摘要: 本文验证分析了PCA算法对于分类任务性能的提升,结果出人意料。
对于深度学习中的图像处理任务来说,很多研究人员都会用到降维处理技术,比如主成分分析(PCA)、稀疏自动编码器(SAE)、随机邻近嵌入(SNE)等,每种降维方法都有各自的侧重点,根据相应的任务需求选择合适的降维算法。在图像处理任务中,使用降维技术的原因主要有以下两个,一方面是通过降维能够降低计算复杂度,另外一方面受限于输入图像尺寸的大小,需要对其进行一些预处理,比如常用的卷积神经网络模型(CNN),输入图像的尺寸一般都不大。降维算法一般是选择最能代表数据集中的特征从而减少特征的数量,那么,降维算法能否对图像分类任务的性能有所提升?毕竟降维算法处理后的特征并不能完全表征图像的全部信息,下面就让我们一窥究竟吧。
降维算法
本文主要以PCA降维算法为例分析,在直接编写代码验证之前,先来谈谈降维算法。维数降低一般有两种主要算法:一种是线性判别分析(LDA),另外一种是主成分分析(PCA)。二者之间的主要区别在于,LDA使用类别信息来查找新特征,以便最大化类别的可分性,而PCA使用每个特征的方差来做到这一点。在这种情况下,LDA可以被认为是有监督算法,而PCA是无监督算法。
谈谈PCA算法
PCA的想法很简单,就是找到一组能概括数据集的低维坐标集。为什么我们需要概况数据呢?举一个例子:假设有一个包括一组汽车属性的数据集,这些属性通过其尺寸、颜色、形状、紧凑度、车身半径、座椅数量、门数以及行李箱尺寸等参数来描述每辆车。但是,许多属性之间是由关联的,所有部分属性是多余的。因此,我们应该根据描述每辆车的能力的高低来删除这些冗余属性,这就是PCA的目标。例如,考虑将车轮数量作为汽车和公共汽车的特征,几乎每个类别中每个样例都有四个轮子,因此,这个特征的差异度很小(一些罕见的公共汽车有六个轮子),所以这个特征无法区分公共汽车和汽车,但两种车辆实际上是非常不同。现在,考虑将高度作为特征,汽车和公共汽车具有不同的属性值,并且从最低的汽车到最高的公共汽车二者的高度差异具有很大的范围。显然,车辆的高度可以作为分离它们的良好特征。PCA算法不考虑类别的信息,它只是查看每个特征的方差,因为可以合理地假设,呈现高方差的特征更有可能在类别之间进行良好的区分。
通常,人们会有一个误解,认为PCA算法会从数据集中选择某些特征并丢弃其他特征。实际上,该算法是基于旧的属性来组合构造新的属性集。从数学上讲,PCA执行线性变换,将原始特征集变换到由主成分组成的新空间。这些新特征对我们来说并没有任何的实际意义,只具有代数意义,因此不要认为PCA能够找到之前从未想过存在的新特征。许多人仍然相信机器学习算法是神奇的,他们直接将数以千计的输入投入到算法中,并希望机器学习算法能够为其业务找到所有的见解和解决方案,在这里声明一点,不要被一些夸张的报道所欺骗,机器学习目前的能力有限,数据科学家的工作是通过使用机器学习算法作为一组工具而并不是魔术棒,智能通过对数据进行良好的探索性分析来找到对业务的见解。
