1、背景
数据存储在磁盘上,减少IO次数是提高查询效率的重要选择。
一方面,基于预读取原理,将连续数据放在一小块存储上(page),一次性读取。
另一方面,通过一个高度可控的多路搜索树(B+树)建立索引,减少定位数据过程中,查找和读取数据块的次数。
2、索引与B+数
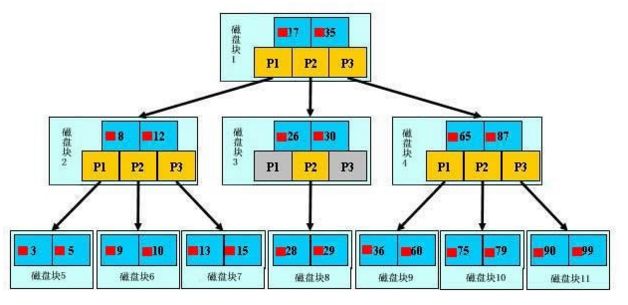
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
B+查找过程:
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
B+树索引的性质:
1.通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
总结:使用B+树做索引结构,数据节点放在叶子节点。树的高度可控,且可以在同一数据块中读取连续的数据项。
3、索引优化思路
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
注:聚簇索引与非聚簇索引
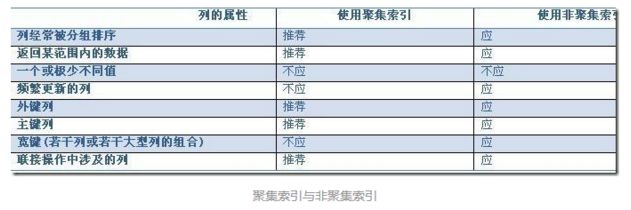
InnoDB的聚族索引实际上在同一个结构中保存了B-Tree索引和数据行。当表有聚族索引时,它的数据行存放在索引的叶子页中。
非聚簇索引,数据行不放在索引中。
这样,聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的索引顺序与数据物理排列顺序无关。
聚簇索引的优点就是查询次数更少,但插入数据时候,需要根据进行数据项移动,降低插入效率,而非聚簇索引不需要。
4、sql优化
(1)、禁止使用SELECT *
(2)、禁止使用COUNT (*),用count索引列代替,如count (id)
(3)、where(查询、更新)和order by涉及的列用到索引
(4)、NOT、<>、!=
会导致不使用索引
select * from employee where salary!=3000
替代为
select * from employee where salary<3000 or salary>3000;
(5)、OR用UNION代替
OR不会使用索引导致全表扫描
select id from t where num=10 or num=20
代替为
select id from t where num=10 union all select id from t where num=20
(6)、UNION和UNION ALL
UNION会做去重操作,如果不需要去重使用UNION ALL
(7)、IS NULL和IS NOT NULL
where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。避免表中列的默认值为NULL。
select id from t where num=0
(8)、IN和NOT IN 用 EXISTS 和NOT EXISTS代替
select num from a where num in(select num from b) 会首先转化为联合查询
替代为
select num from a where exists(select 1 from b where num=a.num)
另外,IN中数据不能太多,不超过500条。
(9)、<和> 可以替换成<=和>=
如果A=2记录很多,那么执行A>2与A>=3的效果可能有很大的区别,因为A>2时会先找出为2的记录索引再进行比较,而A>=3时则直接找到=3的记录索引。
(10)、in、<、>可以考虑用between
(11)、LIKE "%XX%" 改用 LIKE “XX%”
LIKE ‘%5400%’ 这种查询不会引用索引,而LIKE ‘X5400%’则会引用范围索引。
(12)、WHERE后面的条件顺序影响
如果WHERE后面的条件没有索引及数据库没有对表进行统计分析的情况下,数据库会按表出现的顺序进行链接。
Select * from test where b=1 and a = '稀有'
Select * from test where a = '稀有' and b=1
如果a = '稀有'占全表很少数,b=1 占全表大多数。则第二句sql性能更高。
(13)、避免在sql中使用计算、转化等
SELECT a FROM EMP WHERE EMPNO = ‘123'
实际上,经过ORACLE类型转换, 语句转化为:
SELECT a FROM EMP WHERE EMPNO = TO_NUMBER(‘123')
(14)GROUP BY优化
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉。
低效: SELECT JOB , AVG(SAL) FROM EMP GROUP by JOB HAVING JOB = ‘PRESIDENT' OR JOB = ‘MANAGER'
高效: SELECT JOB , AVG(SAL) FROM EMP WHERE JOB = ‘PRESIDENT' OR JOB = ‘MANAGER' GROUP by JOB
(15)、limit优化
limit迁移量越大越费时,因为每条数据的实际存储长度不同,必须依次遍历。(即使定长,也会因为删除数据,导致索引上的排列就有gap)
select id,name,content from users order by id asc limit 0,20 很快
select id,name,content from users order by id asc limit 100000,20 很慢,扫描100020行
如果记录了上次的最大ID,可以优化为
select id,name,content from users where id>100073 order by id asc limit 20
扫描20行。
谢谢分享:
http://tech.meituan.com/mysql-index.html
http://student-lp.iteye.com/blog/2114128
http://www.jianshu.com/p/0124c0cb052c
https://www.jianshu.com/p/8a2ccdf4d32a
http://blog.codinglabs.org/articles/theory-of-mysql-index.html