鍐欏湪鏈�鍓�
Python鍦ㄦ暟鎹垎鏋愰鍩熸湁涓変釜蹇呴』闇�瑕佺啛鎮夌殑搴擄紝鍒嗗埆鏄�pandas,numpy鍜�matplotlib锛屽鏋滄帓涓紭鍏堢骇鐨勮瘽锛屾垜鎺ㄨ崘鍏堝pandas銆�
numpy涓昏鐢ㄤ簬鏁扮粍鍜岀煩闃电殑杩愮畻锛屼竴鑸湪绠楁硶棰嗗煙浼氬簲鐢ㄦ瘮杈冨銆�matplotlib鐢ㄤ簬浣滃浘鐨勮瘽鍏跺疄鍙浛浠g殑搴撲細姣旇緝澶氾紝璀鏈夊皝瑁呯殑鏇撮珮绾х殑seaborn锛岃皟鐢ㄨ捣鏉ヤ細鏇存柟渚匡紝涔熸湁浜や簰鎬ф洿寮虹殑pyecharts,椋庢牸浼氭洿璁ㄥ枩銆�
浣嗗浜�pandas锛屼技涔庡畬鍏ㄧ粫涓嶅紑锛屽綋鐒惰繖涓変釜搴撻兘鏄潪甯镐紭绉�鐨勫簱锛屽鏋滀綘宸茬粡鍏ュ潙鏁版嵁鍒嗘瀽锛屽缓璁叏瀛︷煂濄��
***
鍩烘湰鐢ㄦ硶
璇诲彇鏁版嵁
SQL
sql璇诲彇鏁版嵁鍏跺疄娌″暐鍙鐨勶紝涓�鍙ョ畝鍗曠殑select * from table_name灏監K浜嗐��
Pandas
pandas鏀寔鐨勬暟鎹簮寰堝锛屽寘鎷琧sv锛宔xcel锛屼互鍙婅鍙栨暟鎹簱锛屽綋鐒惰鍙栨暟鎹簱鐨勮瘽闇�瑕侀厤鍚堝叾浠栧簱锛屽寘鎷琽racle锛宮ysql锛寁ertica绛夌瓑閮芥槸鏀寔鐨勩��
甯歌鐨勫涓嬶細
pandas.read_csv()锛氱敤浜庤鍙朿sv鏂囦欢锛�pandas.read_excel()锛氱敤浜庤鍙朎xcel鏂囦欢锛�pandas.read_json()锛氱敤浜庤鍙杍son鏂囦欢锛�pandas.read_sql()锛氱敤浜庤鍙栨暟鎹簱锛屼紶鍏ql璇彞锛岄渶瑕侀厤鍚堝叾浠栧簱杩炴帴鏁版嵁搴撱��
鐢变簬鎴戞湰鍦版病鏈夋暟鎹簱璧勬簮锛屾垜杩欒竟灏卞凡csv鏂囦欢涓轰緥锛�
import pandas as pd
data = pd.read_csv('directory.csv', encoding='utf-8')
# data.head()榛樿鏄剧ず鍓�5鏉¤褰曪紝绫讳技杩樻湁data.tail()
data.head()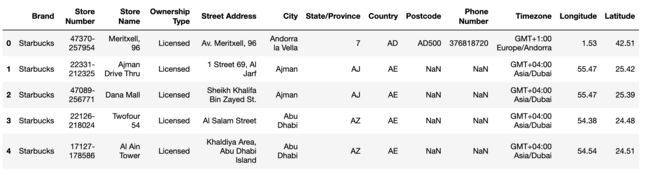
绛涢�夊垪
SQL
select city, country
from table_namePandas
# 绛涢�変竴鍒�
# 杩欐牱杩斿洖鐨勬槸series
data['City'].head()
# 杩欐牱杩斿洖鐨勬槸dataframe锛屾敞鎰忓樊鍒�
data[['City']].head()
# 绛涢�夊鍒�
data[['City','Country']].head()绛涢�夎
SQL
sql鏈韩骞朵笉鏀寔绛涢�夌壒瀹氳锛屼笉杩囧彲浠ラ�氳繃鍑芥暟鎺掑簭鐢熸垚铏氭嫙鍒楁潵绛涢�夈��
-- 绛涢�夊墠100琛�
select *
from table_name
limit 100Pandas
pandas鏀寔鐨勬柟寮忓氨姣旇緝澶氫簡锛屽鏋滀綘浜嗚Вpython鐨�鍒囩墖鎿嶄綔锛屼互涓嬪簲璇ヤ細姣旇緝濂界悊瑙c��
data[:3]锛氱瓫閫夊墠3琛岋紱

data[1:10:2]锛氱瓫閫�1鍒�10琛屼腑鐨勫鏁拌锛屾渶鍚庝竴涓暟瀛�2琛ㄧず姣忛殧2琛屽彇鏁帮紱
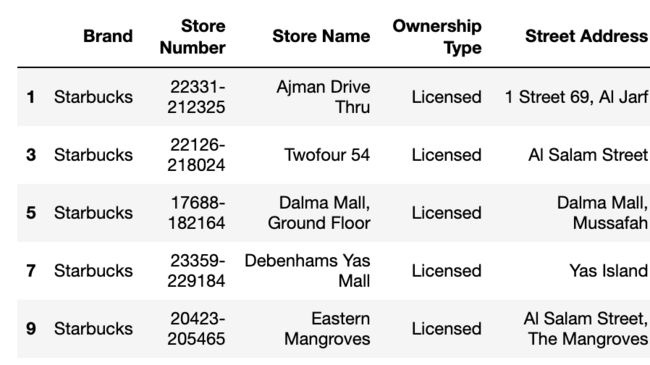
琛屽垪鍚屾椂绛涢��
pandas涓昏鏈�data.iloc鍜�data.loc鏉ユ敮鎸佽鍒楃瓫閫夛紝铏界劧杩樻湁data.ix,浣嗗湪鐩墠鏈�鏂扮殑pandas宸茬粡灏嗗叾寮冪敤浜嗐��
鍏跺疄鎴戜竴寮�濮嬪杩欎袱涓柟娉曞緢瀹规槗娣锋穯锛屽叾瀹炲悗闈㈠彂鐜板緢濂藉尯鍒嗭紝濡傛灉闇�瑕佺敤鍒楀悕鏉ョ瓫閫夛紝璇风敤loc锛屽鏋滀娇鐢ㄥ垪绱㈠紩锛岃鐢�iloc銆�
