CopyOnWriteArrayList
无继承,实现了List,RandomAccess,Cloneable,和Serializable接口,具有List的特性,提供可随机访问,提供自身克隆以及序列化的一个容器类。
特点:线程安全;读写分离;数组实现
CopyOnWriteArrayList这个容器类的名字也很好理解,写时拷贝列表,网上对COW(CopyOnWrite)有一个高大上的名字,叫做读写分离,所以CopyOnWriteArrayList是读写分离列表类,下面描述下它的实现
成员变量
相比于ArrayList,CopyOnWriteArrayList的成员变量发生了很多改变,就只有下面几个
// 序列化ID
private static final long serialVersionUID = 8673264195747942595L;
// 锁变量
final transient ReentrantLock lock = new ReentrantLock();
// 真正存储数据的数组
private transient volatile Object[] array;
甚至是size都没了,而size()函数的实现则变成了下面这样
public int size() {
return getArray().length;
}
方法
首先是对array操作的限制,CopyOnWriteArrayList提供了array的setter和getter方法,在下文会看到,涉及到array的操作,都是通过setter和getter来完成的
final Object[] getArray() {
return array;
}
final void setArray(Object[] a) {
array = a;
}
其次是构造函数,CopyOnWriteArrayList提供了缺省,带集合类和带数组的三个构造函数,在这三个函数里面都能看到setArray()的影子。而其中,缺省的构造函数初始化容器的容量为0
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
public CopyOnWriteArrayList(Collection c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList)c).getArray();
else {
elements = c.toArray();
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elements.getClass() != Object[].class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
setArray(elements);
}
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
接着看最重头戏的add()方法,
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
我们可以看到,CopyOnWriteArrayList没有像ArrayList和Vector那样复杂的扩容机制,只通过两句代码即实现了添加数据,又实现了扩容
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
接着,在方法的开始和结束分别是上锁lock.lock();和解锁lock.unlock();,给方法上锁的一个原因是避免多线程环境下,多个线程拷贝出多个副本,然后多个副本操作数据后影响数据的正确性。
除了add()方法外,set(),remove()等的操作数据的操作,基本都和add()方法类似,这里就不在赘述了。
再接着看获取的方法get()
private E get(Object[] a, int index) {
return (E) a[index];
}
public E get(int index) {
return get(getArray(), index);
}
可以看到,get()方法是直接在array中进行获取。
综合看add()和get()方法,add()方法在进行的时候会先上锁,然后拷贝一份数据的副本进行操作,然后将操作后的副本赋值到array中去,至于get()方法是直接获取array中的值,也正是这样,实现了读写分离。但是这也会有一个问题,就是数据的实时不一致性,有可能副本还没赋值到array,而用户通过get()方法获取了旧的array的值。
来看下CopyOnWriteArrayList的迭代器,因为它没有继承AbstractList因此也没有modCount这个变量,先看下怎么得到它的迭代器
public ListIterator listIterator(int index) {
Object[] elements = getArray();
int len = elements.length;
if (index < 0 || index > len)
throw new IndexOutOfBoundsException("Index: "+index);
return new COWIterator(elements, index);
}
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
可以看到是直接通过array和初始化的下标来获取到迭代器。至于迭代数据则是直接获取
@SuppressWarnings("unchecked")
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
因此,这里没有像ArrayList那样,有一个checkForComodification,检查是否迭代数据被修改,因此我又测试了下
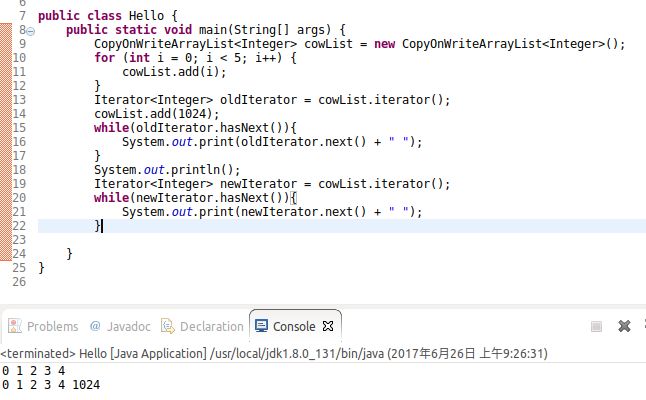
在
ArrayList中,如果获取到迭代器之后对容器内数据进行操作,就会报
ConcurrentModificationException,而在
CopyOnWriteArrayList则不存在这个问题。
但是也有另外一个问题,如图片所展示那样,获取到迭代器之后修改容器内的数据,拦截器并不会有所更新,要获取到修改后的数据,还得重新获取迭代器。
剩下的一些方法就不赘述啦,大同小异。
总结
CopyOnWriteArrayList的核心是在操作数据的时候,通过拷贝原容器数组的副本,在副本上进行操作后,将副本赋值到容器数组,从而实现读写分离。
CopyOnWriteArrayList适用于读多写少的场景,因为写的时候会拷贝数组,很容易产生大量垃圾而触发GC,不利于系统的性能。