,隔天跌的受不了,又一刀切,全部割肉。来来回回间,遍体鳞伤。所以散户首
- DIV+CSS+JavaScript技术制作网页(旅游主题网页设计与制作)云南大理
STU学生网页设计
网页设计期末网页作业html静态网页html5期末大作业网页设计web大作业
️精彩专栏推荐作者主页:【进入主页—获取更多源码】web前端期末大作业:【HTML5网页期末作业(1000套)】程序员有趣的告白方式:【HTML七夕情人节表白网页制作(110套)】文章目录二、网站介绍三、网站效果▶️1.视频演示2.图片演示四、网站代码HTML结构代码CSS样式代码五、更多源码二、网站介绍网站布局方面:计划采用目前主流的、能兼容各大主流浏览器、显示效果稳定的浮动网页布局结构。网站程
- 在一台Ubuntu计算机上构建Hyperledger Fabric网络
落叶无声9
区块链超级账本Hyperledgerfabric区块链ubuntu构建hyperledgerfabric
在一台Ubuntu计算机上构建HyperledgerFabric网络Hyperledgerfabric是一个开源的区块链应用程序平台,为开发基于区块链的应用程序提供了一个起点。当我们提到HyperledgerFabric网络时,我们指的是使用HyperledgerFabric的正在运行的系统。即使只使用最少数量的组件,部署Fabric网络也不是一件容易的事。Fabric社区创建了一个名为Cello
- git - Webhook让部署自动化
大猪大猪
我们现在有一个需求,将项目打包上传到gitlab或者github后,程序能自动部署,不用手动地去服务器中进行项目更新并运行,如何做到?这里我们可以使用gitlab与github的挂钩,挂钩的原理就是,每当我们有请求到gitlab与github服务器时,这时他俩会根据我们配置的挂钩地扯进行访问,webhook挂钩程序会一直监听着某个端口请求,一但收到他们发过来的请求,这时就知道用户有请求提交了,这时
- Python 实现图片裁剪(附代码) | Python工具
剑客阿良_ALiang
前言本文提供将图片按照自定义尺寸进行裁剪的工具方法,一如既往的实用主义。环境依赖ffmpeg环境安装,可以参考我的另一篇文章:windowsffmpeg安装部署_阿良的博客-CSDN博客本文主要使用到的不是ffmpeg,而是ffprobe也在上面这篇文章中的zip包中。ffmpy安装:pipinstallffmpy-ihttps://pypi.douban.com/simple代码不废话了,上代码
- 2019-3-23晨间日记
红红火火小耳朵
今天是什么日子起床:7点40就寝:23点半天气:有太阳,不过一会儿出来一会儿进去特别清爽的凉意,还蛮舒服的心情:小激动要给女朋友过生日啦纪念日:田田女士过生日任务清单昨日完成的任务,最重要的三件事:1.英语一对一2.运动计划3.认真护肤习惯养成:调整状态周目标·完成进度英语七天打卡(5/7)轻课阅读(87/180)音标课(25/30)读书(福尔摩斯一章)学习·信息·阅读#英语课#Cookingte
- 【无标题】达瓦达瓦
JhonKI
考研
博客主页:https://blog.csdn.net/2301_779549673欢迎点赞收藏⭐留言如有错误敬请指正!本文由JohnKi原创,首发于CSDN未来很长,值得我们全力奔赴更美好的生活✨文章目录前言111️111❤️111111111111111总结111前言111骗骗流量券,嘿嘿111111111111111111111111111️111❤️111111111111111总结11
- 上图为是否色发
JhonKI
考研