# 鏍规嵁鍒楀悕锛岃鐢╨oc
# 绛涢��1鍒�10琛岀殑濂囨暟琛岋紝City鍜孋ountry鍒�
data.loc[1:10:2,['City','Country']]
# 绛涢�夌2鍜岀4琛岋紝City鍜孋ountry鍒�
data.loc[[2,4],['City','Country']]
# 鏍规嵁鍒楃储寮曪紝璇风敤iloc
# 绛涢��1鍒�10琛岀殑濂囨暟琛岋紝2鍒�5鍒�
data.iloc[1:10:2,2:5]
# 绛涢��1鍒�10琛岀殑濂囨暟琛岋紝2鍒�10鍒椾腑姣忛殧3鍒楀彇涓�鍒�
data.iloc[1:10:2,2:10:3]
# 绛涢�夌2鍜岀4琛岋紝绗�3鍜岀5鍒�
data.iloc[[2,4],[3,5]]鏍规嵁鏉′欢绛涢��
SQL
select city, country
from table_name
where city = 'shanghai'Pandas
鍦ㄧ湅绀轰緥涔嬪墠闇�瑕佹彁閱掍笅锛屽湪Pandas涓苟涓嶆敮鎸�and 鍜�or锛岀浉搴旂殑鏄�&鍜�|锛岃�屼笖鐢变簬&鍜�|鍦ㄨ繍绠椾紭鍏堢骇鏄紭浜�== ,>绛夎繍绠楃绛夛紝鍥犳鍦ㄥ鏉′欢绛涢�夐渶瑕佸姞涓婃嫭鍙凤紝绫讳技(a == 1) & (b > 2)銆�
# 绛涢�塀rand涓篠tarbucks
data.loc[data['Brand'] == 'Starbucks']
# 绛涢�塁ity涓簊hanghai鎴栬�呬负beijing
data.loc[(data['City'] == 'shanghai') | (data['City'] == 'beijing')]
# 绛涢�塀rand涓篠tarbucks鑰屼笖City涓簊hanghai
data.loc[(data['Brand'] == 'Starbucks') & (data['City'] == 'shanghai')]
# 浣跨敤.isin
data.loc[data['City'].isin(['shanghai', 'Ajman', 'wuhan'])]
# 绛涢�塗imezone鍒椾腑鍖呭惈Asia
data.loc[data['Timezone'].str.contains('Asia')]鍒嗙粍鑱氬悎
SQL
select column_A, sum(column_B)
from table_name
group by column_APandas
鍩烘湰鐢ㄦ硶锛�
瀵笵ataFrame杩涜goupby杩愮畻鍚庯紝杩斿洖鐨勬槸涓�涓猤roupby瀵硅薄锛屾垜浠彲浠ラ�氳繃.reset_index()灏嗗叾杞负DataFrame銆�
# 浠wnership Type鍒楀垎缁勶紝瀵笲rand鍒楄繘琛岃鏁�
# .reset_index()灏唃roupby瀵硅薄杞垚dataframe
data.groupby(['Ownership Type'])['Brand','Country'].count().reset_index()
# 浠ountry鍜孋ity鍒楄繘琛屽垎缁勶紝瀵筁ongitude杩涜姹傚钩鍧�
data.groupby(['Country', 'City'])['Longitude'].mean().reset_index()楂橀樁鐢ㄦ硶锛�
鎴戜滑鍙互鍚屾椂瀵逛簬涓嶅悓鍒楅噰鍙栦笉鍚岀殑鑱氬悎杩愮畻锛岃濡傚A鍒椾娇鐢�sum()锛屽B鍒椾娇鐢�mean()锛屽湪SQL涓叾瀹炲緢濂藉疄鐜扮殑鍔熻兘锛屽湪Pandas鎴戜滑闇�瑕佸�熷姪.agg()鏉ュ疄鐜� 銆�
# 瀵逛笉鍚屽垪杩涜涓嶅悓瀵硅繍绠�
# 瀵筁ongitude杩涜MAX鎿嶄綔锛屽City鍒楄繘琛孋ount
data.groupby(['Ownership Type']).agg({'Longitude':'max', 'City':'count'}).reset_index()
# 瀵圭粺涓�鍒楄繘琛屼笉鍚屽鎿嶄綔
data.groupby(['Ownership Type'])['Longitude'].agg(['max', 'count']).reset_index()杩炴帴
SQL
select *
from table_A a
left join table_B b
on a.id = b.idPandas
鍦≒andas涓垜浠彲浠ヤ娇鐢�pandas.merge()鏉ュ畬鎴愯繛鎺ュ鎿嶄綔銆�
python pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True)
鍚勫弬鏁拌В閲婂涓嬶細
- left锛氫竴涓狣ataFrame瀵硅薄锛�
- right锛氬彟涓�涓狣ataFrame瀵硅薄锛�
- how锛氳繛鎺ユ柟寮忥紝榛樿涓篿nner锛堝唴杩炴帴锛夛紱
- on锛氳繛鎺ラ敭锛屽繀椤诲湪left鍜宺ight涓や釜DataFrame涓瓨鍦紝鍚﹀垯浣跨敤left_on鍜宺ight_on;
- left_on锛歭eft涓殑杩炴帴閿紱
- right_on锛歳ight涓殑杩炴帴閿紱
- left_index/right_index锛氶粯璁や负False锛屽鏋滀负True鍒欎娇鐢ㄧ储寮曚綔涓鸿繛鎺ョ殑閿��
# 鐢熸垚涓や釜DataFrame
left = pd.DataFrame({
'id':[1,2,3,4,5],
'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame(
{'id':[1,2,3,4,5],
'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'subject_id':['sub2','sub4','sub3','sub6','sub5']})
df = pd.merge(left=left, right=right, on='subject_id', how='left')
print(df)
'''
id_x Name_x subject_id id_y Name_y
0 1 Alex sub1 NaN NaN
1 2 Amy sub2 1.0 Billy
2 3 Allen sub4 2.0 Brian
3 4 Alice sub6 4.0 Bryce
4 5 Ayoung sub5 5.0 Betty
'''楂橀樁鐢ㄦ硶
姝e垯琛ㄨ揪寮�
SQL
Oracle鐩墠鏄敮鎸佹鍒欒〃杈惧紡鐨勶紝鍏朵粬鐨勬暟鎹簱鏆傛椂涓嶅ぇ浜嗚В锛屽鏋滄兂浜嗚В鐢ㄦ硶鐨勫彲浠ュ弬鑰�杩欑瘒鏁欑▼锛岃繖杈瑰氨涓嶄妇渚嬩簡銆�
Pandas
# 鐢熸垚涓�涓狣ataFrame
df = pd.DataFrame({
'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'Location':['婀栧寳鐪佹姹夊競','骞夸笢鐪佹繁鍦冲競','骞夸笢鐪佸箍宸炲競','婀栧崡鐪侀暱娌欏競','婀栧寳鐪侀剛宸炲競']})
# 杩斿洖涓�鍒楃殑鏃跺�檈xpand涓篢rue杩斿洖鐨勬槸Dataframe
print(df['Location'].str.extract('(.*?)鐪�', expand=True))