主成分空间
在新的特征空间中,我们正在寻找一些在类别中存在很大差异的属性。正如之前举得例子所示,一些呈现出低方差的属性作用不大,无法很好的区分样例。另一方面,PCA寻找的属性可以尽可能多地显示类别,以构建出主成分空间。该算法使用方差矩阵、协方差矩阵、特征向量和特征值对的概念来实现PCA算法,从而提供一组特征向量及其各自的特征值。
那么,我们应该如何处理特征值和特征向量呢?答案非常简单,特征向量表示主成分空间的新坐标系,特征值带有每个特征向量具有的方差信息。因此,为了减小数据集的维数,将选择具有方差值大的那些特征向量,并丢弃具有方差值小的那些特征向量,具体实现步骤可以网上找下相关资源。下面将通过具体的例子和代码展示PCA算法是如何工作的。
实验代码
本部分内容是比较有趣的部分,现在让我们看看PCA算法是否真的改善了分类任务的结果。
为了验证它,采取的策略是在数据集上应用神经网络并查看其初始结果。之后,我将在分类之前执行PCA降维,之后在降维后得到的数据集上应用相同的神经网络,最后比较两个结果。
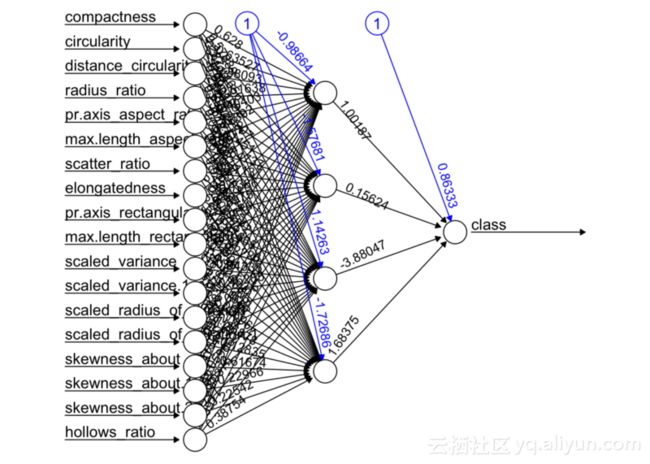
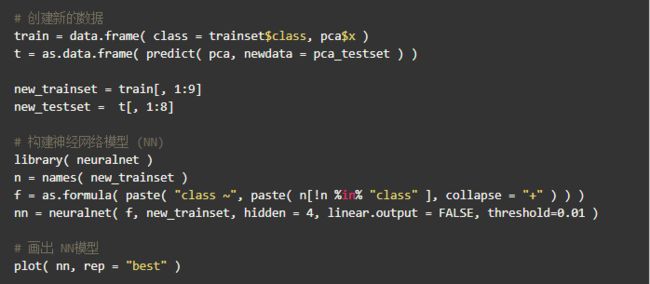
该数据集源自名为“Statlog数据集”的UCI机器学习库,该数据集存储了四个车辆轮廓的一些度量,用于分类。它由946个示例和18个度量(属性)所有数值组成,可以在此链接中查看更多详细信息。神经网络结构是一个多层感知机,其具有四个隐藏节点和一个输出节点,所有的激活函数选择sigmoid函数,PCA的处理是通过R数据包完成。
准备数据集
首先,准备二进制分类的数据集,仅从两个类别中选择示例以构成二进制分类。这些例子来自“bus(公共汽车)”和“saab(萨博汽车)”类。类别“saab”用类别0替换,类别“bus”用类别1替换。下一步是将数据集划分为训练数据集和测试数据集,其比例分别为占总类示例的60%和40%。
在数据集准备好之后,一次性使用所有特征构建神经网络模型,然后对其应用测试数据集,看其性能。
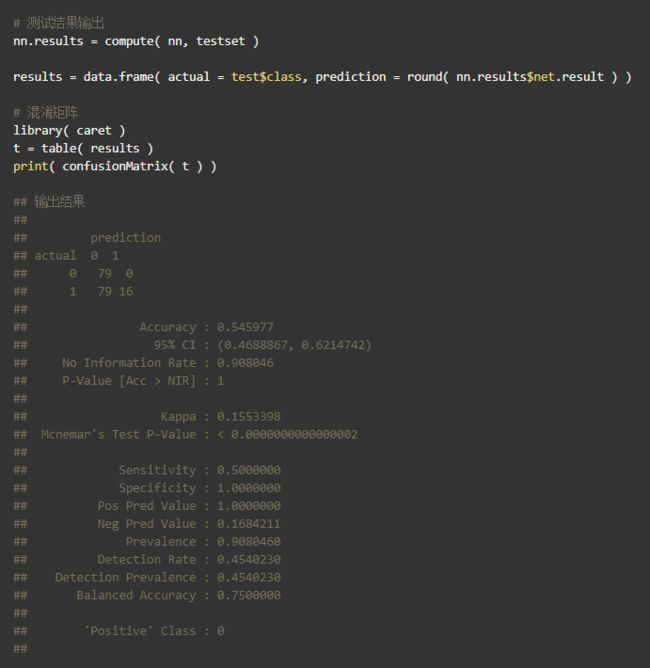
无PCA处理的结果