博客主页:https://blog.csdn.net/2301_779549673欢迎点赞收藏⭐留言如有错误敬请指正!本文由JohnKi原创,首发于CSDN未来很长,值得我们全力奔赴更美好的生活✨文章目录前言111️111❤️111111111111111总结111前言111骗骗流量券,嘿嘿111111111111111111111111111️111❤️111111111111111总结11
- 143234234123432
JhonKI
考研
博客主页:https://blog.csdn.net/2301_779549673欢迎点赞收藏⭐留言如有错误敬请指正!本文由JohnKi原创,首发于CSDN未来很长,值得我们全力奔赴更美好的生活✨文章目录前言111️111❤️111111111111111总结111前言111骗骗流量券,嘿嘿111111111111111111111111111️111❤️111111111111111总结11
- 道阻且长,行则将至
sweet橘子
本文参与书香澜梦主题征文“行”文章原创首发,文责自负。我们每一个人都应该有属于自己的愿望或者是理想,人一但有了理想也就算是有了方向,它就会像灯塔一样指引我们前进的方向,哪怕是再远大的理想,如果坚持,那么我相信它就一定有收获。屈原是我最喜欢的一个浪漫主义的诗人,他曾今说过:“路漫漫其修远兮,吾将上下而求索。”人生的道路很长,但是为了实现自己的理想抱负我愿意付出我毕生的精力,只专注这一件事,因为“道阻
- 【勾心原创】《去年夏天》
不勾心的豆角
(原创作者:不勾心的豆角)本期【勾心原创】,继续本人不勾心的豆角的现代诗创作之旅。《去年夏天》原创作者:不勾心的豆角那里芳草茵茵绿柳成行澄净蓝天下屋顶们相亲相爱闪着橙色紫色的馨香溪流温柔偎依着村庄牛儿羊儿信步徜徉还有成群的白鸽在尖顶的教堂盘旋歌唱孩子们是自由的蒲公英奔跑在希望的田野上任由天真的笑声肆无忌惮烂漫这人间天堂夜幕小心翼翼呵护着甜美的梦乡只剩尽职的晚风陪伴顽皮的星子们游荡快告诉我心爱的姑娘
- 【六】阿伟开始搭建Kafka学习环境
能源恒观
中间件学习kafkaspring
阿伟开始搭建Kafka学习环境概述上一篇文章阿伟学习了Kafka的核心概念,并且把市面上流行的消息中间件特性进行了梳理和对比,方便大家在学习过程中进行对比学习,最后梳理了一些Kafka使用中经常遇到的Kafka难题以及解决思路,经过上一篇的学习我相信大家对Kafka有了初步的认识,本篇将继续学习Kafka。一、安装和配置学习一项技术首先要搭建一套服务,而Kafka的运行主要需要部署jdk、zook
- openssl+keepalived安装部署
_小亦_
项目部署keepalivedopenssl
文章目录OpenSSL安装下载地址编译安装修改系统配置版本Keepalived安装下载地址安装遇到问题安装完成配置文件keepalived运行检查运行状态查看系统日志修改服务service重新加载systemd检查配置文件语法错误OpenSSL安装下载地址考虑到后面设备可能没法连接到外网,所以采用安装包的方式进行部署,下载地址:https://www.openssl.org/source/old/
- 2021-07-31
比峰
七月的最后一天,过了今天,就是八月,心脏在颤抖……昨天两点半才睡,一直在以两倍的语速的听之前的课程,虽然隔得时间不长,但是很多知识点已经忘了差不多了,为了让自己能够掌握的稍微全面一点,还是磨刀不误砍柴工的比较好。正因为晚上睡得晚,今天一上午的状态都不好,也可能因为上午都是待在家里,所以多数时间自己是在补觉。既然太累,那就睡觉吧,总比浪费时间的好。下午到咖啡馆做题,一道差错更正一下子让自己的实力暴露
- 摘选《靠谱》
海伦美少女