'''
0
0 婀栧寳
1 骞夸笢
2 骞夸笢
3 婀栧崡
4 婀栧寳
'''
# 杩斿洖涓�鍒楃殑鏃跺�檈xpand涓篢rue杩斿洖鐨勬槸Dataframe
print(df['Location'].str.extract('(.*?)鐪�(.*?)甯�', expand=True
).rename(columns = {0: 'Province', 1: 'City'}))
'''
Province City
0 婀栧寳 姝︽眽
1 骞夸笢 娣卞湷
2 骞夸笢 骞垮窞
3 婀栧崡 闀挎矙
4 婀栧寳 閯傚窞
'''
# 涓庡師DataFrame鎷兼帴锛宎xis=1琛ㄧず涓烘í鍚戞嫾鎺�
print(pd.concat([df, df['Location'].str.extract('(.*?)鐪�(.*?)甯�', expand=True
).rename(columns = {0: 'Province', 1: 'City'})], axis=1))
'''
Name Location Province City
0 Alex 婀栧寳鐪佹姹夊競 婀栧寳 姝︽眽
1 Amy 骞夸笢鐪佹繁鍦冲競 骞夸笢 娣卞湷
2 Allen 骞夸笢鐪佸箍宸炲競 骞夸笢 骞垮窞
3 Alice 婀栧崡鐪侀暱娌欏競 婀栧崡 闀挎矙
4 Ayoung 婀栧寳鐪侀剛宸炲競 婀栧寳 閯傚窞
'''褰撶劧瀵逛簬pandas闄や簡姝e垯涔嬪锛屽叾瀹炲湪.str涓繕鍐呯疆浜嗗緢澶氬瓧绗︿覆鐨勬柟娉曪紝濡傚垏鍓�(split)锛屾浛鎹�(replace)绛夌瓑銆�
鑷畾涔夊嚱鏁�
Pandas涓唴缃緢澶氬父鐢ㄧ殑鏂规硶锛岃濡傛眰鍜岋紝鏈�澶у�肩瓑绛夛紝浣嗗緢澶氭椂鍊欒繕鏄弧瓒充笉浜嗛渶姹傦紝鎴戜滑闇�瑕佸彇璋冪敤鑷繁鐨勬柟娉曪紝Pandas涓彲浠ヤ娇鐢�map()鍜�apply()鏉ヨ皟鐢ㄨ嚜瀹氫箟鐨勬柟娉曪紝闇�瑕佹敞鎰忎笅map()鍜�apply()鐨勫尯鍒細
map()锛氭槸pandas.Series()鐨勫唴缃柟娉曪紝涔熷氨鏄鍙兘鐢ㄤ簬鍗曚竴鍒楋紝杩斿洖鐨勬槸鏁版嵁鏄�Series()鏍煎紡鐨勶紱apply()锛氬彲浠ョ敤浜庡崟鍒楁垨鑰呭鍒楋紝鏄鏁翠釜DataFrame鐨勫厓绱犺繘琛岃繍绠楋紝杩斿洖涓�涓狣ataFrame銆�
import numpy as np
# 闅忔満鐢熸垚涓�涓狣ataFrame
df = pd.DataFrame(np.random.randn(4, 3), columns=['A', 'B', 'C'])
print(df)
'''
A B C
0 -0.487982 0.898259 0.120316
1 -3.411103 0.139425 -1.969046
2 1.192626 -1.053607 0.596296
3 -0.981491 0.281875 -0.910885
'''
# map()鏄拡瀵筽andas.Series()鐨勫唴缃柟娉�
# apply()鍙互鐢ㄤ簬DataFrame鍜孲eries
# 鍙栫粷瀵瑰��,杩斿洖鐨勬槸Series
print(df['A'].map(lambda x: abs(x)))
'''
0 0.487982
1 3.411103
2 1.192626
3 0.981491
Name: A, dtype: float64
'''
# 瀵规暣涓狣ataFrame杩涜鍙栫粷瀵瑰��
print(df[['A']].apply(lambda x: abs(x)))