从上面的结果中首先可以看到,混淆矩阵(Confusion Matrix)表示有多少例子被分类,主对角线显示正确分类的示例,次对角线显示错误分类。这个结果中,分类器表示自己十分困惑,因为几乎所有来自“saab”类别的例子都被正确分类,但它也将大多数“bus”类别的样例分类为“saab”类别。此外,可以看出其精度值(Accuracy)约为50%,这对于分类任务来说是一个非常糟糕的结果,分类器本身就有一半一半的概率将新样例分类为“saab”或“bus”类别。因此,由神经网络构成的该分类器性能不好。
PCA处理后的结果
现在,对数据集进行主成分分析PCA处理,得到特征值和特征向量。实际上,你会看到R数据包中的PCA函数提已经供了一组按降序排序的特征值,这意味着第一个分量是方差最大的一个,第二个分量是方差第二大的特征向量,以此类推。下面的代码展示了如何选择特征值的特征向量。



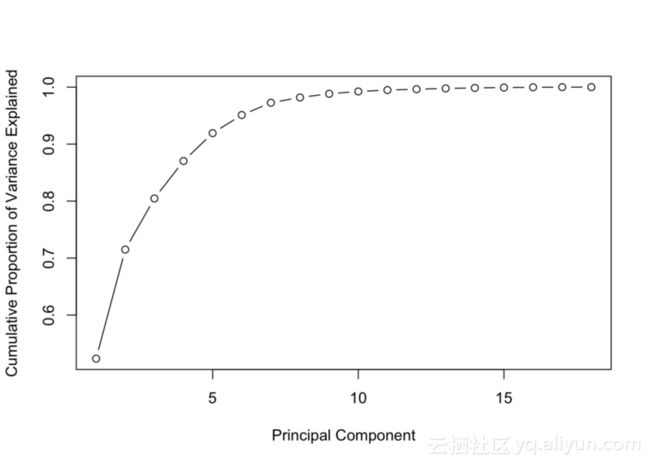
来自R数据包中的“prcomp”函数执行PCA,该函数返回所需的所有特征值和特征向量。上面的第一张图显示每个特征的方差百分比。从图中可以看到,第一成分具有最高的方差,值约为50%,而第8个成分的方差约为0%。所以,这告诉我们。应该取其前八个组件作为主要成分。第二张图展示了方差的另外一个视角——方差的累积和。从图中可以看到,前八个特征值对应的方差累积和占所有方差的大约98%。实际上,这是一个非常好的数字,这意味着只有2%的信息丢失了,最大的好处是,从具有18维特征的空间转换到另外一个只有8维特征的空间,仅丢失了2%的信息,这就是降维的力量。
当我们知道了构成新空间的特征数量时,就可以创建出新的数据集,然后再次对其构建神经网络模型,并用新的测试集测试其性能。
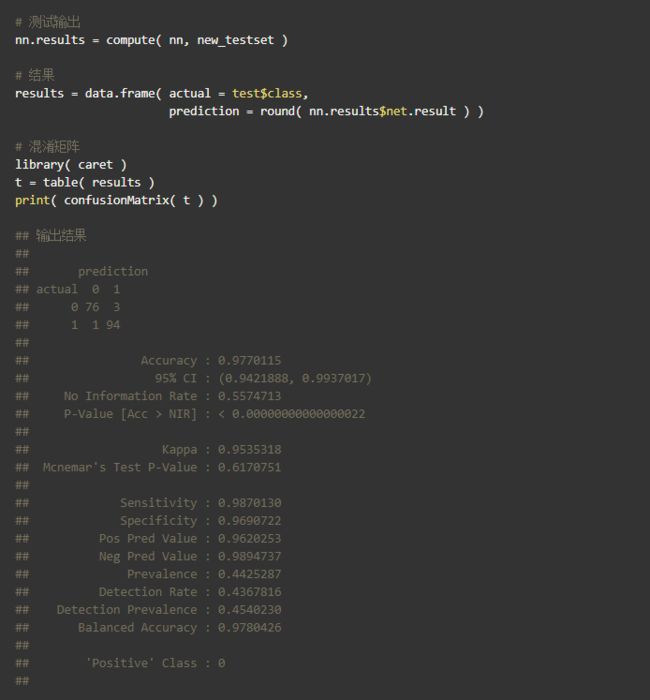
从上面可以看到,得到了非常好的结果。在这次实验中,混淆矩阵显示出神经网络在两个类别中都具有较少的错误分类次数,并且,出主对角线的值和精度值都在95%左右,这表明新的分类器有95%的机会正确分类一个新的样例,这个准确率对于分类问题而言,是一个非常不错的结果。
结论
降维在机器学习中起着非常重要的作用,特别是当数据集具有数千种特征时。主成分分析是最优的降维算法之一,在实际项目中很容易被理解和使用。除了使得特征处理变得更加容易之外,这项技术还能够改善分类器的结果,从文中的实验对比来看,提升效果还是很大的。
最后,对于PCA降维算法能否提升分类任务的性能问题而言,其答案是肯定的,PCA降维算法有助于改善分类器的性能。
本文作者:【方向】
阅读原文
本文为云栖社区原创内容,未经允许不得转载。