作家池莉说:“靠谱,说起来简单,落下去复杂;听起来像感觉,做起来是原则。”靠谱的人,为人正直有原则,做事稳重重诺言。在他们眼里,人品比钱财重要,良心比利益可贵。和他们深交,不用防备,无需猜疑,相处最是舒心。魏晋名士嵇康和山涛,同为竹林七贤,两人私交甚笃。后来,山涛出仕为司马氏效力,嵇康则隐居山林。山涛几次举荐嵇康入朝为官,都被嵇康拒绝,最后甚至写下了绝交书。世人都认为两人恩断义绝,可两年后,嵇康遭
- 上班的路
毛毛虫小姑娘
七点半起床,拉开窗帘,天公不作美今儿是个阴雨天,天灰蒙蒙的,毛毛雨细细密密洒落下来。脑海里的两个小人开始斗争了,一个说:“毛毛雨啦,穿着风衣打着伞穿行在雨中,是一道亮丽的风景,说不定能遇见帅哥呢!”一个说:“不要不要,走到公司衣服鞋子都潮呼呼的,趴在身上很不舒服,外面湿气这么重,对身体不好!”我思索片刻,慢吞吞为自己冲了杯五谷粉,悠哉悠哉喝完去坐班车了。
- 《如不承诺天长地久,怎会相遇细水长流》文/苏暖人
北京大数据苏焕之
《如不承诺天长地久,怎会相遇细水长流》文/苏暖人原创——莫转载粘贴有人选择昙花一现,如大理的花海,有人选择细水长流,如雨夜的浪漫。都说,五分喜欢的人恨不得将他挂在嘴边,十分喜欢的人却只舍得放在心里边了,在爱情眼里,对方说的每一句话都在乎你的感受,TA的眼里也只有你,我想也是这样!说起我的爱情,我也喜欢过一个忧郁的女孩,她喜欢的男孩不喜欢她,于是我成了她倾诉的朋友+备胎,一年来我们互相推荐伤感的歌曲
- 古风原创
慕白漓
【江南月】词:慕白漓曲:《庐州月》西厢一语惊醒梦中月光佳人为何素眉不添淡妆抚帕刺秀绵缎一缕清香南望飞雁又归西方城外又闻秋稻泛黄成殇细雨纷飞里春又归乡离家而去的你是否迷失彷徨一句诺言永记心上家书一封道尽咏平常青草才青暮色又飘扬等也难当回又何妨古拙的山水今又细水流长江南月光照耀湖旁如今的情也已不在心上十载月晃容颜覆黄问一句你今在他乡何方江南月光苏州城隍孤单的你可还记得夜凉西厢人忘你是否还在独唱却唱不出
- 「原创」海丰阿东:人若不死生有何欢,长命百岁只是梦想
海丰阿东
「原创」海丰阿东:人若不死生有何欢,长命百岁只是梦想有生必有死,人生的规律如此,任何人都无法回避。但如果一个人能长命百岁,永远活着,其实也并不是一件好事情。你永远活着,在你身边那些熟悉的东西都渐渐的离你而去,你成了一个孤家寡人。最后你只能在回忆中生活着,一定是十分的孤独啊。其实有生必有死,因为死亡的存在,让生便有了意义。人活着才有价值,正是因为有死亡,才凸显出来了。编辑当然了,同样是活着也会产生不
- 可以赚钱的app,你们都在用哪些?
配音新手圈
1.七猫免费小说2.有柿3.番茄小说兼职副业推荐公众号,配音新手圈,声优配音圈,新配音兼职圈,配音就业圈,鼎音副业,有声新手圈,每天更新各种远程工作与在线兼职,职位包括:写手、程序开发、剪辑、设计、翻译、配音、无门槛、插画、翻译、等等。。。每日更新兼职。4.速读免费小说5.得间免费小说6.快手7.快手极速8.抖音火山版(可提0.2,可能我懒赚的慢,但真不推荐)9.拼多多10.淘宝11.点淘12.美
- 七月你好
茗蕙原创
告别了说变天就变的六月正值七月酷暑之时没有嬉戏的鱼水之乐站在窗边抬头望着蔚蓝天空万里无云万里天七月你好在月末的几天里在家期盼出门时的喜悦别样的天气别样的心情七月你好让大地经受着煎熬让空气中充呲着滚滚热浪去抵御往年严冬带来的湿气七月你好你的到来如逢甘露愿你带来的温暖去除病菌让人们重新看到生活的希望向往南山一角
- IBM反垄断史:一个什么都卖的兼并指挥家
竞争者的垄断梦
真事/故事/反垄断的故事/大公司垄断的故事曲创(原创)欢迎关注竞争者的垄断梦感谢已经看到这里的各位,因为间隔时间有点长,可能各位有点迷失。大家千万别误会,我们这一季的男一号既不是Hollerith,也不是Powers。到目前为止他俩的戏份真是不少,但只是因为必不可少,没有他俩发明的制表机,也就没有IBM;没有他俩相爱相杀的暧昧关系,也就没有后来数十年里IBM和反垄断的苦恋悲情。这是一个漫长的悲伤故
- 这段婚姻还有必要持继续下去吗?