'''
A
0 0.487982
1 3.411103
2 1.192626
3 0.981491
'''
# 鑷畾涔夊嚱鏁�
def _abs(x):
return abs(x)
print(df.apply(_abs))
'''
A B C
0 0.487982 0.898259 0.120316
1 3.411103 0.139425 1.969046
2 1.192626 1.053607 0.596296
3 0.981491 0.281875 0.910885
'''DataFrame鎷兼帴
鍓嶆枃鎻愬埌浜�merge() ,鍏跺疄涔熺畻浣滄嫾鎺ョ殑涓�绉嶏紝濡傛灉灏�merge()绫绘瘮涓�join鎿嶄綔锛屾帴涓嬫潵璁茬殑鎷兼帴灏嗙被浼间簬SQL涓殑union all鎿嶄綔銆�
df1 = pd.DataFrame(np.random.randn(2, 3), columns=['A', 'B', 'C'])
df2 = pd.DataFrame(np.random.randn(2, 3), columns=['B', 'C', 'D'])
print(df1)
'''
A B C
0 1.371182 -0.201213 0.078707
1 2.607673 0.480420 -0.736990
'''
print(df2)
'''
B C D
0 0.472007 0.932799 -1.236443
1 2.207940 0.696062 0.237979
'''
# 榛樿绾靛悜杩炴帴锛屽嵆union鎿嶄綔
# ignore_index涓篢rue涓洪噸鏂扮敓鎴愮储寮�
print(pd.concat([df1, df2], axis=0, ignore_index=True, sort=False))
'''
A B C D
0 1.371182 -0.201213 0.078707 NaN
1 2.607673 0.480420 -0.736990 NaN
2 NaN 0.472007 0.932799 -1.236443
3 NaN 2.207940 0.696062 0.237979
'''
# axis=1涓烘í鍚戣繛鎺�
print(pd.concat([df1, df2], axis=1))
'''
A B C B C D
0 1.371182 -0.201213 0.078707 0.472007 0.932799 -1.236443
1 2.607673 0.480420 -0.736990 2.207940 0.696062 0.237979
'''
# append涓嶄細閲嶆柊鐢熸垚DataFrame锛屽湪鍘烡F涓婃坊鍔�
print(df1.append(df2,sort=False))
'''
A B C D
0 1.371182 -0.201213 0.078707 NaN
1 2.607673 0.480420 -0.736990 NaN
0 NaN 0.472007 0.932799 -1.236443
1 NaN 2.207940 0.696062 0.237979
'''鍐欏湪鏈�鍚�
鏈潵鎯崇潃Pandas鐢ㄤ簡杩欎箞涔呬簡锛屽啓涓暀绋嬪簲璇ヤ笉楹荤儲锛岀粨鏋滆�楄垂浜嗕袱涓笅鍗堜篃鎵嶅啓浜嗙偣鐨瘺銆傚叾瀹炲鏋滆鍐欑殑璇︾粏鐐癸紝姣忎釜鐐归兘鑳藉啓绡囨枃绔狅紝绡囧箙鏈夐檺锛屽彧鑳界偣鍒板嵆姝紝鍚庨潰濡傛灉鎯冲埌鍐嶅仛琛ュ厖鍚с��
Talk is cheap, show me the code.