前言
上述我们简单讲解了几个小问题,这节我们再来看看如标题EF Core中多次Include导致出现性能的问题,废话少说,直接开门见山。
EntityFramework Core 3多次Include查询问题
不要嫌弃我啰嗦,我们凡事从头开始讲解起,首先依然给出我们上一节的示例类:
public class EFCoreDbContext : DbContext { public EFCoreDbContext() { } public DbSetBlogs { get; set; } public DbSet Posts { get; set; } protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder) => optionsBuilder.UseSqlServer(@"Server=.;Database=EFTest;Trusted_Connection=True;"); } public class Blog { public int Id { get; set; } public string Name { get; set; } public List Posts { get; set; } } public class Post { public int Id { get; set; } public int BlogId { get; set; } public string Title { get; set; } public string Content { get; set; } public Blog Blog { get; set; } }
接下来我们在控制台进行如下查询:
var context = new EFCoreDbContext(); var blog = context.Blogs.FirstOrDefault(d => d.Id == 1);

如上图所示,生成的SQL语句一点毛病都么有,对吧,接下来我们来查询导航属性Posts,如下:
var context = new EFCoreDbContext(); var blog = context.Blogs.AsNoTracking() .Include(d => d.Posts).FirstOrDefault(d => d.Id == 1);

咦,不应该是INNER JOIN吗,但最终生成的SQL语句我们可以看到居然是LEFT JOIN,关键是我们对Post类中的BlogId并未设置为可空,对吧,是不是很有意思。同时通过ORDER BY对两个表的主键都进行了排序。这就是问题的引发点,接下来我们再引入两个类:
////// 博客标签 /// public class Tag { public int Id { get; set; } /// /// 标签名称 /// public string Name { get; set; } public int BlogId { get; set; } public Blog Blog { get; set; } } /// /// 博客分类 /// public class Category { /// /// /// public int Id { get; set; } /// /// 分类名称 /// public string Name { get; set; } /// /// /// public int BlogId { get; set; } /// /// /// public Blog Blog { get; set; } }
上述我们声明了分类和标签,我们知道博客有分类和标签,所以博客类中有对分类和标签的导航属性(这里我们先不关心关系到底是一对一还是一对多等关系),然后修改博客类,如下:
public class Blog { public int Id { get; set; } public string Name { get; set; } public ListPosts { get; set; } public List Tags { get; set; } public List Categories { get; set; } }
接下来我们再来进行如下查询:
var context = new EFCoreDbContext(); var blogs = context.Blogs.AsNoTracking().Include(d => d.Posts) .Include(d => d.Tags) .Include(d => d.Categories).FirstOrDefault(d => d.Id == 1);

SELECT [t].[Id], [t].[Name], [p].[Id], [p].[BlogId], [p].[Content], [p].[Title], [t0].[Id], [t0].[BlogId], [t0].[Name], [c].[Id], [c].[BlogId], [c].[Name]
FROM (
SELECT TOP(1) [b].[Id], [b].[Name]
FROM [Blogs] AS [b]
WHERE [b].[Id] = 1
) AS [t]
LEFT JOIN [Posts] AS [p] ON [t].[Id] = [p].[BlogId]
LEFT JOIN [Tags] AS [t0] ON [t].[Id] = [t0].[BlogId]
LEFT JOIN [Categories] AS [c] ON [t].[Id] = [c].[BlogId]
ORDER BY [t].[Id], [p].[Id], [t0].[Id], [c].[Id]
此时和变更追踪没有半毛钱关系,我们看看最终生成的SQL语句,是不是很惊讶,假设单个类中对应多个导航属性,最终生成的SQL语句就是继续LEFT JOIN和ORDER BY,可想其性能将是多么的低下。那么我们应该如何解决这样的问题呢?既然是和Include有关系,每增加一个导航属性即增加一个Include将会增加一个LEFT JOIN和ORDER BY,那么我们何不分开单独查询呢,说完就开干。
var context = new EFCoreDbContext(); var blog = context.Blogs.AsNoTracking().FirstOrDefault(d => d.Id == 1);
此时我们进行如上查询显然不可取,因为直接就到数据库进行SQL查询了,我们需要返回IQueryable才行,同时根据主键查询只能返回一条,所以我们改造成如下查询:
var context = new EFCoreDbContext(); var blog = context.Blogs.Where(d => d.Id == 1).Take(1);
因为接下来还需要从上下文中加载导航属性,所以这里我们需要去掉AsNoTracking,通过上下文加载指定实体导航属性,我们可通过Load方法来加载,如下:
var context = new EFCoreDbContext(); var blog = context.Blogs.Where(d => d.Id == 1).Take(1); blog.Include(p => p.Posts).SelectMany(d => d.Posts).Load(); blog.Include(t => t.Tags).SelectMany(d => d.Tags).Load(); blog.Include(c => c.Categories).SelectMany(d => d.Categories).Load();
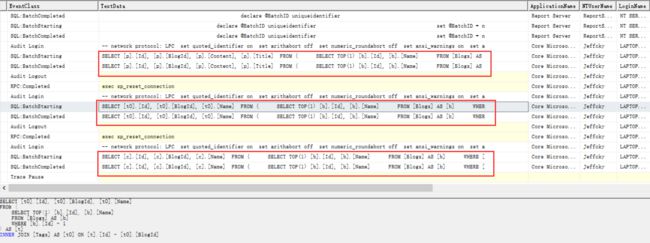
SELECT [p].[Id], [p].[BlogId], [p].[Content], [p].[Title] FROM ( SELECT TOP(1) [b].[Id], [b].[Name] FROM [Blogs] AS [b] WHERE [b].[Id] = 1 ) AS [t] INNER JOIN [Posts] AS [p] ON [t].[Id] = [p].[BlogId] SELECT [t0].[Id], [t0].[BlogId], [t0].[Name] FROM ( SELECT TOP(1) [b].[Id], [b].[Name] FROM [Blogs] AS [b] WHERE [b].[Id] = 1 ) AS [t] INNER JOIN [Tags] AS [t0] ON [t].[Id] = [t0].[BlogId] SELECT [c].[Id], [c].[BlogId], [c].[Name] FROM ( SELECT TOP(1) [b].[Id], [b].[Name] FROM [Blogs] AS [b] WHERE [b].[Id] = 1 ) AS [t] INNER JOIN [Categories] AS [c] ON [t].[Id] = [c].[BlogId]
通过上述生成的SQL语句,我们知道这才是我们想要的结果,上述代码看起来有点不是那么好看,似乎没有更加优美的写法了,当然这里我只是在控制台中进行演示,为了吞吐,将上述修改为异步查询则是最佳可行方式。 比生成一大堆LEFT JOIN和ORDER BY性能好太多太多。
总结
注意:上述博主采用的是稳定版本3.0.1,其他版本未经测试哦。其实对于查询而言,还是建议采用Dapper或者走底层connection写原生SQL才是最佳,对于单表,用EF Core无可厚非,对于复杂查询还是建议不要用EF Core,生成的SQL很不可控,为了图方便,结果换来的将是CPU飙到飞起。好了,本节我们就到这里,感谢您的阅读,我们下节见。