2020从这里开始
今夜辗转难眠,脑海一直在思考以后的路怎么走,是继续,还是结束?“七年之痒”对我的婚姻也真的是如期而至。七年前的前天领的结婚证,七年后的今晚我们却在沟通如何修补我们的婚姻,当初结婚与他于我都是因为大龄青年,在家里父母催促下,当时双方相处也觉得合适。在认识恋爱半年后便匆匆结婚,因为我彼此性格都属于不善表达,也不喜好争吵,因此日常生活琐事的不满基本都几语带过,原以为平淡生活都是这么过的。未曾想这些怨愤都
- MongoDB知识概括
GeorgeLin98
持久层mongodb
MongoDB知识概括MongoDB相关概念单机部署基本常用命令索引-IndexSpirngDataMongoDB集成副本集分片集群安全认证MongoDB相关概念业务应用场景:传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。解释:“三高”需求:①Highperformance-对数据库高并发读写的需求。②HugeStorage-对海量数
- ASM系列四 利用Method 组件动态注入方法逻辑
lijingyao8206
字节码技术jvmAOP动态代理ASM
这篇继续结合例子来深入了解下Method组件动态变更方法字节码的实现。通过前面一篇,知道ClassVisitor 的visitMethod()方法可以返回一个MethodVisitor的实例。那么我们也基本可以知道,同ClassVisitor改变类成员一样,MethodVIsistor如果需要改变方法成员,注入逻辑,也可以
- java编程思想 --内部类
百合不是茶
java内部类匿名内部类
内部类;了解外部类 并能与之通信 内部类写出来的代码更加整洁与优雅
1,内部类的创建 内部类是创建在类中的
package com.wj.InsideClass;
/*
* 内部类的创建
*/
public class CreateInsideClass {
public CreateInsideClass(
- web.xml报错
crabdave
web.xml
web.xml报错
The content of element type "web-app" must match "(icon?,display-
name?,description?,distributable?,context-param*,filter*,filter-mapping*,listener*,servlet*,s
- 泛型类的自定义
麦田的设计者
javaandroid泛型
为什么要定义泛型类,当类中要操作的引用数据类型不确定的时候。
采用泛型类,完成扩展。
例如有一个学生类
Student{
Student(){
System.out.println("I'm a student.....");
}
}
有一个老师类
- CSS清除浮动的4中方法
IT独行者
JavaScriptUIcss
清除浮动这个问题,做前端的应该再熟悉不过了,咱是个新人,所以还是记个笔记,做个积累,努力学习向大神靠近。CSS清除浮动的方法网上一搜,大概有N多种,用过几种,说下个人感受。
1、结尾处加空div标签 clear:both 1 2 3 4
.div
1
{
background
:
#000080
;
border
:
1px
s
- Cygwin使用windows的jdk 配置方法
_wy_
jdkwindowscygwin
1.[vim /etc/profile]
JAVA_HOME="/cgydrive/d/Java/jdk1.6.0_43" (windows下jdk路径为D:\Java\jdk1.6.0_43)
PATH="$JAVA_HOME/bin:${PATH}"
CLAS
- linux下安装maven
无量
mavenlinux安装
Linux下安装maven(转) 1.首先到Maven官网
下载安装文件,目前最新版本为3.0.3,下载文件为
apache-maven-3.0.3-bin.tar.gz,下载可以使用wget命令;
2.进入下载文件夹,找到下载的文件,运行如下命令解压
tar -xvf apache-maven-2.2.1-bin.tar.gz
解压后的文件夹
- tomcat的https 配置,syslog-ng配置
aichenglong
tomcathttp跳转到httpssyslong-ng配置syslog配置
1) tomcat配置https,以及http自动跳转到https的配置
1)TOMCAT_HOME目录下生成密钥(keytool是jdk中的命令)
keytool -genkey -alias tomcat -keyalg RSA -keypass changeit -storepass changeit
- 关于领号活动总结
alafqq
活动
关于某彩票活动的总结
具体需求,每个用户进活动页面,领取一个号码,1000中的一个;
活动要求
1,随机性,一定要有随机性;
