序
首先LinkedList也是非线程安全的,与ArrayList不同的是内部实现方式不同, 所以,两者在不同的情况下, 效率也可能不同。本文参考了(http://www.cnblogs.com/xrq730/p/5005347.html)。
LinkedList既然是一种双向链表,必然有一个存储单元,看一下LinkedList的基本存储单元,它是LinkedList中的一个内部类:
private static final class Link {
ET data; // 真正的数据
Link previous; //前一数据的引用地址
Link next; //后一数据的引用地址
Link(ET o, Link p, Link n) {
data = o;
previous = p;
next = n;
}
}
LinkedList构造函数。
public LinkedList(Collection collection) {
this();
addAll(collection);
}
public LinkedList() {
voidLink = new Link(null, null, null); // 创建空链表头。。
voidLink.previous = voidLink;
voidLink.next = voidLink;
}
add数据时
@Override
public boolean add(E object) {
return addLastImpl(object);
}
private boolean addLastImpl(E object) {
Link oldLast = voidLink.previous; // 空表头的前一数据地址,其实就是最后一个数据的地址。
Link newLink = new Link(object, oldLast(前), voidLink(后)); // 新Link的后一个数据地址永远为空表头的地址。
voidLink.previous = newLink; // 重置空表头的前一数据地址为最后添加的数据地址。
oldLast.next = newLink;
size++;
modCount++;
return true;
}
add指定位置数据时
@Override
public void add(int location, E object) {
if (location >= 0 && location <= size) {
Link link = voidLink;
if (location < (size / 2)) { // 如果为数据List的前半部分。
for (int i = 0; i <= location; i++) {
link = link.next; //找到第 i 个数据的下一个数据 。
}
} else {
for (int i = size; i > location; i--) {
link = link.previous;
}
}
Link previous = link.previous;
Link newLink = new Link(object, previous, link);
previous.next = newLink;
link.previous = newLink;
size++;
modCount++;
} else {
throw new IndexOutOfBoundsException();
}
}
引用例子(原文 :http://www.cnblogs.com/xrq730/p/5005347.html)
public static void main(String[] args)
{
1 List list = new LinkedList();
2 list.add("111");
3 list.add("222");
}
假设构造函数里new Link() 的地址为0x0000000,那么它的前后地址都为本身地址。

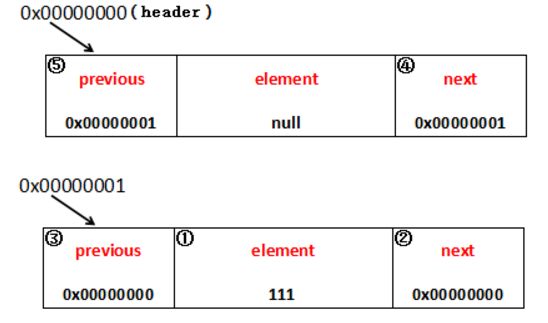

结合 add()方法,相信你可以搞懂它们之间的地址赋值。
其它方法大家可自行分析吧。
小结():
切勿用普通for循环遍历LinkedList
1、顺序插入速度ArrayList会比较快,因为ArrayList是基于数组实现的,数组是事先new好的,只要往指定位置塞一个数据就好了;LinkedList则不同,每次顺序插入的时候LinkedList将new一个对象出来,如果对象比较大,那么new的时间势必会长一点,再加上一些引用赋值的操作,所以顺序插入LinkedList必然慢于ArrayList
2、基于上一点,因为LinkedList里面不仅维护了待插入的元素,还维护了Entry的前置Entry和后继Entry,如果一个LinkedList中的Entry非常多,那么LinkedList将比ArrayList更耗费一些内存
3、数据遍历的速度,看最后一部分,这里就不细讲了,结论是:使用各自遍历效率最高的方式,ArrayList的遍历效率会比LinkedList的遍历效率高一些
4、有些说法认为LinkedList做插入和删除更快,这种说法其实是不准确的:
(1)LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Entry的引用地址
(2)ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址
所以,如果待插入、删除的元素是在数据结构的前半段尤其是非常靠前的位置的时候,LinkedList的效率将大大快过ArrayList,因为ArrayList将批量copy大量的元素;越往后,对于LinkedList来说,因为它是双向链表,所以在第2个元素后面插入一个数据和在倒数第2个元素后面插入一个元素在效率上基本没有差别,但是ArrayList由于要批量copy的元素越来越少,操作速度必然追上乃至超过LinkedList。