2,最少中奖概率,如果注数为3200注,则最多中4注
3,效率问题,(不能每个人来都产生一个随机数,这样效率不高);
4,支持断电(仍然从下一个开始),重启服务;(存数据库有点大材小用,因此不能存放在数据库)
解决方案
1,事先产生随机数1000个,并打
- java数据结构 冒泡排序的遍历与排序
百合不是茶
java
java的冒泡排序是一种简单的排序规则
冒泡排序的原理:
比较两个相邻的数,首先将最大的排在第一个,第二次比较第二个 ,此后一样;
针对所有的元素重复以上的步骤,除了最后一个
例题;将int array[]
- JS检查输入框输入的是否是数字的一种校验方法
bijian1013
js
如下是JS检查输入框输入的是否是数字的一种校验方法:
<form method=post target="_blank">
数字:<input type="text" name=num onkeypress="checkNum(this.form)"><br>
</form>
- Test注解的两个属性:expected和timeout
bijian1013
javaJUnitexpectedtimeout
JUnit4:Test文档中的解释:
The Test annotation supports two optional parameters.
The first, expected, declares that a test method should throw an exception.
If it doesn't throw an exception or if it
- [Gson二]继承关系的POJO的反序列化
bit1129
POJO
父类
package inheritance.test2;
import java.util.Map;
public class Model {
private String field1;
private String field2;
private Map<String, String> infoMap
- 【Spark八十四】Spark零碎知识点记录
bit1129
spark
1. ShuffleMapTask的shuffle数据在什么地方记录到MapOutputTracker中的
ShuffleMapTask的runTask方法负责写数据到shuffle map文件中。当任务执行完成成功,DAGScheduler会收到通知,在DAGScheduler的handleTaskCompletion方法中完成记录到MapOutputTracker中
- WAS各种脚本作用大全
ronin47
WAS 脚本
http://www.ibm.com/developerworks/cn/websphere/library/samples/SampleScripts.html
无意中,在WAS官网上发现的各种脚本作用,感觉很有作用,先与各位分享一下
获取下载
这些示例 jacl 和 Jython 脚本可用于在 WebSphere Application Server 的不同版本中自
- java-12.求 1+2+3+..n不能使用乘除法、 for 、 while 、 if 、 else 、 switch 、 case 等关键字以及条件判断语句
bylijinnan
switch
借鉴网上的思路,用java实现:
public class NoIfWhile {
/**
* @param args
*
* find x=1+2+3+....n
*/
public static void main(String[] args) {
int n=10;
int re=find(n);
System.o
- Netty源码学习-ObjectEncoder和ObjectDecoder
bylijinnan
javanetty
Netty中传递对象的思路很直观:
Netty中数据的传递是基于ChannelBuffer(也就是byte[]);
那把对象序列化为字节流,就可以在Netty中传递对象了
相应的从ChannelBuffer恢复对象,就是反序列化的过程
Netty已经封装好ObjectEncoder和ObjectDecoder
先看ObjectEncoder
ObjectEncoder是往外发送
- spring 定时任务中cronExpression表达式含义
chicony
cronExpression
一个cron表达式有6个必选的元素和一个可选的元素,各个元素之间是以空格分隔的,从左至右,这些元素的含义如下表所示:
代表含义 是否必须 允许的取值范围 &nb
- Nutz配置Jndi
ctrain
JNDI
1、使用JNDI获取指定资源:
var ioc = {
dao : {
type :"org.nutz.dao.impl.NutDao",
args : [ {jndi :"jdbc/dataSource"} ]
}
}
以上方法,仅需要在容器中配置好数据源,注入到NutDao即可.
- 解决 /bin/sh^M: bad interpreter: No such file or directory
daizj
shell
在Linux中执行.sh脚本,异常/bin/sh^M: bad interpreter: No such file or directory。
分析:这是不同系统编码格式引起的:在windows系统中编辑的.sh文件可能有不可见字符,所以在Linux系统下执行会报以上异常信息。
解决:
1)在windows下转换:
利用一些编辑器如UltraEdit或EditPlus等工具
- [转]for 循环为何可恨?
dcj3sjt126com
程序员读书
Java的闭包(Closure)特征最近成为了一个热门话题。 一些精英正在起草一份议案,要在Java将来的版本中加入闭包特征。 然而,提议中的闭包语法以及语言上的这种扩充受到了众多Java程序员的猛烈抨击。
不久前,出版过数十本编程书籍的大作家Elliotte Rusty Harold发表了对Java中闭包的价值的质疑。 尤其是他问道“for 循环为何可恨?”[http://ju
- Android实用小技巧
dcj3sjt126com
android
1、去掉所有Activity界面的标题栏
修改AndroidManifest.xml 在application 标签中添加android:theme="@android:style/Theme.NoTitleBar"
2、去掉所有Activity界面的TitleBar 和StatusBar
修改AndroidManifes
- Oracle 复习笔记之序列
eksliang
Oracle 序列sequenceOracle sequence
转载请出自出处:http://eksliang.iteye.com/blog/2098859
1.序列的作用
序列是用于生成唯一、连续序号的对象
一般用序列来充当数据库表的主键值
2.创建序列语法如下:
create sequence s_emp
start with 1 --开始值
increment by 1 --増长值
maxval
- 有“品”的程序员
gongmeitao
工作
完美程序员的10种品质
完美程序员的每种品质都有一个范围,这个范围取决于具体的问题和背景。没有能解决所有问题的
完美程序员(至少在我们这个星球上),并且对于特定问题,完美程序员应该具有以下品质:
1. 才智非凡- 能够理解问题、能够用清晰可读的代码翻译并表达想法、善于分析并且逻辑思维能力强
(范围:用简单方式解决复杂问题)
- 使用KeleyiSQLHelper类进行分页查询
hvt
sql.netC#asp.nethovertree
本文适用于sql server单主键表或者视图进行分页查询,支持多字段排序。KeleyiSQLHelper类的最新代码请到http://hovertree.codeplex.com/SourceControl/latest下载整个解决方案源代码查看。或者直接在线查看类的代码:http://hovertree.codeplex.com/SourceControl/latest#HoverTree.D
- SVG 教程 (三)圆形,椭圆,直线
天梯梦
svg
SVG <circle> SVG 圆形 - <circle>
<circle> 标签可用来创建一个圆:
下面是SVG代码:
<svg xmlns="http://www.w3.org/2000/svg" version="1.1">
<circle cx="100" c
- 链表栈
luyulong
java数据结构
public class Node {
private Object object;
private Node next;
public Node() {
this.next = null;
this.object = null;
}
public Object getObject() {
return object;
}
public
- 基础数据结构和算法十:2-3 search tree
sunwinner
Algorithm2-3 search tree
Binary search tree works well for a wide variety of applications, but they have poor worst-case performance. Now we introduce a type of binary search tree where costs are guaranteed to be loga
- spring配置定时任务
stunizhengjia
springtimer
最近因工作的需要,用到了spring的定时任务的功能,觉得spring还是很智能化的,只需要配置一下配置文件就可以了,在此记录一下,以便以后用到:
//------------------------定时任务调用的方法------------------------------
/**
* 存储过程定时器
*/
publi
- ITeye 8月技术图书有奖试读获奖名单公布
ITeye管理员
活动
ITeye携手博文视点举办的8月技术图书有奖试读活动已圆满结束,非常感谢广大用户对本次活动的关注与参与。
8月试读活动回顾:
http://webmaster.iteye.com/blog/2102830
本次技术图书试读活动的优秀奖获奖名单及相应作品如下(优秀文章有很多,但名额有限,没获奖并不代表不优秀):
《跨终端Web》
gleams:http